APP下载
APP下载 登录
登录







计算机编程中栈是一个很重要的概念,尤其在汇编语言中,需要不断进栈和出栈的操作.栈是限定在一个表的尾端进行插入(进堆栈)和删除(出堆栈)的线性表.是后进先出结构(LIFO).
队列的定义和栈的定义是类似的,区别是数据是先进先出(FIFO)
labview还有一个概念缓冲区BUFFER,典型的比如CHART,它默认保存数据长度是1024.BUFFER的概念和队列是非常相似的,都是一个先进先出的结构.如果我们设定队列的数据长度也是1024.比较一下他们的区别.
区别一:未达到设定
开始的时候,队列和缓冲区中都是没有数据的,当有数据进入的时候,队列和缓冲区中的数据在不断地增加,对于缓冲区,因为未达到它最大许可的长度 1024,因此数据是不断第增加的,队列则不同,它的数据是否增加取决于是否有读队列的过程,就是所说的出队,如果出队的速度大于入队的速度,队列中则根本不会有数据.如果没有出队的过程或者出队的速度小于入队的过程,队列中的数据也是不断地增加的.这是第一个区别.
区别二:到达设定值
当队列和BUFFER都达到了1024个数据后,这是再有新的数据要进来,队列和BUFFER的表现是不同的,对于BUFFER,它将自动挤出(形象的说法,当然也是编程实现的)最早进入BUFFER的数据,所谓先进先出.而队列则不同.要求进入队列的线程只能被动等待,一直到队列中有别的线程取出数据,队列中有空闲位置.所以队列有调节读写速度线程的能力.
相同点一:数据进入都是在尾部,(队列插入如果在头部,就编程上面所说的栈了)
相同点二:对于中间数据都实现了有效的封装,你无法直接提取中间的某个数据,你可以读出中间的数据,但是不能改变当前BUFFER和队列的值.
LABVIEW提供的队列的功能函数(包括栈),在逐点分析库提供了DBL型的BUFFER,我在另外的日志中专门提到了,这里就不多说了.
LV队列的函数是基本函数,无法进行深入跟踪,估计应该是采用C++的算法然后封装的,我实际测试过,它的运行效率远高于用数组的方式构成的队列,为了详细说明队列和栈的细节,我还是用数组的形式,然后在介绍LV的队列函数.
首先看看如何用数组实现栈的功能:
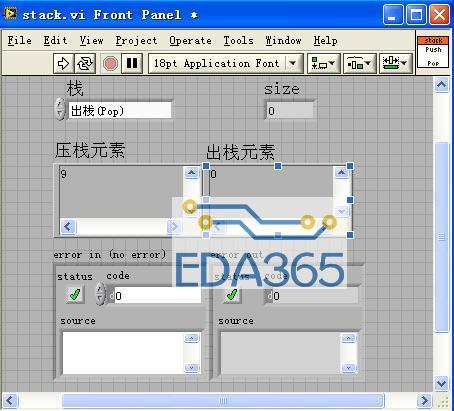
栈的操作是非常简单的,只有压栈和出栈两个操作(PUSH AND POP)
我们用AE来实现它.分成三个action: Init,Push ,Pop
首先严格自定义ENUM,表示三个动作.

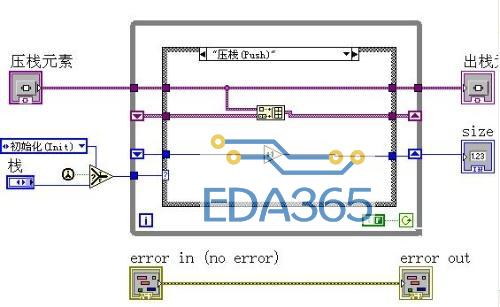
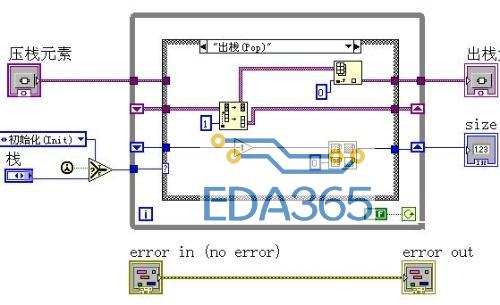
这样我们就完成了栈的AE的制作过程。
看看它的调用过程。
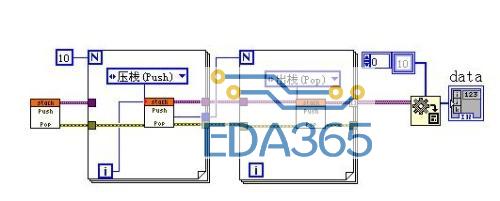
10次循环,栈中的数据应该是0,1,2,3,4,5,6,7,8,9。栈的弹出次序应该是9,8,7,6,5,4,3,2,1,0
运行结果确实如此。
与栈相反,队列是一个先入先出的数据结构,我们对栈的过程稍微修改一下,就可以得到队列。就不多介绍了。下面重点介绍一下LV提供的队列的具体功能。
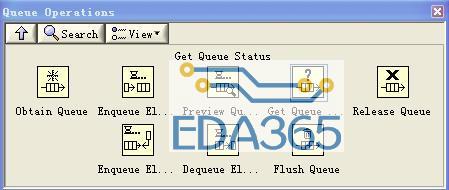
分别介绍这8个节点的具体功能:
1:获得队列(实际是得到队列的参考)它有5个数据端子
name:String
队列在LV系统中是名称来区分的,LV系统自己维护一个包含的目前所有队列的表,当你运行这个函数的时候,它首先会查找表中是否已经存在这个队列参考,如果存在,就直接返回这个参考,如果不存在,就建立一个新的队列,并将队列参考加入表中进行维护。这样做的好处是非常明显的,允许我们在任何子VI中,只需要知道队列的名称就可以运行这个函数直接得到队列参考,不用通过全局变量或者数据流输入来得到参考,在一个层层嵌套的VI中想传递一个数据很不容易,也不利于模块化。
max queue size:I32
定义的队列的最大长度,当输入-1时,队列长度不受限制,需要注意的是,如果取出数据的速度小于加入队列数据的速度,随着时间的推移,需要的内存会不断地增加,这显然是存在问题的,如果我们没有规定最大长度的话,编程时候要注意自己来协调速度。如果规定的最大长度,当达到最大长度时候,加入队列的线程会一直等待到队列中有空闲位置为止。








 热门文章
热门文章
系统-连载一")