×


人工神经网络(ANN)是一种从信息处理角度对人脑神经元网络进行抽象从而建立的某种简单模型,按不同的连接方式组成不同的网络。其在语音识别、计算机视觉和文本处理等方面取得的突破性成果。
神经元
在神经网络中,神经元是计算的基本单元,也被称为节点或单元。它接受其他节点或外部的输入,在计算后产生输出。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重(w)。该节点将一个函数f(定义如下)作用于输入的加权和,如下图所示
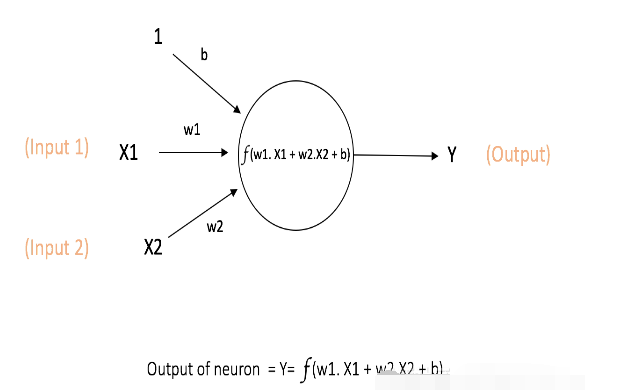
上述网络采用数值输入X1和X2、与输入相关联的权重w1和w2以及输入权重b(称为偏置)。稍后我们会介绍更多关于偏置的细节。
神经元输出Y的计算上图所示。函数f是非线性的,称为激活函数。它的作用是将非线性引入到神经元的输出中,以此达到神经元学习非线性表示的目的,满足实际环境的数据要求。
每个激活函数都取一个数并对它进行特定的运算。在实际应用中我们可能会遇到下面几种激活函数:
Sigmoid函数:σ(x)=1/(1+exp(−x))
tanh函数:tanh(x)=2σ(2x)−1
ReLU函数:f(x)=max(0,x)
下面是这几个激活函数的图像

偏差的重要性:如果没有偏置的话,我们所有的分割线都是经过原点的,但是现实问题并不会那么如我们所愿。都是能够是经过原点线性可分的。
前馈神经网络
前馈神经网络是第一个也是最简单的人工神经网络,各神经元从输入层开始,接收前一级输入,并输出到下一级,直至输出层。整个网络中无反馈,可用一个有向无环图表示。
前馈神经网络结构如下图所示
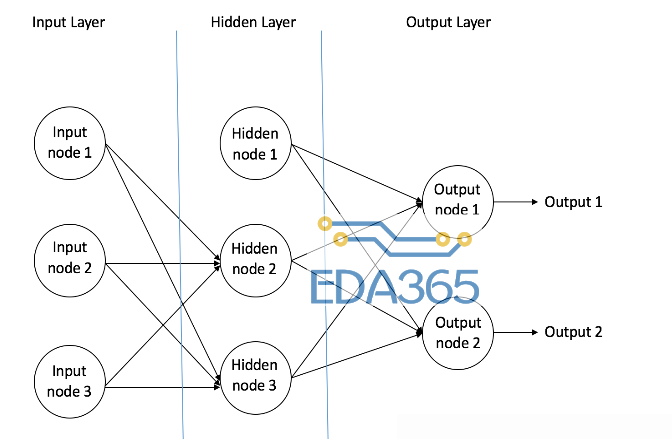
前馈神经网络由三种节点组成:
1.输入节点-输入阶段将来自外部的信息提供给网络,统称为“输入层”。任何输入节点都不执行计算,它们只是将信息传递给隐含阶段。
2.隐含节点-隐含节点与外界没有直接联系(因此名称为“隐含”)。他们执行计算并将信息从输入节点传输到输出节点。隐藏节点的集合形成“隐藏层”。虽然前馈网络只有一个输入层和一个输出层,但它可以没有或有多个隐藏层。
3.输出节点-输出节点统称为“输出层”,负责计算并将信息从网络传输到外部世界。
前馈网络的两个例子如下:
1.单层感知器-这是最简单的前馈神经网络,不包含任何隐藏层。
2.多层感知器-多层感知器具有一个或多个隐藏层。我们只讨论下面的多层感知器,因为它们比实际应用中的单层感知器更常用。
多层感知器
多层感知器(MLP)包含一个或多个隐藏层(除了一个输入层和一个输出层)。单层感知器只能学习线性函数,而多层感知器也可以学习非线性函数。
下图显示了具有单个隐藏层的多层感知器。需要注意的是,所有连接都有与之相关的权重,但图中只显示了三个权重(w0,w1,w2)。
输入层:输入层有三个节点。偏置节点的值为1,其他两个节点将X1和X2作为外部输入(数字值取决于输入数据集)。
如上所述,在输入层中不执行计算,所以来自输入层中的节点的输出分别是1,X1和X2,这些输入被馈送到隐藏层中。
隐藏层:隐藏层也有三个节点,其偏置节点的输出为1,隐藏层中另外两个节点的输出取决于输入层(1,X1,X2)的输出以及与其相关的权重。
下图显示了其中一个隐藏节点的输出计算。同样,可以计算其他隐藏节点的输出。然后,这些输出被反馈到输出层中的节点。
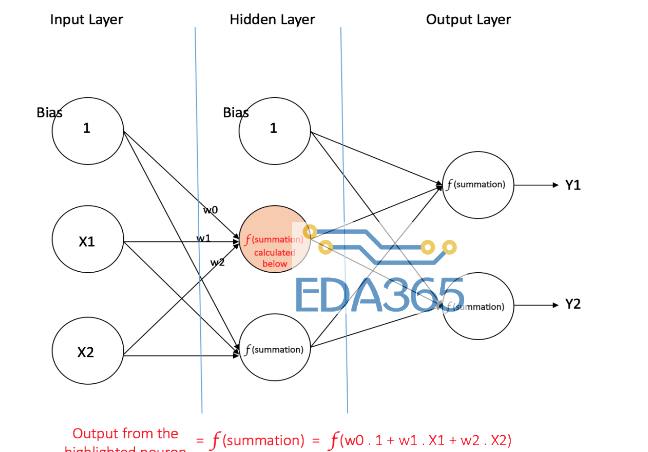
输出层:输出层有两个节点,它们从隐藏层获取输入,并执行与隐藏节点相似的计算。计算结果(Y1和Y2)将成为多层感知器的输出。
给定一组特征X=(x1,x2,。。。)和一个目标y,多层感知器可以学习特征和目标之间的关系,无论是分类还是回归。
我们举个例子来更好地理解多层感知器。假设我们有以下的学生标记数据集:

两个输入栏显示学生学习的小时数和学生获得的期中分数。最终结果栏可以有两个值1或0,表示学生是否通过了期末测试。例如,我们可以看到,如果学生学习了35个小时,并在期中获得了67分,他最终通过了期末测试。
现在假设我们想预测一个学习25小时,期中70分的学生是否能通过期末测试。

这是一个二元分类问题,其中多层感知器可以从给定的例子(训练数据)中学习,并给出一个新的数据点的预测。我们将在下面看到多层感知器如何学习这种关系。
训练我们的多层感知器
下图所示的多层感知器在输入层(除了偏置节点之外)有两个节点,它们采用输入“小时分析”和“期中标记”。它也有一个带有两个节点(除了偏置节点)的隐藏层。输出层也有两个节点-上层节点输出“通过”的概率,而下层节点输出“失败”的概率。
在分类任务中,我们通常使用Softmax函数作为多层感知器的输出层中的激活函数,以确保输出是确实存在的,并且它们概率相加为1。Softmax函数采用任意实值向量,并且将其化为一个在0和1之间的矢量,其总和为1。所以,在这种情况下
P(合格)+P(不合格)=1
第1步:向前传播
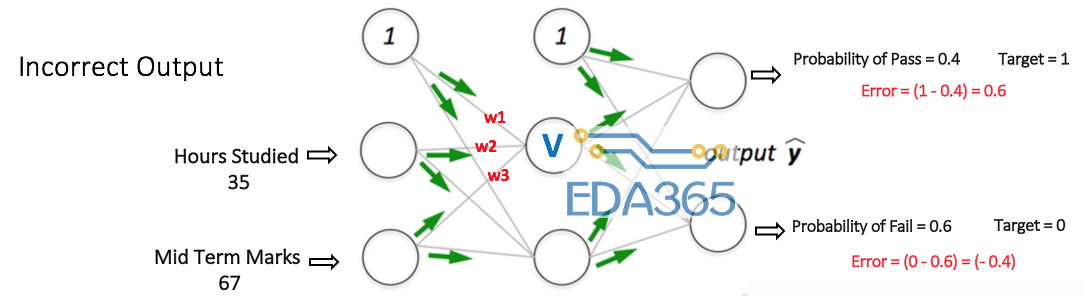
网络中的所有权重都是随机分配的。让我们考虑图中标记为V的隐藏层节点。假设从输入到该节点的连接的权重是w1,w2和w3(如图所示)。
然后网络将第一个训练样例作为输入(我们知道对于输入35和67,通过的概率是1)。
输入到网络=[35,67]
来自网络的期望输出(目标)=[1,0]
那么考虑节点的输出V可以计算如下(f是一个激活函数,如Sigmoid函数):
V=f(1*w1+35*w2+67*w3)
同样,也计算隐藏层中另一个节点的输出。隐藏层中两个节点的输出作为输出层中两个节点的输入。这使我们能够计算输出层中两个节点的输出概率。
假设输出层两个节点的输出概率分别为0.4和0.6(因为权重是随机分配的,所以输出也是随机的)。我们可以看到,计算的概率(0.4和0.6)与期望的概率(分别为1和0)相差很远,因此图中的网络被认为有“不正确的输出”。
第2步:向后传播和权重更新
我们计算输出节点处的总误差,并使用反向传播将这些误差返回网络以计算梯度。然后,我们使用一种优化方法诸如梯度下降,以减小输出层误差在网络中的权重。这将在下面的图中显示。
假设与所考虑的节点相关的新权重是w4,w5和w6(在反向传播和调整权重之后)。
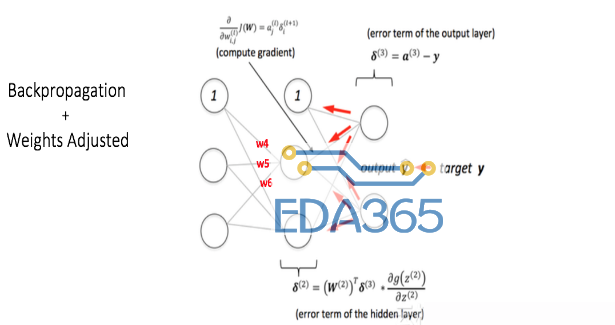
如果我们现在再次向网络输入相同的示例,则网络应该比以前执行得更好,因为权重现在已经被调整到最小化误差。如图所示,与之前的[0.6,-0.4]相比,输出节点的误差现在降低到[0.2,-0.2]。这意味着我们的神经网络已经学会了正确的分类我们的第一个训练样例。
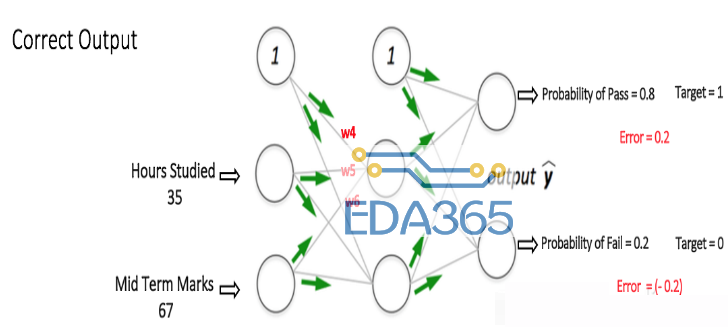
我们在数据集中重复这个过程和所有其他的训练样例。那么,神经网络将完全学会这些例子。
如果我们现在要预测一个学习25小时,期中有70分的学生是否能通过期末测试,我们就要经过前向传播步骤,找到通过和失败的概率。
多层感知器的三维可视化
AdamHarley创建了一个已经在手写数字的MNIST数据库上训练(使用反向传播)的多层感知器的三维可视化。
网络将784个数字像素值作为来自手写数字(其在输入层中具有对应于像素的784个节点)的28×28图像的输入。网络在第一个隐藏层有300个节点,第二个隐藏层有100个节点,输出层有10个节点(对应于10个数字)。
虽然这里描述的网络比前一节讨论的要大得多(使用更多的隐藏层和节点),但正向传播步骤和反向传播步骤中的所有计算都是按照相同的方式(在每个节点处)进行的之前。
较亮的颜色表示比其他更高的输出值的节点。在输入层中,亮节点是那些接收较高像素值作为输入的节点。在输出层中,唯一亮节点对应于数字5(它的输出概率为1,比输出概率为0的其他九个节点高)。这表明MLP已经正确分类输入的数字。我强烈推荐使用这个可视化例子来观察不同层次的节点之间的连接。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 关于AI的首次创业要注意什么
关于AI的首次创业要注意什么







 APP下载
APP下载 登录
登录







