×


1、引言
近年来,功能强大和密集型的数字信号处理器(DSP)已广应用于当前许多小型移动产品中,并成为必不可少的部分。
这些使用广泛的小型移动产品包括蜂窝电话、手持PDA 和GPS导航器等。对于此类微型产品的设计,要求DSP芯片必须具有极低功耗从而最大程度延长电池寿命和减小产品尺寸。
现代的高性能DSP芯片中或多或少采取了一些与通用处理器相同的低功耗设计,如对于DSP芯片的片内存储器,就有通过设计低功耗的存储单元,采用Divided-Word-L ine (DWL)译码设计等方法来降低DSP芯片的存储器部分的功耗。但是对于SoC而言,由于其总线上挂有很多设备,导致总线的电容负载很大。如果总线与片外设备联系,那么,它还要驱动很长的片外连线以及片外设备,负载高达50pF,比SoC内部各个节点的电容负载0. 05pF高出三个量级。一般而言, SoC总线的功耗占SoC总功耗的10% ~80%;一个已经对内部电路优化过的SoC,总线功耗约占50%。随着宽度的增加,总线消耗的功率占SoC总功率的比重越来越大,因此,总线的低功耗设计很重要。
然而现代的许多高性能DSP芯片在设计过程中,并没有考虑到这一问题,随着集成电路工艺的不断提升,如何降低总线功耗的问题已经越来越重要。在文献[ 1 ]中由Paul P. Sotiriadis和Anantha P. Chandrakasan提出的一个DSM总线的线间电容的模型下,人们已经对于降低总线功耗提出了一些编码算法和译码器,并且通过在采用RISC体系结构处理器的芯片上试验取得了较好的效果,其中比较有代表性的有Bus2Invert Code译码器、T0 Code译码器等。
(1)Bus2Invert Code译码器
定义总线的宽度是N, b ( t)为内核MCU计算出来的t时刻总线数据(即编码前的数据) , B ( t)是t时刻已放到总线上的数据(即编码后的数据) , J ( t)是解码器解码后的数据, H ( t)是指b ( t)和b ( t-1)的Hamming Distance。总线传输数据时,相邻两次读取的数据都是确定的,因此可以确定两次数据b ( t)和b ( t-1)的Hamming Distance,如果2 ×H ( t) >N ,这说明总线上有超过一半的信号需要翻转,这时如果将第二次传输的数据逐位取反再传输,就可以减少信号翻转的次数。这种译码器适用于数据总线,可以在数据总线上传输随机数据时大幅降低的功耗,但是对于随机性不强的地址总线的优化并不明显。
(2) T0 Code译码器
T0 译码器的原理在于尽可能地减少总线的翻转次数,由于指令总线上的地址在多数情况下都是以相同的增量增加(在没有跳转等情况下PC = PC +N。这里N 是一个定值) ,因此规定当两个相邻的数据的差为N 时,总线上的数据不变化,只有当不为N 时才传输新的数据。如果在设计中采用T0编码的译码器和解码器,那么则在下面这种情况下可以达到最低的功耗:如果数据流中的数据都是以同样的间隔的无限序列,T0 编码可以使得在总线上传输这些数据时,总线上没有出现翻转。译码器则对于有规律性变化的地址总线的优化非常显著,而对随机性较大的数据总线的功耗降低没有什么帮助。
由于DSP处理器与通用处理器的体系结构的差异,决定了一些适用于通用处理器的方法并不一定适用于DSP处理器,以上的方法还未应用在DSP处理器中。
然而DSP处理器的独特构造也为DSP处理器的低功耗总线设计提供了条件:DSP处理器执行的程序中需要执行大量的乘加运算来实现DSP算法,需要独立的地址生成器生成大量有相同间隔的连续地址,从而极其利于类似T0的编码算法对其优化;而DSP处理器处理的数据大多为随机性非常强的随机数列,可以发挥Bus-Invert Code译码器的作用。
2、总线模型
在芯片的制造技术到达了深亚微米级(DSM)时,总线功耗已经成为一个重要的问题,总线功耗的降低对于芯片整体的功耗降低已经越来越重要,因此在DSM下建立一个合理的总线模型是首先要解决的问题。
图1是在文献[ 1 ] 中由Paul P. SoTIriadis和Anantha P. Chandrakasan提出的一个DSM总线的线间电容的模型。从图1可以看出,当工艺水平达到深亚微米级时,总线模型已经与以往的模型发生了较大的变化,我们必须细致的考虑线间的电感效应,因此,图1模型具有较好的说明性。实际中,用到的是如图2所示经过简化的模型。
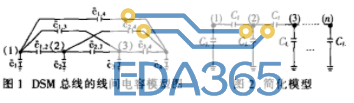
用式(1)和式(2)表示在不同时刻第i根总线上的电压:
其中T表示总线上的时钟周期,Vinew表示第i根总线上的电压(0或者是Vdd ) ,Vi ( x, t)表示t时刻上第i根总线上的电压值,而当一根总线的电压发生变化时,其消耗的能量可以计算出为 Ei=∫T 0VddIi( x)dx,
而全部n根总线上的消耗的功耗为E = ∑Ei ,由此可以用矩阵的写法式(3)和式(4)来表示
从式(6)可以明显地发现, 如果想降低总线上的功耗,主要的方法就是使总线上传递数据时,在两次传输的数据过程中,尽量减少总线的翻转次数。因此,在降低总线功耗的编码方法中,就是通过编码的方式进行优化,使得当传输相同的数据时,经过优化的总线上的翻转次数减少,从而降低总线上的功耗。
3、最小海明距离编码的设计思路
现代的高性能DSP芯片中也或多或少采取了一些与通用处理器相同的低功耗设计,如对于DSP芯片的片内存储器就有通过设计低功耗的存储单元, 采用Divided-Word-L ine(DWL)译码设计等方法来降低DSP芯片的存储器部分的功耗,而由于DSP芯片的特殊性,我们可以采用一些特有的低功耗设计:DSP芯片支持的常用算法有FFT, F IR等,都需要大量乘加运算,因此DSP芯片中有一个独特的部件地址生成器来提高数据的地址生成速度,而生成的地址通常为具有固定步长的地址。
在总线上传输的数据也经常出现具有固定步长地址序列,那么可以利用这一特点对其加以优化。而乘加运算中的数据是一个随机的序列,需要用特殊的译码器来解决。对于超哈佛总线结构的DSP芯片的低功耗总线设计,则要综合考虑这两方面的需求。
现在已经提出的一些译码器和编码算法都只是从一方面进行优化,如Bus-Invert Code对于降低随机序列的功耗比较有效,但是对于顺序序列的效果并不明显; T0 Code由于需要增加一个信号参加译码器的译码,因此使译码器的硬件设计更为复杂,而且对于时序的控制比较困难。如果能找到一种合适的方法兼顾到各种不同的需要,就可以应用在DSP芯片的总线设计中并达到降低总线功耗的作用。
首先,我们需要从编码的角度看,设计出一种新的编码算法,从而在不增加任何硬件开销的情况下,通过采用改进的编码器来降低总线上的功耗;然后,再选取一种低功耗译码器,使它能弥补编码算法的不足,从而进一步降低功耗。
需要注意的是,两种译码器不能是基于同一原理,否则两者的结合无法互相弥补彼此的不足,其效果与单独使用一种方法无本质区别。我们不采用T0编码器的原因在于,它只针对间隔固定的序列有效,由于这个间隔是一个确定的值,所以不是很灵活,而最小海明距离编码算法则比它灵活一些。
4、最小海明距离编码算法
(1)局部化原理
局部化原理分为时间局部性原理和空间局部性原理。我们根据计算机的空间局部性原理,也就是说由于在相对较短的一段时间内,处理器会重复访问相对集中的一部分数据,因此在总线上传输的数据有这样一个特点:总线上传输的地址具有一定的连续性,也就是说,在一段时间内,总线上的数据具有连续性(如0000, 0001, 0010, 0011, .) 。随着多媒体技术和DSP技术的广泛应用,现代高速处理器更是具有这样的特点,在大部分数字处理算法中,需要进行大量的乘加运算,通常这些数据都是存放在连续地址的存储器内,对此加以利用,就可以找到一些方法来降低总线的功耗。
(2) 算法目标
通过一个合理的编码方案,尽可能地减少当有相同间隔的连续地址在总线上传输时总线上的翻转,从而达到降低总线功耗的目的。
(3) 编码算法数学模型
由于在前面已经确定了算法的目的,因此建立了一个取得编码的数学模型。算法的中心思想在于:将对于连续地址(更广泛地说是指固定步长)的两个码字的编码采取变化,使得在总线上传输的两个相邻的数据之间的海明距离变小,从而减少总线的翻转次数。因此,可以将对于任意间隔固定步长两个码字的海明距离降到最低,即为1。
定义一个无向图G,定义总线宽度是N,总线上可能出现的所有的数据则有2N个,将其命名为M ( 1 ) , M ( 2 ) ,M(2N )作为图的2N 个节点,当且仅当两个节点M ( s)和M ( t(0 < s, t < 2N + 1)所对应的编码的海明距离为1时,存在一条无向边连接这两个节点,这样就构成了一个无向图,因此,我们的目标就是在这个无向图中找到一个Hamilton圈,使得所有连续地址的编码顺次在这条轨上出现,从而当总线上顺次出现连续地址时,总线翻转减少。
也就是说,我们需要在一个有2个节点的无向图中找到一个Hamilton圈,然后将地址依次对应到每个节点上。在一个有n个节点的无向图中搜索一个Hamilton圈本来是一个NP问题但是,由于这里n = 2N ,并且两个节点之间的连接关系有一定的特殊性,因此,在这样一个特定条件下在O ( n)的复杂度内完全可以实现。
5 、算法及其证明
(1)构造算法
①首先构造一个地址为两位的排列,如图3所示。两位地址构造,圆圈代表编码,只有海明距离为1的点之间才有连线。
②当n = k时成立,利用n = k的编码序列作为基础,构造n = k + 1的编码序列。
注意:由于当我们构造一个n = k + 1情况下的编码时,是利用一个已经完成的n = k的编码,因此当选用不同的n = k的编码,所得到的n = k + 1的编码也是不同的。
(2)证明。在这里,采用归纳的方法来证明算法的正确性
①在N = 2的情况下,可以很容易找到一个解(图4) 。
②当N = K有解时,由于K≥2,因此,在N = K的Hamilton圈中至少有一条边可以满足扩展时的需要。由构造的方法可知,可以将N = K + 1情况下所有的点包含,因此,这样构造出的Hamilton圈是符合我们要求的。
③同时,我们可以通过在扩展时选用不同的边,可以构造出所有满足要求的Hamilton圈。可见,在总线编码这种特殊的模型下,在图中搜索到一条Hamilton圈是可行的。
6、设计的实现及硬件译码器的选择
(1)设计的实现方法
在具体的实现上,我们采用将编码算法固化的方法来实现这一方案。在DSP芯片的地址产生器的输出端增加一个译码器,通过译码器对程序产生的地址进行一次映射,由于这种映射是一一对应的映射,因此对于程序员编写程序没有任何影响;存储器的设计人员也不需要考虑译码器的问题,只需要采用Bus-Invert Code译码器代替通常采用的译码器。
这样就可以兼顾两者的优点:当总线上传输的地址是连续地址时,地址译码器输出的地址码是一个海明距离很小的序列,可以减少总线的翻转次数;当总线上传输的地址不是连续地址时,也就是说是一个较为随机的序列,如果两个数据之间的海明距离比较大时,Bus-Invert Code电路就可以发挥作用,使海明距离大于总线宽度一半的编码序列,从而降低总线传输的功耗。
(2)举例
以一个0~16的序列在总线上传输为例,左边一列是常规方法的译码结果,右边一列为采用新方法的结果。
通过本例可以很明显地看出当总线上的数据出现连续序列时,可以大大降低总线上的翻转次数,从而降低总线功耗。
7 、实验结果
首先取得总线模型翻转时在Hspice上的仿真结果。
图5中显示的是总线在翻转时电流的变化图,我们可以清晰地看出当总线翻转时电流的变化非常大,而图6则显示的是总线在翻转时电压的变化图,通过这两幅图可以得出结论,总线翻转时的功耗远大于保持原状态所需的功耗,因此通过减少翻转的方法降低总线功耗是一个有效的途径。通过在公司的ls0201DSP芯片上的仿真测试,得到如表1的结果。
从表1可以看出,对于新的设计方案降低总线的功耗是有效的。其中,编码算法对于地址译码器的数据线的优化最为突出,这是由于DSP芯片自身的特点造成的。DSP处理器执行的程序中需要执行大量的乘加运算,需要独立的地址生成器生成大量的连续地址,从而极利于编码算法对其优化。因此,可以说新的设计方案对于全面降低DSP芯片内总线的功耗是有效的。
表1 模拟仿真结果
8、结论
DSP芯片,需要综合考虑总线上传输指令地址和数据两种情况,新方案兼顾了两种编码器的优点。针对超哈佛总线结构的DSP芯片的特点,利用编码算法对指令地址的传输情况进行优化,并用硬件上Bus2Invert Code对数据传输情况进行改良。试验结果证明新方案对于降低超哈佛总线结构的DSP芯片总线功耗是十分有效的;而在既传输数据又传输指令的普林斯顿总线上,新方案在传输指令和传输数据两种情况下都可以降低总线功耗,达到了试验的目的,证明通过多种编码器来降低DSM总线上的功耗是一种可行的办法。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 UClinux2.4.x+S3C4510B平台的USB-HOST驱动设计
UClinux2.4.x+S3C4510B平台的USB-HOST驱动设计








 APP下载
APP下载 登录
登录







