×


摘要:在分析传统DMA控制器结构的基础上,针对实时图象处理系统的数据传输要求,提出了多端口模块设计、增加RoundRobin通道优先级仲裁算法和优化数据传输通道等优化方法,以提高数据传输速度,并改进了地址产生模式来满足图像算法的要求。
数字图像处理是嵌入式系统最为广泛的应用之一。目前,数字图像处理技术无论在科学研究、工业生产或管理部门中都得到越来越多的应用。而目标跟踪、机器人导航、自动驾驶、交通监视等应用也极大地促进了实时图像处理技术的发展。
数字图像处理的特点是数据量大、运算复杂、实时性强。通常,数据量往往大于片内的存储容量,对于片内存储资源有限的处理系统来说,一般需要借用外部存储空间。为了提高系统的实时处理能力,必须在片内高速存储区和外部存储空间之间使用直接存储方式(DMA)进行数据交换,从而使处理器只专注于数据的计算。
DMA控制器一般具有如下功能:在不同的存储介质之间实现快速数据传输;独立于处理器进行高速数据交换;提供多个DMA通道以提高数据传输的并行度;支持数据爆发传输模式;具有通道优先级可编程的仲裁机制。
图1是DMA控制器的模块框图。从图中可以看出,DMA控制器主要由以下几个模块组成:
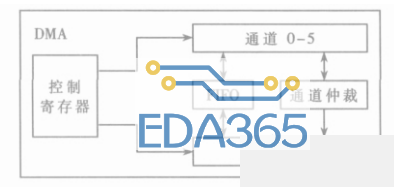
图1DMA控制器的模块图
(1)寄存器控制模块:为软件程序员提供可编程接口,以控制DMA的工作状态;根据各配置位的不同设置,控制各DMA通道和各端口的工作状态。
(2)通道控制模块:DMA控制器中有6个可以独立工作的DMA通道,根据相应控制寄存器的配置位提出DMA申请,通过端口模块访问存储介质。
(3)端口控制模块:它是DMA控制器与存储介质之间的接口模块,提供访问存储介质的地址、数据和控制信号线。
(4)FIFO控制模块:DMA控制器中共有6个32字节的缓存队列,分别为每个通道所占用,在爆发式的传输中,可以缓存慢速存储设备中的数据,从而提高DMA控制器的传输速度。
(5)通道优先级仲裁模块:当多个DMA通道同时提出DMA申请时,需要进行通道的优先级仲裁,在这里使用硬件优先级仲裁。
此外,还有中断和事件响应模块,用以保证DMA的实时传输。
首先,在传统的DMA设计中,端口模块只采用一组数据线、地址线和控制线,连接DMA需要连接的所有存储介质;并且当多个通道需要同时占用数据线、地址线和控制线时,只采用硬件优先级仲裁的方式来处理。这样,对于大量DMA应用的实时图像处理系统,DMA的传输效率并不高,影响了整个系统的图像处理效果。所以,需要对DMA的端口模块和优先级仲裁模块做一些改进,以便有效地改善DMA的数据传输速率。而且,DMA的数据传输路径也可以改进。
其次,图像数据本身的一些格式特点和所要求的图像处理算法决定了一个实时图像处理系统中的数据传输并不是一种简单的数据传输,而是要求DMA的数据传输同时具有矩阵传输、翻转传输等功能,来加快图像处理的速度和满足一些图像处理算法的要求。而普通DMA的地址产生模块并没有这样的设计。
本文实现的DMA控制器中,DMA控制器支持多端口模式,可以在各个存储介质之间进行数据的并行传输。通过增加一些硬件复杂度,大大提高了系统数据传输的并行度。

图2多端口模块的连接图
图2为DMA控制器的端口模块连接图。DMA控制器通过4个端口连接内部存储器、外部存储器和外部设备。通道和端口相互独立,每个通道可以独立申请占用端口资源。端口将各个通道产生的控制、地址和数据信号通过多路选择连接到端口对应的存储介质。当多个通道同时收到DMA请求时,如果所访问的端口不冲突,则每个通道可以各自独立地通过所访问的端口资源进行DMA传输,从而提高DMA数据传输的效率。
如果考虑通道对端口的访问可能产生冲突,则需要引入通道优先级仲裁的设计。在实际的系统应用中,每个DMA通道的请求对实时性要求是不同的。因此,通常的DMA控制器中都集成有通道硬件优先级的设计[1,2],有效地为各DMA通道的资源请求服务。对实时性要求较高的DMA通道请求,将通道优先级设为最高,而对数据量大且实时性无特殊要求的DMA通道请求,将通道优先级设为最低。优先级高的通道优先占用端口资源。但是这样简单的设计,只是让各个通道去排队占用端口资源,在通道优先级相同的情况下,需要等到一个通道的所有数据传输结束后,下一个通道才能占用端口资源,这使整个系统的处理效率降低。
引入相同优先级的通道,能够分时共享端口资源,本文采用Round-Robin策略实现这种分时共享机制[4]。端口对于相同优先级的通道请求,根据Round-Robin仲裁算法,轮流响应各个DMA通道的传输请求,让相同优先级的通道可以分时工作,避免某个通道占用端口资源时间过长,以提高系统的传输效率。
图3为DMA通道优先级的仲裁策略。每个通道的优先级由控制寄存器的相应位设定。通道的请求信号为chanx_req,根据通道的优先级产生高优先级请求信号cx_req_h和低优先级请求信号cx_req_l。
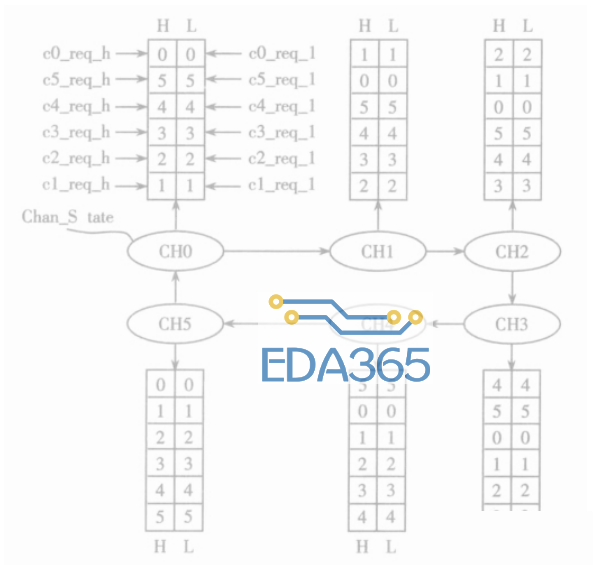
图3DMA通道优先级仲裁策略
优先级仲裁模块的通道轮询机制使用状态机实现。状态机共有6个状态,分别为选中通道0~5的状态。每个状态都包含一个通道优先级的排序队列。各个通道根据高优先级请求信号cx_req_h和低优先级请求信号cx_req_l进入通道优先级排序队列的相应位置,从高到低排序。没有请求的通道不参加排序。例如通道0、2、4有cx_req_h,通道1、3有cx_req_l,通道5没有请求信号。若当前状态为选中通道0,排序的结果为2-4-0-1-3;若当前状态为选中通道2,排序的结果为4-0-2-3-1。
状态机在当前正在进行的数据传输结束后,根据当前通道的优先级排序队列进行优先级仲裁,跳转到通道优先级排序队列中排队最靠前的通道所对应的状态,从而产生选中通道的选中信号。
从图3中可以看出,不同状态的通道优先级排序队列可以保证状态机的跳转按一个硬件优先级加轮询的方式进行。
通过这样的方式,就可以让多个需要访问同一端口的通道分时共享端口资源,从而提高整个系统数据传输的并行度。#p#
#e#
DMA通道的数据传输分为单个传输和爆发传输两种类型。
在通常的DMA控制器设计中,每个通道通过一个FIFO缓存读入数据。在读访问阶段,数据从源端口传输到通道的FIFO中;在写访问阶段,数据从通道的FIFO传输到目的端口。这样,当端口连接的存储介质为慢速设备时,可以大大提高DMA通道的传输速度。但是当通道的传输类型为单个传输时,如果传输的数据还要经过FIFO缓存,则每个数据单元的传输至少浪费1个时钟周期,因此对数据通路要进行适当的优化。
DMA数据传输的路径如图4所示。当传输类型为单个传输时,增加一个数据单元的前向反馈路径,数据不必经过FIFO缓存,从源端口读到后,直接写入目的端口中,可以减少1个时钟周期的传输延迟。
图4DMA数据传输的路径
在很多实时图像处理系统的应用中(如子图抽取和图像翻转等应用),DMA通道的数据传输并不是简单的地址递增、递减或不变传输,而是要求DMA通道以一些特殊的地址增长模式进行传输,如图5(a)所示的矩阵传输和图5(b)所示的翻转传输。

图5DMA通道的矩阵传输和翻转传输
当DMA数据传输只是连续地址(memory)或是不变地址(外设的FIFO)的数据传输时,只需要有一种地址调整方式,即基本调整方式。基本调整方式是指地址根据数据字长和通道控制寄存器的相应位来选择连续递增、连续递减或不变的方式[2]。而这种方式不支持传输数据源地址和目的地址不连续或不变的情况(如图5所示)。用软件编程实现这些功能,会浪费大量的CPU时间。
本文设计的DMA控制器引入了二维数据传输的思想。为了支持矩阵传输和翻转传输功能,需要增加另外一种地址调整方式——索引调整方式。另外需增加四个寄存器:帧计数寄存器、单元计数寄存器、单元索引寄存器和帧索引寄存器。并在通道的控制寄存器中增加指示地址模式的mode位(包括递增、递减、不变和索引)。索引调整方式的计算过程如图6所示。将传输的数据分成二维,一次传输的总数据块由若干个帧组成,而每个传输帧又由多个数据单元构成,每个数据单元根据控制寄存器中的数据字长可以是字节、字或是长字。相应的传输计数寄存器也有两个,即帧计数寄存器和单元计数寄存器。与基本调整方式不同,索引调整方式可以根据传输的数据单元是否是当前帧的最后一个数据单元进行不同的地址调整。单元索引寄存器中存放普通调整值,帧索引寄存器中存放帧尾调整值。每一帧除了最后一次数据传输以外,其余的传输都由单元索引决定地址寄存器的增量。如果读写的是该帧的最后一个数据单元,则用帧索引做地址调整。当帧计数寄存器和单元计数寄存器都为0时,DMA传输结束。
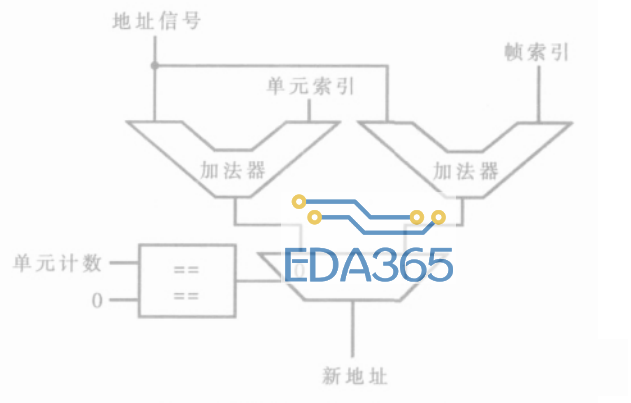
图6地址索引计算方式的实现
虽然这样的改进不会提高DMA数据的传输速率,但是可以节省整个系统的时间。如果通过软件的方式完成矩阵传输和翻转传输等功能要求,需要执行额外的CPU运算时间。现通过设置通道寄存器,可以在DMA传输的同时,完成矩阵地址计算和翻转地址计算等功能要求,并且不占用额外的CPU时间,提高了整个系统的效率。#p#
#e#
为了验证DMA的设计是否能满足实时图像系统的高速实时要求,是否能在数据传输的同时完成子图抽取功能,搭建了一个运动小目标检测系统,系统的框架见图7。在此系统中,对DMA设计的有效性进行测试。
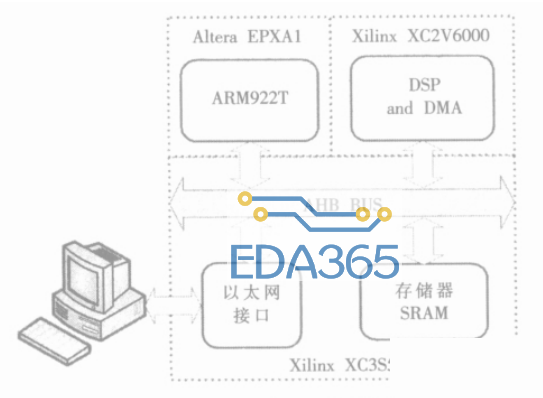
图7小目标检测系统的框架
小目标检测系统是一个双核系统。ARM922T是主处理器,负责整个系统的控制及与外界的数据交互。DSPCORE是协处理器,负责运动小目标检测算法的运算。整个系统的工作流程:PC机将采集到的352×288的运动小目标灰度图数据通过100M网线传送到以太网接口模块,ARM922T将输入的数据存放到片外的存储器SRAM,并通知DSP进行数据处理和传输。DSP数据处理时采用片内双缓存机制,一块缓存数据的运算可以部分或全部与另一块缓存的数据在DMA传输过程中并行,并由DMA的事件触发功能和中断反馈功能保证数据运算和数据传输过程的并行。最后小目标检测算法检测出来的小目标的坐标值(行和列)反馈到PC机,在PC机上演示源图像和结果图像。
目前,各模块的RTL设计和基于双核系统的前端验证均已完成,并且已经将此双核系统成功地移植到FPGA平台上。此平台的核心单元由Xilinx的virtexⅡ6000(X2V6000)、spartanⅢ5000(X3S5000)和Altera的EPXA1(内含ARM922T硬核)构成。多FPGA互联带来的庞大的可编程逻辑及EPXA1内置的ARMCore能真实地模拟双核系统环境。
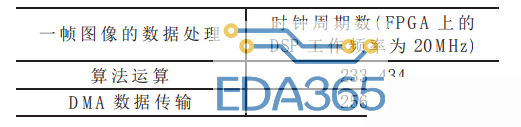
在PC机显示界面上的实时显示速度为25帧/秒,图像的视觉效果比较理想。在一帧352×288的灰度图像的处理过程中,从算法运算的时钟周期数和DMA数据传输所耗费的时钟周期数对比来看(见表1),DMA的数据传输和DSPCORE的算法运算几乎可以完全并行,充分发挥了DSP的核心运算功能。由于此次应用的小目标检测算法并不是一个运算非常复杂的算法,因此可以说明DMA的传输速率达到了实时系统的要求。同时,DSP中运行的小目标检测算法是基于背景比对的灰度图算法,每次处理的图像范围是7×7的一个子图,在DMA传输的同时进行子图的抽取功能也得到了验证。实践证明:本文提出的DMA设计结构在实际的图像处理系统中完全可以达到高速实时要求,并且可以在传输的同时满足子图抽取等图像算法的要求。
表1算法运算和DMA数据传输的时钟周期数
本文基于实时图像处理系统对DMA的需求分析,提出了适用于实时图像处理系统中的DMA接口模块和数据传输路径的设计与优化,并针对子图抽取等图像算法需求改进了地址产生模块的设计结构。从FPGA上的验证结果来看,此DMA设计具有高速实时性能,同时也能满足图像算法的子图抽取等需求,完全适用于实时图像处理系统的应用。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 scsi接口
scsi接口






 APP下载
APP下载 登录
登录







