
如何在增加存储带宽以适应各种新兴应用需要的同时又将尺寸降至最小和将成本降至最低,这是横亘在手机制造商面前的一道难题。面向视频、音乐、导航和联网等多种应用的最新功能型手机要求高达数千兆位(Gb)的存储带宽,这比现今已有的手机高出一大截。因此,需要一种更好的存储器控制器接口,以此支持未来手机的需求。
举例来说,一个分辨率为1,280×1,024、刷新频率为60Hz的24位(RGB)彩色编码LCD就需要1.5Gbps的存储器缓冲器读/写总带宽,而总的存储器带宽则高达3.7Gbps。该带宽用来驱动外置显示器的常规分辨率,但渲染及其它功能则不在其内。将手机显示器与目前计算机的图形系统相比较并不过分,因为移动电话也和计算机一样集成了千兆赫兹(GHz)的处理器和DDR DRAM主存储器。这些系统都需要80至400Gbps的存储器带宽。
在一款集成了两个处理器内核(一个用于基带处理,另一个用于应用程序处理)的典型高端手机中,两个处理器均需要以非易失性(Flash)存储器来存放代码,以易失性存储器(SRAM和DRAM)作为处理数据时的临时缓存器。
当应用程序处理器执行用户可载入的多媒体应用程序时,需要大量快速存取存储器。然而,这种速度需求超过了现有最快闪存的存取速度的数倍。为实现这类性能,可以用价格较为低廉的NAND或MirrorBit ORNAND闪存来存放应用代码,然后将其复制到更快的DARM中来执行。因此,应用程序处理器一般需要NAND或ORNAND和DRAM存储器。
相对而言,基带处理器要执行深层的嵌入协议堆栈。这类代码最理想的是闪存直接执行(即片内直接执行,或缩写为XIP),并且需要对闪存进行随机存取。只有NOR闪存支持高效的XIP模式,故通常选择NOR存储器来存放基带代码。DRAM能够作为基带处理的临时缓冲器被应用程序处理器共享,或者是NOR存储器可与专用于支持基带处理的SRAM或pSARM结合使用。
集成如此多种类的存储器通常需要超过100个引脚专门作为存储器接口,而这一数量占据了整个手机CPU引脚总数的大约30%。德州仪器的OMAP 1611和意法半导体的Nomadik宏架构就是含有大量连接存储器的引脚的高性能CPU的代表。
而随着用户对诸如LAN连接、GPS功能和移动电视(TV-on-mobile)等新型手机功能的需求,OEM们面临着更大的挑战。上述性能需要更强的处理能力,进而需要更大的内存带宽来支持这种处理能力。这就意味着必须增加引脚的数量以支持增强的数据处理能力。目前的系统内存已占用了整个CPU很大一部分引脚数量,若要再增加引脚就会带来种种问题和技术挑战:
* 每个引脚都会为手机CPU直接增加0.4美分的成本,进而导致信号和相关电源/地引脚的总体成本提高60美分。
* 减少引脚数量可以缩小封装体积、降低其成本。
* 对于焊盘有限的设计而言,I/O数量的减少可直接降低裸片成本。
* 采用大量引脚的CPU需要更多层的电路板用于信号走线,这样将增加系统的成本。
* 通过通孔连接多层板的布线方式会引起噪声问题。
* 为容纳更多的引脚就需要更大的面积,但这样做又与手机小型化、超薄化的趋势背道而驰。
单纯地暂不集成这些先进功能,而是等待开发出更快速的存储器解决方案,这种做法显然并非上策。虽然扩展存储器总线接口在技术上具有可能性,但由于增加了CPU上业已庞大的引脚数目,这种方法并不合理。因而存储器总线必须向着有利于DRAM性能的方向发展,同时寻找能够支持频率变化并减少引脚数量的新的I/O技术。考虑到围绕存储器系统而构建的众多基础架构,想要从根本上改变内存总线是相当困难的。
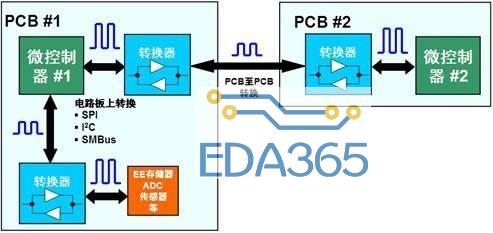
图1: 存储器件可以共享客户端和主机之间的总线
图2: 存储控制器接口链接系统总线和存储器件
解决方案概述
存储器控制器包含了两个接口。主机接口将控制器与系统总线相连,存储器接口则将控制器与存储器件相连。两个接口分别工作在各自的时钟域中,并通常具有独立的先入先出(FIFO)队列。这就使得存储器控制器可以通过以高速、少引脚数量的总线来替换队列,从而很容易地重新分区为主机接口和存储器接口。 [page]
以这种方式对存储器系统进行重新分配,为主机和存储器系统之间提供了一条统一总线,同时考虑到了密度、存储器类型以及速度级等性能指标。此外,该方法还最小化了外部总线的负荷,因而允许更高的总线频率,这是减少引脚数量的预备条件。而且,重新分区也同时把存储器件之间大量引脚的接口限制为典型多芯片封装(MCP)内部的一种解决方案,这降低了手机成本,并允许在MCP中容纳更多的存储模块(Memory Bank)。
主机与存储器系统之间采用统一总线,可尽量减轻外部总线的负荷。主机接口与客户机接口之间的总线以DDR存储器总线来实现,因此作为实例存储器系统的总体外部引脚数量在35至43之间(控制总线:15个引脚,地址总线:12个引脚,数据总线:8到16个引脚) 。
根据时钟频率的不同,以上所给出的系统划分可使外部存储器带宽仅以43个引脚就达到10Gbps,因而可将外部引脚数目减少约60%,同时大大增强性能。此外,由于引脚数量的减少,单个CPU的成本也随之降低。最为重要的是,这种方法将存储器与总线各自独立开来,从而能够建立起分层的存储器-系统架构,甚至允许以一种对存储器透明的模式把总线移植到超高速的差分结构中。基于这种方式,存储器件可以开发成直接与总线相连,或是可开发成经重配置总线接口之后再与总线连接的结构。
客户机接口与主机接口之间的总线可以被所有存储器件共享,虽然目前的系统中通常只有静态存储器(NOR、SRAM和NAND)共享一条总线。因此必须谨慎设计系统以避免延迟问题,尤其是对DRAM存储器而言,这个问题对系统的整体性能影响最大。
延迟问题
只有当处理单倍数据率(SDR)器件时,延迟问题才能得到解决。在这种情况下,静态存储器可以和动态SDR多路复用,即在每半个时钟周期中利用工作在双倍数据率(DDR)模式下的总线使一种存储器工作。通过访问传统存储子系统和重新分区的子系统的存储器,再对二者在时序上的区别进行比较可以看到,后者能够避免延迟带来的影响。
大部分逻辑操作都发生时钟沿(通常是上升沿)。主机控制器在上升沿创建信号,该信号在下一个上升沿时在迭置焊接层(registered pad layer)被捕获。如果这种重新分区的存储器系统如同惯有的那样在上升沿的同时输出信号,就不存在延迟问题。
在重新分区的结构中,控制器在上升沿建立信号,焊接层(Pad Layer)在下一个下降沿捕获信号。客户机控制器在下一个上升沿将信号输出,因此存储器件在存储接口上得到相同的时序。
建立的系统时序在一个时钟周期内很可能无法避免延迟,但在大多数情况下,延迟损失是可以预防的。为弥补这种不能避免的相对较小的延迟,可以增加预取(prefetch)功能。在存取数据n的期间,可以自动读取数据n+1,这样,延迟问题实际上就得到了改善。
在存储子系统内部采用预取技术(prefetching)的结果是带宽随延迟的改善平均增加15%。这对于可能需要大量预取的随机数据和DSP操作是正确的。预取并不会引起性能的降低,但如果预取的数据并非在放回预取缓存器中之前CPU所需的,则会导致功率的浪费。实现预取方案的逻辑相当直接简单。预取缓存器可以在客户机总线接口中实现以避免使用用户存储器。
对带宽的影响
对于存储器系统而言,恒定带宽(sustained bandwidth)是一个关键参数。如上所述,引入重新分区存储控制器的客户机接口会增加存储器访问的延迟,而延迟对对恒定带宽有很大影响。
由于恒定带宽是评价存储器系统性能的一个关键指标,就必须考虑慢速和快速存储器如何在同一条总线上操作的问题。恒定带宽是最小的总线和器件带宽。较慢的闪存(Flash)存储器工作频率最高为100MHz,需要大得多的容量。相对于DRAM,对闪存的访问很少,因此,如果能够通过在DRAM中临时缓存高峰数据流并使进出Flash的流量更加恒定,则较慢的恒定带宽是可以接受的。若宽度W的Nburst是可变的,则恒定带宽可表示为:
BWsust=W×Nburst/(tini+Nburst–1)×twords/s
峰值带宽可表示为:
BWpeak=W/twords/s
许多手机应用如录音和照相,都证明“突发”活动并不总是需要匹配目标存储器带宽与峰值应用带宽。在那种情况下,对临时缓冲器的管理非常关键,因为它占用了更长的时间在后台复制数据,同时也为CPU提供了临时的数据存储空间。重新分区的存储器系统允许采用双端口(端口A和端口B)的RAM进行后台复制,其中端口A覆盖的存储范围为Ma,端口B覆盖了剩余的存储范围Mb。M、Ma以及Mb之间的关系为:通过寄存器写入可以完成存储器范围Ma和Mb的重新配置,因而Ma变成Ma prime,而Mb变为Mb prime:
Mailbox表示存储器的空间,一次指派给端口A,一次指派给端口B。从A到B重新指派Mailbox可以拷贝大量的数据,而实际上并不移动数据,类似于“C语言”中传递指向数据结构的指针而非传递数据结构本身。这样一来,每个端口都有一个已知的私有存储范围Ma(prime)/Mailbox或Mb(prime)/Mailbox以及一个共享的Mailbox。当通过在Mailbox中存放数据执行后台复制,然后重新将Mailbox指派给执行后台复制的该端口时,这就可以以简单的方法保持数据的一致性。
信令问题
在最简单的情形下,连接到主机的静态和动态存储器均为SDR器件,并共享一条存储总线。这时可以采用一个简单的方法来实现DDR模式下共享总线的操作。时钟上升沿可用于所有DRAM操作,下降沿则可用于所有SRAM操作。在本质上,主机控制器在一个DDR流中多路复用了两个SDR数据流,故而可以为SRAM和DRAM提供两个独立的通道。
如果主机的SRAM和DRAM控制器在上升沿进行操作,则这种方案中对于一个通道的延迟为零,而对于另外一个通道的延迟为半个时钟周期。通过重新分区时序,这种延迟就可以消除。
另一方面,采用DDR存储器时,上述简单的映射方案不适用。不过有一种简单的扩展方法也可用于支持DDR器件。
SDR方法定义了一种共享总线上的时隙方案(timeslot),这种时隙就是半个时钟周期中两个捕获的时钟边沿间的时间。时隙在SRAM和DRAM间是均匀分配的。为满足DDR器件的带宽需求,总线必须采用fbus时钟,BWstatic是SRAM所需的带宽,BWdyn是DRAM所需的带宽,width则表示连接存储器与主机系统的总线数据引脚的数量:
Fbus=1/2×((BWstatic+BWdyn)/Width)
对于任意时间周期,DDR方案都比SDR能提供更多的时钟沿和更多的时隙,因此,带宽和延迟需求都可以在比SDR方法更精细的区间内进行调节。
建立存储器系统总线只能辅助性地提高DRAM通道的延迟性能(每个方向不超过一个时钟)。
考虑到手机的每32字节缓存列(Cache line)需要16个节拍,而PC机每32字节缓存列仅需要4个节拍,一个周期附加的延迟造成每节拍1/8周期的负荷,性能降低不超过12.5%,这很容易通过超频总线进行补偿。如果在存储器通道中允许采用集成的非授权mux结构,就不会有附加延迟出现。
这种存储器系统应该是很容易被接受的,因为它允许采用现有的存储器系统。同时实现主机接口和规范的DRAM/SRAM控制器是可能的。主机CPU的DRAM控制器能够与新的存储器主机接口共享DRAM焊盘(通过配置寄存器或键合方式)。如果SRAM控制器的焊盘以键合方式实现,则同样的CPU裸片就能配置为支持传统或新型存储器系统的器件。
总之,不同的存储器系统均可用于相同的主机平台,并可以根据性能和成本扩展多种系统。
重新分区的方法最大限度减轻了外部总线的负荷,并为主机和存储器系统之间提供了一条统一总线,从而将外部存储器带宽提高到10Gbps,并减少了60%的引脚数量,进而降低了每个CPU的成本。此外,这种方式还为存储器系统提供了一个独立的物理层,可以把现有存储器总线透明地移植到未来的架构中。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 联手科大讯飞.锤子科技的人工智能产品这么厉害?
联手科大讯飞.锤子科技的人工智能产品这么厉害?






 APP下载
APP下载 登录
登录







