×


通过研究照片和场所在多模式内容上的富文本描述之间的跨模式相关性,研究了细粒度的场所发现。与以往的研究不同,这项工作共同优化了成对相关性和基于类别的相关性,同时实现了精确的场所搜索和团体场所搜索。
大量实验证实:第一,与最新方法相比,提出的 C-DCCA 方法大大提高了分组场所发现的性能。第二,使用粗略的位置信息有助于缩小 C-DCCA 和 DCCA 在精确场地搜索中的差距。第三,使用额外的图像资源来表示场地的视觉效果有助于进一步提高细粒度场地发现的性能。
在这项工作中,将旅行目的地和商务地点作为场所。通过照片发现场地对于视觉上下文感知应用程序非常重要。不幸的是,很少有工作去关注复杂的真实图像,例如用户生成的场地照片。我们的目标是从异构的社交多模式数据中去发现细粒度的场地。为此,我们提出了一种新颖的深度学习模型,即基于类别的深度典型相关分析(D-CCA)。给定照片作为输入,此模型执行:1)通过进行精确的场地搜索(查找照片所在的场地)和 2)通过对输入的照片与场地文字描述进行跨模式相关分组场地搜索(查找与照片具有相同类别的相关场地)。在此模型中,通过深度网络将不同形式的数据映射到同一空间,并联合优化了用于精确场所搜索的成对相关性(来自同一场所的不同形态数据之间)和用于组场所搜索的基于类别的关联性(来自具有相同类别的不同场所的不同形态数据之间)。由于照片无法完全反映场所的富文本描述,因此在训练阶段每个场所的照片数量会增加以捕获场所的更多特征。通过整合 Wikipedia 和 Foursquare 场地照片,我们构建了一个新的场地感知多模式数据集。在该数据集上的实验结果证实了该方法的可行性。此外,对另一个公共可用数据集的评估证实,我们所提出的方法优于最先进的图像和文本之间的跨模式检索的方法。1、背景
上下文感知应用程序非常有前途,因为它们可以提供适合用户上下文的合适服务。假设用户是第一次参观某个经典,他不知道确切在哪里,而是在那儿照相。场所发现有助于找到拍摄照片的确切地点以及一组文本/视觉特征也与照片匹配的相关地点。前者捕获用户上下文,而后者对于场所推荐很重要。
由于我们缺乏可靠的场所数据源,因此从照片中进行细粒度的场地发现几乎是不可能的。在多媒体技术创新和移动用户参与的推动下,与业务相关的社交多媒体数据和信息已大量出现在互联网上,例如,Wikipedia 中用于商务场所的专题文章,Foursquare 和 Yelp 上的商务场所照片以及视频在 YouTube 上投放广告。另一方面,包含视觉业务内容的场所照片的增长使各种业务服务对于 Internet 上的搜索者而言更加明显,从而导致了现实世界中的访问或购买。用户与场所之间的交互会在 Internet 上聚集各种多媒体数据和信息,这为我们提供了利用社交多模式数据的力量进行细粒度场所发现的新机会。在这里,多模式表示每个场所在文本和视觉(图像)等不同模式下具有多种表示形式。
一些文献已经研究了场地发现,例如,照片中地理类别的预测或照片的视觉概念,或照片位置的粗略预测。 但是,很少有工作致力于通过用户生成的更为复杂的真实图像(例如包含对象,地理类别和更有意义的语义描述的场所照片)进行细粒度的场所发现。
在这项工作中,我们调查了来自 Wikipedia 和 Foursquare 的与场所相关的多模式数据,并研究了(i)精确的场所搜索(查找拍摄照片的场地),以及(ii)在用于细粒度场地发现的联合框架中对场所进行搜索并分类(查找具有相同类别的相关场地)。据我们所知,这是第一项研究着重于通过与综合场所相关的多模式数据对场所进行视觉和文字多样性的联合优化。为此,我们提出了一种基于类别的深度 CCA(C-DCCA)方法,其中通过深度网络将不同模式中的数据非线性映射到同一空间,以便来自同一地点或不同地点的不同模式的数据 具有相同类别的人在该空间中高度相关。
图 1 显示了整个框架。虚线(i)部分说明了所提出的网络体系结构。从图像和文本中,分别提取视觉特征和文本特征。然而,这些功能属于不同的模式,无法直接进行比较。因此,通过使用 DNN 模型将它们映射到同一空间。为了增强此公共空间中的相关性,将 CCA 用作目标函数,DNN 模型均由三个完全连接的层组成。为了捕捉相似场所的共同特征,我们使用 Foursquare 中定义的地理类别作为概念将场所划分为组。CCA 目标函数中考虑了同一场所的照片和文本之间的成对相关性,以及具有相同类别的不同场所的照片和文本之间的基于类别的相关性,该函数用于调整 DNN 模型。
1)视觉特征提取:CNN 在图像识别任务中表现出出色的性能,尤其是,CNN 在学习表示视觉内容的复杂功能方面具有强大的能力,例如 HOG 和 SIFT 。因此,在图像处理中,我们以 ImageNet 上预先训练的 VGG16 模型为例,为所有图像提取视觉特征。每个场所图像首先被转换为 224×224 的固定大小,然后输入到网络中。VGG16 模型包含 13 个卷积层(conv1-conv13)和三个完全连接的层(fc14-fc16)。除 fc16 出于图像处理目的使用 softmax 激活外,所有层均使用 ReLU(整流线性单元)激活。除最后一层外,每个完全连接的层后面都有一个辍学层,以避免过度拟合。每层依次处理图像,最后提取 fc15 的 4096 维特征作为每个场所图像的视觉特征。
2)文本特征提取:很多研究者已经提出了用于表示文本特征的方法,例如 TF-IDF(词频-文档频率),主题模型(LDA 模型)以及通过空间中的矢量表示每个单词的单词嵌入方法 (Word2Vec),其中含义相似的单词在空间中彼此接近。Doc2Vec 通过将整个文档转换为固定长度的矢量来扩展 Word2Vec 模型,同时考虑了上下文中单词的顺序。在文本处理中,我们以 Doc2Vec 模型为例来提取文本特征。从 Wikipedia 抓取的每个场所的文本描述都包含许多不相关的信息。首先,通过调用 Wikipedia API 仅提取主要文本和类别信息。然后,使用 coreNLP 对其进行标记,并传递给 Doc2Vec 模型,从而为每个场所关联生成固定的 300 维特征。
3)C-DCCA:通过使用不同的 DNN,可以将视觉特征和文本特征进一步转换为公共空间中的低维特征,DNN 的详细信息显示在表 1 中。这两个 DNN 各自具有 3 个完全连接的层。 在输入之前,需要进行批量归一化。在第一层和第二层中,有一个 drop-put 子层,用于避免过度拟合。每一层都采用其前一层的输出来计算其输出。

表 1 DNN 配置参数

图 1 基于 D-DCCA 的细粒度场景发现框架图
在 Wikipedia 和 Foursquare 上,我们通过与 CCA,KCCA,DCCA,C-CCA(基于类别的 CCA)和 C-KCCA 进行比较来评估了所提出的 C-DCCA 方法的性能。
1)不同参数的影响评估:在训练中,使用了 Adam 优化器,并且将学习率设置为 0.0001,批次大小设置为 100。我们尝试使用不同的正则化参数 r(0.01、0.001、0.0001、0.00001),但未发现显着差异。在其余实验中,r 设置为 0.0001。参数 β 极大地影响系统性能。在不同的 β 值下,MRR1 和 MAP 的结果如图 3 所示。随着 β 的增加,MRR1 增加而 MAP 降低。 这是因为较大的 β 将导致协方差的权重较大,而交叉协方差的权重较小。当 β 在(0.3,0.7)范围内变化时,性能没有明显变化。在下文中,β 设置为 0.3。

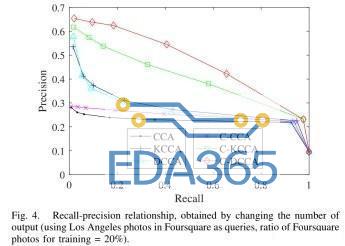
2)分组场所搜索的评估:我们在训练中调整 Foursquare 照片的比例,以查看所有方法从每个场所的照片增加中受益的情况。图 4 展示了使用洛杉矶照片作为查询的回忆精度曲线,其中训练中使用的 Foursquare 照片的比例等于 20%。从图中可以看出,C-DCCA 改善了基于类别的相关性,而 DCCA 仅强调成对相关性。
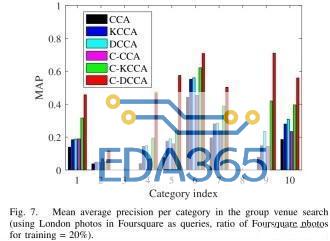
3)精确场所搜索的评估:我们通过 MRR1 指标评估查找照片确切地点的性能,用 Foursquare 中的洛杉矶照片作为查询的 MRR1 结果如图 8 所示。尽管在所有方法中,MRR1 的性能都随训练中使用的 Foursquare 图像比例的增加而提高,但 C-DCCA 和 DCCA 之间仍然存在明显的差距。但是与 C-DCCA 中 MRR1 的减少相比,C-DCCA 中 MAP 的增加要大得多。
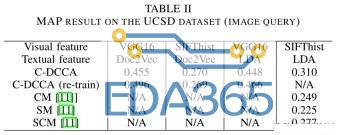
4)在 UCSD 数据集上的评估:为了证明其在其他任务中的适用性和有效性,我们将方法扩展到由 UCSD 组提供的公共数据集上的图像和文本之间的交叉模式检索和分类。 这个多模式图像文本数据集是完全根据 Wikipedia 的文章生成的,而无需依赖其他图像资源,该资源包含 10 个最受欢迎类别中的 2866 个文档(每个文档包含一对文本和图像)。它分为 2173 个文档的训练集和 693 个文档的测试集。类别的定义取决于 Wikipedia 标签,并且与具有特定于地点的语义标签的 Foursquare 不同。分组场所搜索的 MAP 结果见表 II。这些结果反映了三个事实。(i)就相关性分析而言,C-DCCA 优于中提出的跨模式检索方法。与 CM / SCM 相比,当使用相同的手工制作的 SIFThist + LDA 功能时,C-DCCA 可获得更好的性能。(ii)功能也起着重要作用。因为 VGG16 远远超过了 SIFThist,而 Doc2Vec 也比 LDA 好一点,所以当 C–DCCA 将其功能从 SIFThist + LDA 更改为 VGG16 + Doc2Vec 时,我们可以看到很大的改进。(iii)完善预训练模型也很有帮助。预训练模型的重新训练具有明显的效果(尤其是在使用 VGG16 + Doc2Vec 时),因为 UCSD 数据集的统计特性与用于预训练这些模型的大型数据集的统计特性并不完全相同。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 DDS 信号源在扫频测试中的应用
DDS 信号源在扫频测试中的应用







 APP下载
APP下载 登录
登录







