
腾讯发明的基于机器学习的迁移数据确定方法,通过获取服务器向多个终端进行数据迁移的迁移过程数据,基于机器学习对服务器侧的模型进行训练,获得针对于终端进行定制化的迁移模型,基于该迁移模型向终端高效迁移终端所需的数据,提高了迁移数据的准确性和效率。
目前,在特定的应用场景下,比如智能客服应用场景,智能客服能够基于终端侧已有的用户对话记录分析出用户的特征,比如用户的兴趣、习惯以及语言模式等。

但是,由于终端侧所积累的用户对话记录的数据量非常小,无法对该智能客服进行训练,也就导致了智能客服无法以符合用户的特征的方式与用户进行交互。在这种背景下,从服务器侧向终端迁移对应的数据对终端侧的模型进行训练的迁移技术应运而生。
通过在服务器上将所有终端的终端侧数据进行匿名汇总之后,在服务器侧进行模型训练,获得多个通用模型,再通过人工匹配的方式,从多个通用模型中确定出符合终端需求的模型,再基于该模型向终端迁移相应的数据,以解决终端侧数据量小而无法实现智能客服训练的问题。
然而,由于在服务器侧所训练好的模型是基于大量终端所积累的终端侧数据进行训练的,因此,所训练出的通用模型无法与特定的终端完全适配,导致通过该通用模型向终端所迁移的数据并不精确。另外,通过人工的方式确定出与终端相匹配的模型需要耗费了大量的人力,效率不高。
因此,腾讯在19年7月15日申请了一项名为“基于机器学习的迁移数据确定方法、装置、设备及介质”(申请号:201910637116.9),申请人为腾讯科技(深圳)有限公司。
根据目前该专利公开的资料,让我们一起来看看这项迁移数据确定方法吧。
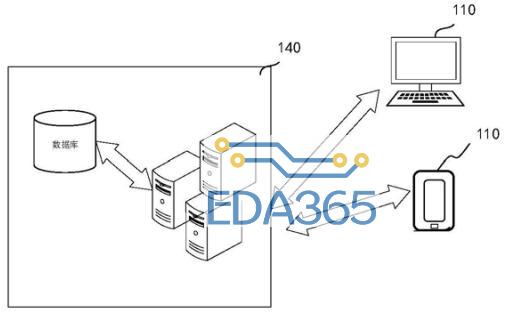
如上图为基于机器学习的数据迁移系统的结构框图,这个数据迁移系统包括终端110和数据迁移平台140,终端通过无线网络或有线网络与数据迁移平台相连,终端安装和运行有支持数据迁移的应用程序。
数据迁移平台可以由一台服务器、多台服务器、云计算平台和虚拟化中心中的任意一种构成,主要是用于为支持数据迁移的应用程序提供后台服务,在数据迁移平台和终端中均可以单独承担数据处理工作,也可以相互配合进行更加高效的组合。
而该发明主要涉及迁移数据,例如这种迁移数据主要是作为服务向终端用户提供并使用的数据。以智能客服场景为例,在云服务器确定出迁移模型,基于该迁移模型向终端迁移与该终端匹配的数据,结合终端的终端侧数据和迁移的数据,通过机器学习对终端的智能客服进行训练。
从而实现针对各个用户的兴趣、习惯以及语言模式等定制出属于用户自己的智能客服,比如,当用户在终端上向智能客服发起对话后,智能客服以用户可能感兴趣的方式、符合当前用户习惯以及符合用户语言模式的方式与用户进行对话。
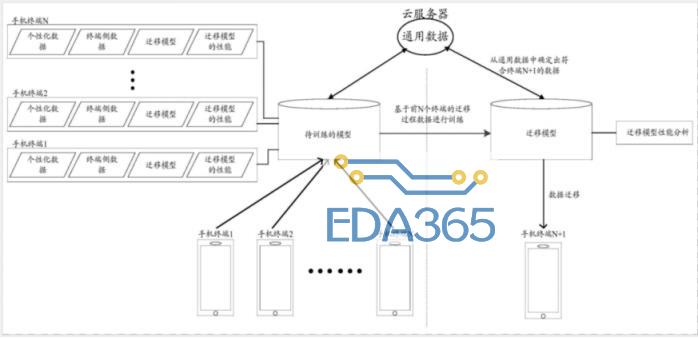
如上图为基于前N个终端的迁移过程数据实现向第N+1个终端迁移数据的示意图,需要迁移的数据存储在云服务器侧,针对于不同终端的需求,从云服务器侧中确定出对应的数据并向终端迁移,在云服务器侧基于已经向终端进行数据迁移的迁移过程数据进行分析,对云服务器上的模型进行训练,使训练后的模型能够针对特定终端迁移相应的数据。
获取已经向N个终端进行数据迁移的迁移过程数据,其中,N的取值范围为大于等于1的正整数,基于该N个迁移过程数据对云服务器的模型进行训练。最终,将训练后的模型应用至服务器向第N+1个终端进行数据迁移过程中。
在获取到服务器向多个终端进行数据迁移的迁移过程数据后,对所获取的迁移过程数据进行分析,确定出每个迁移过程数据的数据迁移性能指标,基于数据迁移性能指标数据对服务器中的待训练模型进行训练,获得迁移模型,通过该迁移模型从服务器侧的通用数据中确定出向目标终端迁移的数据,并响应于终端的迁移请求迁移该数据。
接下来我们具体看看该方案的流程图。
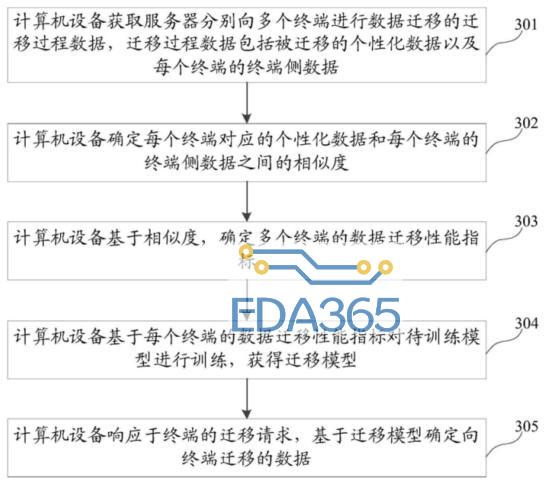
如上图所示为基于机器学习的迁移数据确定方法的流程图,首先,计算机设备获取服务器分别向多个终端进行数据迁移的迁移过程数据,迁移过程数据包括被迁移的个性化数据以及每个终端的终端侧数据。
例如,在图片识别的应用场景中,将猫的图片迁移到狗的图片,那么猫的图片与狗的图片之间具有共同特征的数据为眼睛部位的图像数据、鼻子部位的图像数据等。
其次,计算机设备确定每个终端对应的个性化数据和每个终端的终端侧数据之间的相似度。在理想的数据迁移情况下,被迁移的个性化数据应当与终端侧数据之间具有共同特征的数据,因此,需要确定出迁移过程数据的迁移性能,即被迁移的个性化数据与终端侧数据之间的相似程度越高,则表明对应迁移过程数据的迁移性能越好,可以将这些数据作为后续模型训练的训练基础,对云服务器侧的迁移模型进行训练和优化。
接着,计算机设备基于相似度,确定多个终端的数据迁移性能指标,计算机设备基于每个终端的数据迁移性能指标对待训练模型进行训练,获得迁移模型。最终,计算机设备响应于终端的迁移请求,基于迁移模型确定向终端迁移的数据。
通过训练后的迁移模型中包含了多个已经训练好的神经网络层,将终端的终端侧数据输入至迁移模型中,通过多个已经训练好的神经网络层对终端侧数据进行分析,分析出终端的特征数据后与云服务器侧的通用数据中进行匹配。最终确定出向该终端迁移的数据,保证了所迁移的数据是该终端所需求的数据,从而实现针对于用户生成定制化的模型,满足用户的需求。
最后我们来看看这里的迁移模型是如何获得的吧。
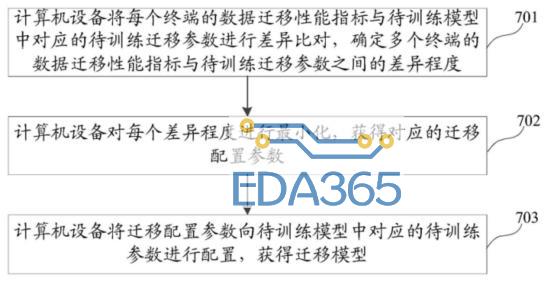
如上图所示,首先,计算机设备将每个终端的数据迁移性能指标与待训练模型中对应的待训练迁移参数进行差异比对,确定多个终端的数据迁移性能指标与待训练迁移参数之间的差异程度。
其次,计算机设备对每个差异程度进行最小化,获得对应的迁移配置参数,例如从之前获得的N个迁移过程数据对服务器中的待训练模型进行训练。
最终,计算机设备将迁移配置参数向待训练模型中对应的待训练参数进行配置,获得迁移模型。一个通过机器学习而被训练好的迁移模型可以被认为存储了迁移学习技巧,即对什么样的用户终端数据,应该从服务器端迁移什么样的知识。
以上就是腾讯发明的基于机器学习的迁移数据确定方法,通过获取服务器向多个终端进行数据迁移的迁移过程数据,基于机器学习对服务器侧的模型进行训练,获得针对于终端进行定制化的迁移模型,基于该迁移模型向终端高效迁移终端所需的数据,提高了迁移数据的准确性和效率,同时节省了大量人力!
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 负载调制电路的具体设计
负载调制电路的具体设计




 APP下载
APP下载 登录
登录







