
共识协议是当前区块链网络最重要的部分之一,并已经由最早的PoW衍生出PoS与DPoS等诸多共识协议。
不过当前行业所面临的问题是,技术的不断进步与用户需求的提升会要求区块链共识协议做出一定的改进,但这往往相当困难,以太坊就是最典型的案例。
本文阐述了共识协议的特性与行业进展,提出共识协议自我调整的可能方案,希望对大家有所启发。
新的基础设施涌现出新的技术,而新技术中所带来的欲望则孕育着技术的自否定。原有的基础设施终因无法再满足欲望所需而被遗弃,在新的技术与欲望的共同推动下实现变革。
人类本身就是在不断迭代的环境中自我进化,不断适应新的技术和掌握新的技能,若无法学习和成长,自然被淘汰。而技术本身也是,若技术无法跟上时代发展的步伐,技术本身也会被超越,被淘汰。
公链和围绕公链形成的生态就如同一个社会体系,很多时候整个社会不是不想快速前进,而是需要一个保守的方式,以稳定和安全为第一优先级,尽量用最小化的变动完成对新情况的适应。
我们必须承认区块链是类似硬件的软件,回顾这项技术并不长的历史,我们已经明显感受到它这一项弱点:每一次分叉都是对整个社区的一种冲击。比如,以太坊从 2015 年至今,经历了三次分叉:
· Homestead 分叉,通过了 3 个 EIP;
· Byzantium 分叉,通过了 8 个 EIP;
· Constantinople 分叉,通过了 5 个 EIP。
而 GitHub 中的正在讨论的 EIP 还有上千个。
每次分叉都是在千万个需求中艰难地做抉择,找到当下最必要的几个需求做出改进,并在社区进行大规模的探讨。以太坊的核心开发者要清楚智能合约平台目前面临的情况,调查开发者们的需求,评估每一个协议改进对以太坊本身的影响;而且在一个开源的体系中,每一次改进都会有诸多的安全问题。
如最新的君士坦丁堡分叉,SSTORE 指令的改进在最后关头被 ChainSecurity 团队发现漏洞,是一个原本不会出现、但是改进之后牵扯到其他代码带来的可重入漏洞问题。对于一个如此庞大的开源生态,在不断权衡升级的利弊之后,你还不得不在升级之前在测试网反复进行测试来确保安全性,确保任何指令不会由于本次对代码的修改造成其他后果。
但是现实情况就是,技术是不断进步的,不断会有新的硬件设施、软件技术,会有全新的需求,要求区块链协议做出一定的改进。最理想的方式是区块链能够足够的底层、足够灵活、足够简单,在需要升级的时候能够尽可能避免过多的变动。
协议是否能够自我调整?
若协议能够自动适应环境的变化,拥有某种类似自我进化的能力,是否能够极大程度改善这一点?在这其中,共识的设计关系到网络和计算能力,是其中关键的一个部分。
比特币是目前运行最久的区块链,已经运行了十年,而十年前和十年后,带宽水平发生了巨大的变化。

如同上图中这个研究所指出的,链接到网络中的比特币 IPv4 节点在 2016 年时带宽中位数为 33 Mbit/s,在 2017 年 2 月,这个数字达到了 56 Mbit/s。而比特币的最大吞吐量至今没有太大的改观。
那是否有能力来让共识算法能够根据环境调节自己的吞吐量,而不需要通过分叉等方式进行升级呢?这里有两个规律我们需要去了解,虽然规律是对历史的总结,但是某种程度上我们可以用这些规律预测未来。
1)摩尔定律 Moore’s Law:也就是集成电路性能18-24个月翻倍,同样的,存储器也是遵循同样的规律。也有表述称每年增长 60%。
2) Nielsen‘s Law:这是一个和带宽水平有关的定律,大致意思是用户的带宽每年增长 50%。相对于摩尔定律每年 60% 的计算速度增长速率,带宽增长速率慢大约 10 %。
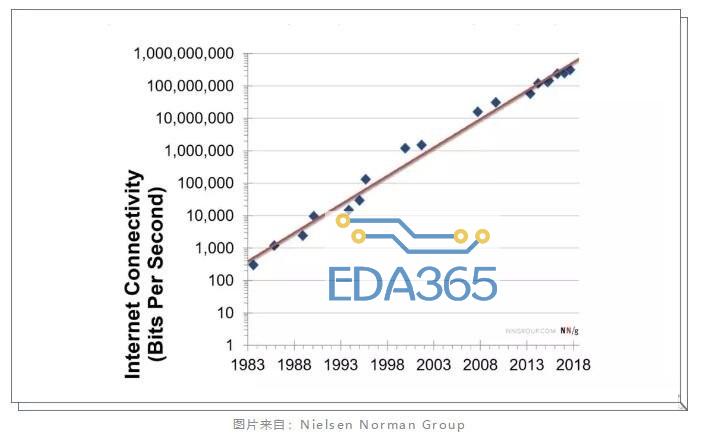
上图是 1983 年到 2018 年带宽的变化曲线,注意竖轴是 Log10,所以我们也能够看到带宽的增长也是指数形式增长的。
在 Nervos 共识研究员张韧之前的分析中,我们知道衡量区块链共识协议的一个标准是带宽利用率。带宽提高是节点间通信水平的提升,意味着共识会更加高效。
而共识协议是一开始就写死的,如果需要修改则要进行分叉。比特币、以太坊如果需要根据网络情况提高自己的吞吐量,需要的是开发者对网络情况进行估计,权衡效率和安全,然后采用一种保守的方案对协议进行升级。
升级又是一件痛苦的事情,最好的情况是:设计一种共识机制能够根据带宽水平的提升「自我进化」,来适应带宽增长带来的变化。
如何设计可以自我调整的共识协议
那么我们需要去思考,有没有一个区块链能够感知的指标,同时这个指标能够体现当前网络的情况。根据这个指标协议能够动态调节自己的吞吐量?
在 PoW 共识协议的研究中,有一个很重要的概念是孤块。
百度百科的定义是:在比特币协议中,最长的链被认为是绝对的正确。如果一个块不是最长链的一部分,那么它被称为是「孤块」。一个孤立的块是一个块,它也是合法的,但是发现的稍晚,或者是网络传输稍慢,而没有能成为最长的链的一部分。在比特币中,孤块没有意义,随后将被抛弃,发现这个孤块的矿工也拿不到采矿相关的奖励。
以比特币为例,一个在中国的矿工很幸运的在上个区块出块之后的 9 分钟的时候挖到了区块,然后他很开心地开始广播这个区块。但是这个区块花了几十秒还是没有广播到美国的矿工,十分钟的时候美国的矿工发现了同样高度的区块,也开始广播。
随着两个区块通过比特币的 P2P 协议不断广播开来,这时候大家会发现网络里有两个相同高度的区块,这时候比拼的就是全网算力的支持,一部分算力认可北美矿工的区块,根据这个区块所在的链进行挖矿,另一个则在中国矿工所在链上挖矿,这时候就是产生了分叉。
在随后的几个区块竞争中,双方阵营的矿工必然有一个先抢出块权,成为最长链,而后根据最长链原则,最后只能有一条最长链被所有矿工接受,结束分叉。另一条被遗弃的链上面的区块就是孤块。
孤块就是因为带宽限制产生的延迟,矿工没有收到新的区块而自己出块产生了竞争,而这个竞争必然带来一方矿工的损失。并且短暂的分叉其实也是损害了网络的安全性,这也是我们应该避免的。如果我们能够假设带宽无限好,区块出块能够瞬间无缝广播出去,那么就不会存在这样的竞争出现孤块,没有人损失,也不会产生安全上的问题。
而孤块是区块链能够感知的,我们可以用全网的孤块率作为指标,来评估目前网络带宽情况。孤块率低的时候意味着网络情况良好,没有太多的出块竞争,高的时候则表示网络情况太差,需要调高出块难度,提高出块间隔避免密集的出块产生竞争。因此设置一个合理的孤块率作为指标,协议根据当前孤块率,对比这个指标评估网络情况动态调节出块难度会是一个不错的选择。
带宽利用率是评估共识效率的重要指标。在孤块率较低的时候,这意味着网络情况良好,能够承载更多的吞吐量。因此这时候可以降低出块难度,降低出块间隔,提高吞吐量,更好地利用网络带宽。
孤块率较高的时候,意味着网络情况比较差,这时候可以提高出块难度,提高出块间隔,降低吞吐量。
这样,通过设定孤块率调节吞吐量,随着未来带宽水平的提升,协议也能够根据网络情况的优化提高吞吐量来适应未来的发展和变化,在保证一定安全性的同时,充分利用网络带宽。
在张韧博士的设计中,就采用了这样的设计思路。
张韧因为对 Bitcoin Unlimited 漏洞的研究,被 Blockstream 邀请实习,实习期间和 Pieter Wuille 和 Greg Maxwell 对目前所有的 PoW 共识机制作出研究。目前张韧在鲁汶大学 COSIC 实验室师从 Bart Preneel ,并和导师完成了研究论文《Lay Down the Common Metrics: Evaluating Proof-of-Work Consensus Protocols’ Security》,近期该论文被顶级会议 IEEE S&P 收录。
在他的设计中,在每一个难度周期根据网络中的孤块率(孤块的信息会被打包到区块中用于统计和计算)动态调节难度,从而调节出块间隔。这个共识协议的设计在比特币 Nakamoto Consensus(即中本聪共识) 的基础上进行修改,能够在不损失安全性的同时提高网络的吞吐量 —— 我们称这个共识算法为NC-Max,我们希望它能够突破 Nakamoto Consensus 的吞吐量极限。
当然细心的读者可能会想到两个问题:
1)出块奖励如何计算?
出块间隔是变化的,出块奖励其实也是变化的。但是在一个难度调节周期,总出块奖励保持不变。
2)吞吐量提高之后,是否有存储的问题?交易速度提高了,交易产生的存储需求也会增加。
很巧的是,根据之前提到的 Moore’s Law 以及 Nielsen’s Law ,带宽增长速度略慢于存储水平的提升。因此,在带宽提升、吞吐量提升的同时,计算能力和储存能力会不断跟上甚至超越,不会出现由于 TPS 过高对计算能力的要求而需要更强的超级计算机,损失去中心化。
另外,在 NC-Max 的设计中,除了采用动态调整出块间隔和区块奖励来提升带宽利用率以外,还有两个设计亮点:
1)采用两步交易确认来降低孤块率:交易首先会提交交易的编号(编号是完整交易的 hash 值,和交易一一对应)在区块的交易提案区进行共识,之后只有经过提案的交易才能完整发送,从而能够一定程度降低孤块率;
2)在难度调整的时候考虑周期中所有的区块,包括孤块,来抵御「自私挖矿」攻击。
总的来看,共识协议的自我调整会受到行业越来越多的关注,其解决方案也会越来越多。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 区块链部署的步骤是怎样的
区块链部署的步骤是怎样的






 APP下载
APP下载 登录
登录







