
前言
大家可能会惊讶的发现,目前大部分的公链项目,不约而同的走向统一方向:
“PoS提速并解决计算冗余、随机数信标保证去中心化、staking保证安全性、周期性最终确认保证轻量”。
包括刚公布的ETH2.0、algo以及不少新公链,VRF/VDF慢慢仿佛要成为下一个保证去中心化的标准,PoW的原始支持者也逐渐认识到了切换PoS后带来性能飞越,甚至荒废了三四年的“世界超级计算机”的概念,也被越来越多的项目方提起了。
DFINITY算是最早坚持以上标准的项目,从2017年起就没有转变过PoS+随机数+WASM虚拟机的技术方向(以太坊2.0表示 “ 真香!”)。共识方面的设计可以说是它最大的技术亮点,技术白皮书以分层的结构介绍了一致性共识的达成,文中将按步骤分解,简单帮助大家讲解共识。并简述技术特点,与其他项目做比较,揭示这样优缺点带来的影响。
共识过程
DFINITY的共识是按照轮为单位进行的,每一轮产出本轮的一个区块,一轮的时间为区块时间,轮次等于区块高度。
1. 开始前的节点准备(按顺序)
· 节点创建私钥公钥,建立匿名的永久身份。
· 节点加入网络需要抵押固定的token作为staking。
· 节点随机的与其他节点组成阀值组(完全随机,一个节点可存在于多个阀值组)
· 阀值组中,运行分布式密钥协议(DKG),每个节点获取该组的“验证签名”密钥(不同于个人密钥,有一组的私钥数学拆分而来)。
· 系统还是根据DKG产生阀值组的共同公钥,并对阀值组进行注册。
· 准备就绪,开始等待参与共识。
2. 第R轮共识
step1 选择本轮委员会组
· 系统根据R-1轮次生成的随机数ξR,在已有的阀值组中随机的选择R轮的委员会。

step2 提案委员会打包出块
· 选出的委员会分成两部分,提案组与验证组,提案组先收集用户发送的交易,检验合法后进行打包,出块与常见区块链项目一致。
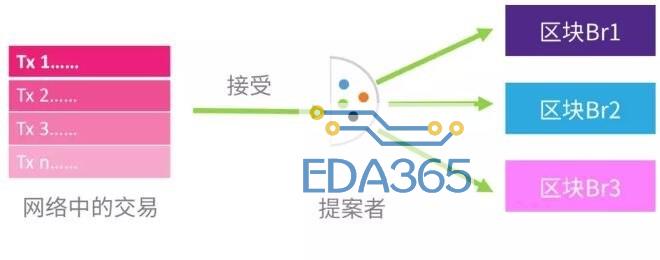
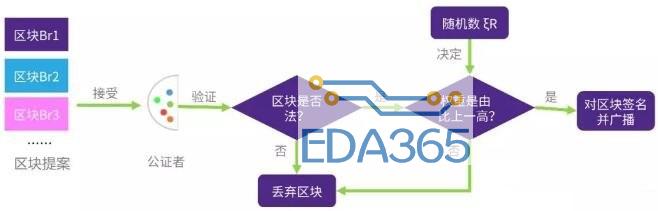
step3 公证委员会持续接收并验证区块
· 接受区块:持续的接受提案组产出的区块,直到观测到下一个随机数ξR+1的产生。
· 检验合法:接受区块后首先检验是由合法有效(有无引用R-1区块的公证),不合法就丢弃。
· 计算优先级:运行“概率插槽协议”,计算连续两个区块的权重,这是根据由随机数得出的区块权重得出的。
· 签名并广播:如果上一步中区块权重高于上一个接收到的,签名并广播;否则就丢弃区块。
step4 随机数信标收集签名
· 随机数信标持续的收集公证者广播的签名部分,并记录数目。
等待阀值,产出公证与随机数
· 一但对单个区块,接受了超过50%公证者的签名,马上聚合签名,产出公证Zr(本质是时间戳)并写入区块广播。
· 同时产生根据这些签名产生随机数ξR+1,广播。

R+1 step0 同步正确区块,R+1轮开始,回到strp1
· 此时广播传播全网,R轮委员会全部停止工作,节点开始同步被公证的区块。
· 根据随机数ξR+1选择R+1轮的委员会组。

共识特点
DFINITY是一个试图“扩展当前互联网”的区块链项目,是由所有参与网络的P2P客户端(DFINITY中称节点node为客户端client)共同维护并提供资源的“世界超级计算机“,这台计算机上“安装”的如软件具备了区块链上智能合约的不可篡改与可信的属性,但同时必须能够承载大规模服务,并能够完全托管软件。
不同于以太坊的DApp只是适时调用合约,DFINITY设想的软件是完全依靠智能合约来驱动服务的。综上来讲,DFINITY需要非常高的计算性能、减少计算冗余,因此DFINITY但同时还得在保证去中心化的情况下 做到足够安全,因此这对它的共识算法提出了苛刻的要求。
1. 从“完美的随机数”出发
DFINIFTY共识最重要的组成部分即为随机数信标部分,需要做的事情有:
· 选择共识参与组:在DFINIFTY这个无准入(不需要申请即可加入,反例是EOS)的网络中,参与网络的节点数以万计,且分布在世界各地,因此所有节点共同达成一致性的效率就非常之低,系统得选择一小部分成员来参加共识来保证速度。但是为了保证去中心化,成员必须随机选择。去中心化与性能的基础基于随机数。
· 决定区块的权重:用于判断最终确定链,快速的获得最终确认时间,剪除分叉。
· 给链上应用提供随机源:智能合约上很多DApp都是自己写的随机数方案,非常不成熟,经常会有应用因为不安全的随机数而被黑客攻击的新闻出现,这里直接从底层提供了稳定随机数。
VRF涉及很多数学演算,我们可以将其视为一个黑箱子,一段是输入,一段是输出。输入是一组客户端的签名,输出是一个准确的随机数。只有在获取了足够多的客户端签名,黑箱子才能输出随机数,再此之前,没有任何一个客户端能知道或预测它的输出。“足够多”签名的阀值为50%,因此这个VRF的过程也叫做“阀值签名”。
这个VRF很特殊,因为它具备三个特点:
· 可验证:一但输出了随机数,大家都可以拿着客户端的签名对其进行验证。VRF的”V”就体现在这里。
· 唯一确定性:一但有超过50%的客户端发送了签名,黑箱子接受到后会获得唯一的一个确定的随机数。这里是因为使用的私钥签名算法具有唯一性,也就是统一密钥对统一数据的多次签名的结果都不相同,只有一个可以合法的验证。
· 非交互:在产生随机数的过程中,虽然黑箱子需要收集大家的签名,但是客户端之间不需要进行交流,更没法干扰到随机数的从产生。
在已知的密码学算法里,只有BLS算法能做到以上三点,而BLS算法的提出者之一“L” Lynn正是DFINITY的高级工程师。其他的随机数方案,要么验证起来难度极高(连续哈希),要么无法保证唯一性,要么就是没有阀值的设计,必须进行交互,存在“最后一个参与者”就能间接影响随机数偏差的情况(以太坊的RANDAO与VDF)。
当然这个VRF还是一点问题,选取的一组共识者中如果有超过50%被攻击者掌握,那么他可以间接的干扰到随机数的生成,当然来预测随机数还是基本不可能的,没法直接控制。攻击者还可以不发送签名,让随机数生成过程停止,从而让整个系统宕机。当然这都是攻击者掌握了超过50%节点的情况下,这在staking里难度很大的,真做到了也没有那个共识算法顶得住。
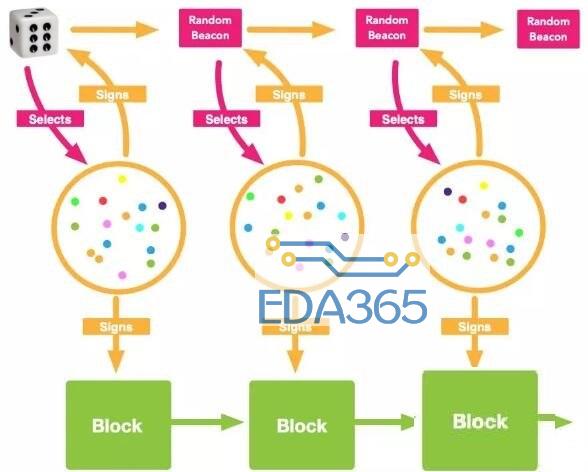
2. 非交互式
使用随机数在全网中筛选节点组成共识组,来参与共识的项目不少,包括固定选择的DPOS、DBFT(NEO的共识),以及分轮次随机选取的,比如Algorand、Cardano,包括DFINITY,在选出了共识组后,组内成员都会出块,这时存在多个区块,需要获得唯一的共识。
因此其他的项目比如NEO、Algorand、Cardano都是运行完整的拜占庭容错协议,在组中达成一致的协议,对区块进行确认。但是这个只要运行拜占庭协议,就意味着你的共识组不能过大,最大只能100个节点左右,再多就会存在性能与带宽爆炸的问题。所以就会有21个组轮流出块的设计,这大大拉低了项目的去中心化程度。
但如果你把组做的很大,像algo那种2000多人的大组,这个共识组在运行拜占庭容错协议时,就需要经历数十次的数据交互,同时传送一个非常庞大的签名数据,这样对整个网络的带宽要求就非常之高,普通人很难参与进来。
说回DFINITY,首先由随机数公开的选出了400个客户端一组的出块组,来打包交易并出块。每一个客户端都会出块,还有一组同时随机数选出的验证者,他们会接受区块,同时运行一个根据随机数判断区块权重的协议,验证者只签名权重最高的节点,期间大家不会交互,不会进行拜占庭共识互相发送签名数据,主要是固定区块时间里不断寻找权重最高的区块即可。在一个区块接受到了超过50%个验证者的签名后(是单独签名的,不是一起联合签名的),系统会自动聚合区块上的签名,并确认区块为唯一,一但客户端观察到聚合的签名,就会进入下一轮共识。
可以看到,整个过程都没有进行拜占庭协议,只是遵序三个原则:
· 客户端遵序最高权限的原则对区块签名,权重越高的链越会被确认
· 系统遵循50%以上签名产出随机数信标的原则
· 大家遵序一看到新的随机数信标马上进入下一轮共识的原则
三个原则就像三把锋利的奥卡姆剃刀,剔除了多余的无效区块,获得了唯一的区块,从而近似的达成了一致性共识(说近似是因为可能有同时存在两个被公证区块)。整个通讯过程几乎为零,在广播gossip协议的网络中,一个有400个节点的组网,只需转发大约20KB的通信数据,即可产生阈值签名。而一个小组的分布式签名密钥的生成,是在小组创建时就分配好的,不需要在共识阶段产生,一次生成多次使用。
我们可以来类比一下非常相似但由两轮拜占庭共识交互的Algorand。Algo的随机数抽签过程是隐秘式的,也就是说节点只知道自己被选择与否,它却不知道全网中有多少节点被选中。因此Alogo共识前必须遍历一编全部网络,进行一次拜占庭才能知道全部的被选取的验证组,因此这里的延迟时间与带宽使用就很高了。再加上前面讲的超大验证组(2000人到4000人)的拜占庭通讯轮次与签名数据的问题,Algo共识下带宽使用非常爆炸,这种人是没这个能力参与的。
3. 超快的最终确认
脱离最终确认时间谈TPS的都是耍流氓,有个笑话,拿卡车运装满数据的硬盘,你算算这个TPS也非常大了,可是没有最终确认与相应,显然是不能用的。不说比特币与以太坊,我们可以看到大量的新公链,特别是做多链分片的项目,就存在最终确认的严重滞后问题。
PoW与传统PoS,只能近似的获得一个最终确定性,也就是回滚概率趋近于0的时候,这就导致大额交易需要等待多个区块确认。并且因为没一个准信,每一个节点都得存储全部的副本,防止分叉的回滚。这就导致整个账本体积大的吓人,普通人基本告别全节点,随着区块的增长,以太坊的全节点数量就下降的非常快,如此下去,系统又得回到中心化脆弱的状态下了。
可以从上面了解到,DFINITY的共识是按轮次进行的,每一轮共识的开始与结束的标志,都是观察到随机数信标产生新的随机数,而这个随机数是系统聚合签名产生公证的同时更新的。因此这DFINITY的区块高度必须与轮次一致,每一轮中生产的区块,必须是引用了上一轮的公证签名,不然视为非法。同时公正组只会签名本轮产生的区块,不会对之前轮次的区块签名。
总结为两个强制:
· 只有本轮发布的区块才能被公证;
· 只有引用上一轮被公证的本轮区块才是合法的;
这保证了出块与公证两个过程,都没法被恶意扣留,因此攻击者没办法偷偷来准备一条比主链更长的影子链,来做双花攻击,因为从影子链的第一个区块起就不合法了。
因为存在上述“验证者组单独签名,系统聚合签名产生公证”的公证过程,因此每一轮后基本可以做出唯一性的确认。但也有会出现两个或以上区块同时通过公证的情况,因此一轮结束后还不能做到最终确认,这时就需要在下一轮中继续判断。此时等待出块过程完成,因为出块者可能选择在上一轮同时被公证的区块后面继续生产,所以同时存在几条分叉。
还记得上面讲的“概率插槽协议”(PSP)阶段吗?验证者会计算权重来判断唯一区块,没错,这里验证者还是会对着区块计算这条链上的总权重,这是权重高的一条链就作为唯一确认链,然后验证者才会对他进行签名。因此当本轮出现了新随机数时,也就意味着分叉已经被剪除,而上一轮的区块,包括其中的交易,都获得了最终的确认。
最终确认时间=两个出块间隔+网络遍历传输延迟
因此一个交易可以在几秒钟里完成最终确认,再也没法对其进行回滚。可以对比一下以太坊2.0,它用的是每隔100个区块创建一个检查点来做最终确认的方案,最终确认时长大约为10分钟左右。
快速确认不仅提高了性能,剪除了分叉,降低了系统的冗余度,并且可以让客户端不用存储全部要历史区块数据,任何一个新加入的区块,只要从最近的确认区块开始即可。
4. 几乎无限的弹性扩展性能
这同样是优秀的随机数给DFINITY带来的好处。DFINITY的网络可以近乎无限的扩展,因为整个随机数的产出,包括出块与公证,都是由固定数目的委员会组来执行的,客户端新节点的加入不会影响到运行的速度。而每一个客户端,都需要一定性能的计算与存储性能,这位整个“世界计算机”提供了近乎无限的资源。
单链的性能已经足够强大,而DFINITY又天然适合分片。
上面讲到,DFINITY随机产生多个阀值组的,因此多组间并行运行,从而实现分片,是相当轻松的。以太坊2.0的分片方式也非常近似。
但这部分官方披露的并不多,还需要一个片间协作的机制。同时涉及到智能合约运行,也存在以太坊2.0分片上类似的问题,也就是合约具体该运行在哪一个分片上?
特别是DFINITY这种存储软件全部结果状态的,因为虽然分片能对计算性能进行扩展,但我们得同时考虑存储与网络的扩展性,如果运行软件的组根据随机数不断变动,那么存储的分布如果是全节点一起同步,这样存储冗余度上来了,也就称不上扩展了;如果随出块运算同步的分散存储,那么存储的数据分布可能是不均的,而软件运行需要的数据从一个节点传到另一个节点是需要耗费时间的,这样带宽可能就撑不住了。
希望DFINITY能在分片层上也作出优秀的设计,学习以太坊2.0的合约固定运行在单独分片上,或片间快照转移也是没问题的。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 PoD共识算法的经济模型分析
PoD共识算法的经济模型分析






 APP下载
APP下载 登录
登录







