
过去几年,FPGA的CAGR大约一直保持在8-10%左右,随着该类器件在AI应用中的扩张,未来5年其CAGR增长将高达38.4%!根据市场调研公司Semico Research的预测,人工智能应用中FPGA的市场规模将在未来4年内增长3倍,达到52亿美元。为了保持竞争力,目前全球有25%的企业实施了人工智能/机器学习(AI/ML),而两年内,这一比例将增长到72%,以更好地获得核心职能方面的商业洞察力。
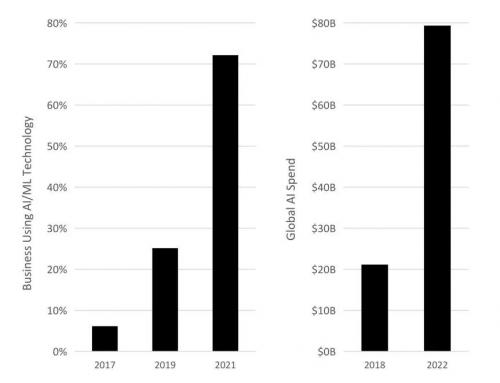
图:企业AI/ML部署需求增长趋势
来源:WSJ pro
伴随这一趋势,AI的算法在不断演进,对数值精度的选择要求也更加多元,高效算力、高效丰富的存储缓存能力以及高效大带宽的数据运送能力,是AI/ML硬件解决方案所面临的主要挑战。系统开发者会利用FPGA架构去优化功耗、性能和灵活性,并突破处理单元在效率上的瓶颈,包括计算引擎、内存层次结构和数据移动。
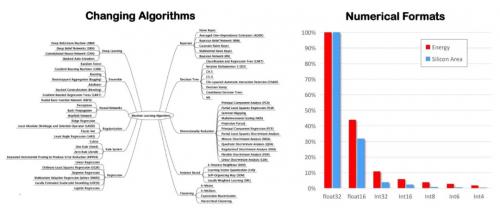
图:算法和精度要求不同给处理带来挑战
就AI的应用而言,不同场景应用对FPGA的需求不同。通常云计算中的应用主要是需要FPGA在AI/ML和高带宽数据加速上的能力,而在端侧则需要在高灵活性的同时还要具有ASIC的性能。虽然,FPGA已经大量应用于泛AI领域,但它是否很好的满足这两个方面的需求,还是一个值得探讨的话题。
重构FPGA架构
纵观FPGA产品的演进历史(包括器件的产生),每一次大的迭代都是一种设计方法论的革新,从这个角度看,Achronix公司最近发布的Speedster7t针对上述两个应用场景上进行的优化都可以看做方法论上的革新。在开发Speedster7t的过程中,Achronix的工程团队完全重新构想了整个FPGA架构,以平衡片上处理、互连和外部输入输出接口,实现数据密集型应用吞吐量的最大化,这些应用场景可见于那些基于边缘和基于服务器的AI/ML应用、网络处理和存储。
“Speedster7t是我们历史上最令人激动的发布,代表了建立在四个架构代系的硬件和软件开发基础上的创新和积淀。”Achronix公司董事长兼首席执行官Robert Blake介绍,“该器件采用TSMC的7nm FinFET工艺制造,专为ML和高带宽网络应用进行了优化。”
具体而言,相较于目前的FPGA,Speedster7t革新之处在于设计了针对ML的处理器(MLP),以及一个可横跨和垂直跨越FPGA逻辑阵列的高带宽的二维片上网络(NOC),二者结合既保留了FPGA的灵活性,又实现了ASIC的性能。
不占用FPGA布线的MLP单元
这个片内的MLP是高度可配置的、计算密集型的单元模块,可支持4到24位的整点格式和高效的浮点模式,包括对TensorFlow的16位格式的支持,以及可使每个MLP的计算引擎加倍的增压块浮点格式的直接支持。该MLP可以通过运算和缓存级链实现更复杂的算法,而不需要使用FPGA布线资源。
“目前FPGA会使用DSP来进行ML的处理,但其对数值精度的支持并不高效,并且需要消耗额外逻辑和存储资源,其性能也受限于FPGA布线。”Blake说,“DSP常用于无线数字滤波的处理,而Speedster7t中的MLP则在计算架构、缓存(内嵌)、可配置算法以及对整点和浮点的支持上提供了更好的AI/ML的计算性能和能效比。”
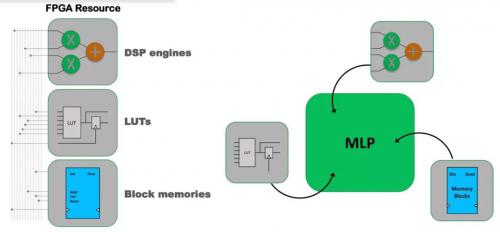
图:在FPGA中采用MLP(右)比DSP(左)更适用于AI/ML处理
二维片上网络——NOC
NOC是在FPGA路由结构上的另一个重要革新。这一设计主要针对FPGA的片上处理引擎之间所需的高带宽通信。Speedster7t片上资源包括8个GDDR6控制器、72个业界SerDes(1到112 Gbps)、带有前向纠错(FEC)的硬件400G以太网MAC(4x100G或8x50G的配置),以及硬件PCI Express Gen5控制器(每个控制器有8个或16个通道)。
这些高速I/O和存储器端口的数万兆比特数据很容易淹没传统FPGA面向比特位的可编程互连逻辑阵列的路由容量,而Speedster7t通过NOC把它们连接到所有FPGA的高速数据和存储器接口。NOC和FPGA功能之间通过网络接入点NAP连接,每个水平行和垂直列的交叉点都有NAP(主NAP和从NAP)。NoC中的每行/列都可同时为每个方向提供512Gbps的数据流量,其链路双向运行,最大的设备带宽可以达到20Tbps。
“最重要的是,NOC消除了传统FPGA使用可编程路由和逻辑查找表资源在整个FPGA中移动数据流中出现的拥塞和性能瓶颈。”Blake说,“这种高性能网络不仅可以提高Speedster7t FPGA的总带宽容量,还可以在降低功耗的同时提高有效LUT容量。”

图:NOC是在FPGA路由结构上的另一个重要革新
的确,NOC这一方法解决了GDDR6、400G以太网MAC这些片上资源间海量数据传输的问题。Speedster7t是目前市面唯一支持GDDR6存储器的FPGA,可以支持4 Tbps的GDDR6累加带宽,可以很小的成本提供与基于HBM的FPGA等效存储带宽。相较于HBM,GDDR6只需要一半的成本就可以满足高存储层次和带宽的需求,并且,HBM是固化的块,GDDR6则更灵活,用户可以选择不同容量和带宽。
NOC也解决了传统FPGA的运行速度无法满足任何400G以太网总线宽度要求的问题,400G以太网的总线大小达1024bit,所需的最高频率达到724 MHz,这在传统FPGA中无法实现,NOC由于消除了传统设计中与FPGA布线相关的延迟,所以可以最高支持750 MHz的频率,这满足了MLP和嵌入式存储器模、400G以太网MAC及高速SerDes之间的数据传输。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 如何解决变频器干扰问题
如何解决变频器干扰问题









 APP下载
APP下载 登录
登录







