
分布式存储最早是由谷歌提出的,其目的是通过廉价的服务器来提供使用与大规模,高并发场景下的Web访问问题。它采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
1、分布式存储的兴起
分布式存储的兴起与互联网的发展密不可分,互联网公司由于其数据量大而资本积累少,而通常都使用大规模分布式存储系统。
与传统的高端服务器、高端存储器和高端处理器不同的是,互联网公司的分布式存储系统由数量众多的、低成本和高性价比的普通PC服务器通过网络连接而成。其主要原因有以下三点
(1)互联网的业务发展很快,而且注意成本消耗,这就使得存储系统不能依靠传统的纵向扩展的方式,即先买小型机,不够时再买中型机,甚至大型机。互联网后端的分布式系统要求支持横向扩展,即通过增加普通PC服务器来提高系统的整体处理能力。
(2)普通PC服务器性价比高,故障率也高,需要在软件层面实现自动容错,保证数据的一致性。
(3)另外,随着服务器的不断加入,需要能够在软件层面实现自动负载均衡,使得系统的处理能力得到线性扩展。
2、分布式存储的重要性
从单机单用户到单机多用户,再到现在的网络时代,应用系统发生了很多的变化。而分布式系统依然是目前很热门的讨论话题,那么,分布式系统给我们带来了什么,或者说是为什么要有分布式系统呢?
(1)升级单机处理能力的性价比越来越低;
企业发现通过更换硬件做垂直扩展的方式来提升性能会越来越不划算;
(2)单机处理能力存在瓶颈;
某个固定时间点,单颗处理器有自己的性能瓶颈,也就说即使愿意花更多的钱去买计算能力也买不到了;
(3)出于稳定性和可用性的考虑
如果采用单击系统,那么在这台机器正常的时候一切OK,一旦出问题,那么系统就完全不能用了。当然,可以考虑做容灾备份等方案,而这些方案就会让系统演变为分布式系统了;
(4)云存储和大数据发展的必然要求
云存储和大数据是构建在分布式存储之上的应用。移动终端的计算能力和存储空间有限,而且有在多个设备之间共享资源的强烈的需求,这就使得网盘、相册等云存储应用很快流行起来。然而,万变不离其宗,云存储的核心还是后端的大规模分布式存储系统。大数据则更近一步,不仅需要存储海量数据,还需要通过合适的计算框架或者工具对这些数据进行分析,抽取其中有价值的部分。如果没有分布式存储,便谈不上对大数据进行分析。仔细分析还会发现,分布式存储技术是互联网后端架构的神器,掌握了这项技能,以后理解其他技术的本质会变得非常容易。
3、分布式存储的种类和比较
分布式存储包含的种类繁多,除了传统意义上的分布式文件系统、分布式块存储和分布式对象存储外,还包括分布式数据库和分布式缓存等,但其中架构无外乎于三种
A、中间控制节点架构
以HDFS(HadoopDistribuTIonFileSystem)为代表的架构是典型的代表。在这种架构中,一部分节点NameNode是存放管理数据(元数据),另一部分节点DataNode存放业务数据,这种类型的服务器负责管理具体数据。这种架构就像公司的层次组织架构,namenode就如同老板,只管理下属的经理(datanode),而下属的经理,而经理们来管理节点下本地盘上的数据。
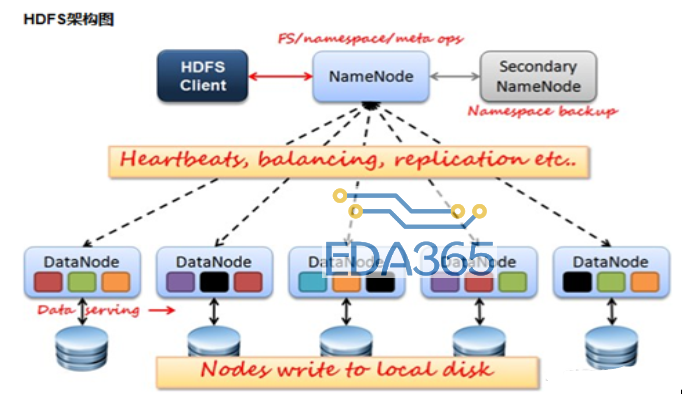
在上图中,如果客户端需要从某个文件读取数据,首先从NameNode获取该文件的位置(具体在哪个DataNode),然后从该NameNode获取具体的数据。在该架构中NameNode通常是主备部署(SecondaryNameNode),而DataNode则是由大量节点构成一个集群。由于元数据的访问频度和访问量相对数据都要小很多,因此NameNode通常不会成为性能瓶颈,而DataNode集群中的数据可以有副本,既可以保证高可用性,可以分散客户端的请求。因此,通过这种分布式存储架构可以通过横向扩展datanode的数量来增加承载能力,也即实现了动态横向扩展的能力。
B、完全无中心架构–计算模式
以Ceph为代表的架构是其典型的代表。在该架构中与HDFS不同的地方在于该架构中没有中心节点。客户端是通过一个设备映射关系计算出来其写入数据的位置,这样客户端可以直接与存储节点通信,从而避免中心节点的性能瓶颈。

如上图所示,在Ceph存储系统架构中核心组件有MON服务、OSD服务和MDS服务等。
(1)MON服务用于维护存储系统的硬件逻辑关系,主要是服务器和硬盘等在线信息。MON服务通过集群的方式保证其服务的可用性。
(2)OSD服务用于实现对磁盘的管理,实现真正的数据读写,通常一个磁盘对应一个OSD服务。
(3)MDS只为CephFS文件存储系统跟踪文件的层次机构和存储元数据。Ceph块设备和RADOS并不需要元数据,因此也不需要CephMDS守护进程
(4)RADOS:RADOS就是包含上述三种服务的ceph存储集群。在Ceph中所有的数据都以对象形式存在的,并且无论哪种数据类型RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致性。要做到这一点必须执行数据复制、故障检测和恢复,以及数据迁移和所在集群节点实现在平衡
(5)RBD(块设备):原名RADOS块设备,提供可靠的分布式和高性能块存储磁盘给客户端。
(6)CephFS:Ceph文件系统提供了一个使用Ceph存储集群存储用户数据的与POSIX兼容的文件系统
(7)Librados:libRADOS库为PHP、RUBY、Java、Python、C++++等语言提供了方便的访问RADOS接口的方式
(8)RADOSGW:RGW提供对象存储服务,它允许应用程序和Ceph对象存储建立连接,RGW提供了与AmazonS3和openstackSwift兼容的RUSTFULAPI
客户端访问存储的大致流程是,客户端在启动后会首先通过RADOSGW进入,从MON服务拉取存储资源布局信息,然后根据该布局信息和写入数据的名称等信息计算出期望数据的位置(包含具体的物理服务器信息和磁盘信息),然后和该位置信息对应的CephFS对应的位置直接通信,读取或者写入数据
C、完全无中心架构–一致性哈希
以swift为代表的架构是其典型的代表。与Ceph的通过计算方式获得数据位置的方式不同,另外一种方式是通过一致性哈希的方式获得数据位置。一致性哈希的方式就是将设备做成一个哈希环,然后根据数据名称计算出的哈希值映射到哈希环的某个位置,从而实现数据的定位。
Swift中存在两种映射关系,对于一个文件,通过哈希算法(MD5)找到对应的虚节点(一对一的映射关系),虚节点再通过映射关系(ring文件中二维数组)找到对应的设备(多对多的映射关系),这样就完成了一个文件存储在设备上的映射。

D、分布式存储的比较
那么现在问题来了,如果我们要选择分布式存储,选择哪种好呢?其实它们各有各的优势和使用场景,具体要看需求。
(1)HDFS
主要用于大数据的存储场景,是Hadoop大数据架构中的存储组件。HDFS在开始设计的时候,就已经明确的它的应用场景,就是大数据服务。主要的应用场景有:
a、对大文件存储的性能比较高,例如几百兆,几个G的大文件。因为HDFS采用的是以元数据的方式进行文件管理,而元数据的相关目录和块等信息保存在NameNode的内存中,文件数量的增加会占用大量的NameNode内存。如果存在大量的小文件,会占用大量内存空间,引起整个分布式存储性能下降,所以尽量使用HDFS存储大文件比较合适。
b、适合低写入,多次读取的业务。就大数据分析业务而言,其处理模式就是一次写入、多次读取,然后进行数据分析工作,HDFS的数据传输吞吐量比较高,但是数据读取延时比较差,不适合频繁的数据写入。
c、HDFS采用多副本数据保护机制,使用普通的X86服务器就可以保障数据的可靠性,不推荐在虚拟化环境中使用。
(2)Ceph
目前应用最广泛的开源分布式存储系统,已得到众多厂商的支持,许多超融合系统的分布式存储都是基于Ceph深度定制。而且Ceph已经成为LINUX系统和OpenStack的“标配”,用于支持各自的存储系统。Ceph可以提供对象存储、块设备存储和文件系统存储服务。同时支持三种不同类型的存储服务的特性,在分布式存储系统中,是很少见的。
a、Ceph没有采用HDFS的元数据寻址的方案,而且采用CRUSH算法,数据分布均衡,并行度高。而且在支持块存储特性上,数据可以具有强一致性,可以获得传统集中式存储的使用体验。
b、对象存储服务,Ceph支持Swift和S3的API接口。在块存储方面,支持精简配置、快照、克隆。在文件系统存储服务方面,支持Posix接口,支持快照。但是目前Ceph支持文件的性能相当其他分布式存储系统,部署稍显复杂,性能也稍弱,一般都将Ceph应用于块和对象存储。
c、Ceph是去中心化的分布式解决方案,需要提前做好规划设计,对技术团队的要求能力比较高。特别是在Ceph扩容时,由于其数据分布均衡的特性,会导致整个存储系统性能的下降
(3)Swift
主要面向的是对象存储。和Ceph提供的对象存储服务类似。主要用于解决非结构化数据存储问题。它和Ceph的对象存储服务的主要区别是。
a、客户端在访问对象存储系统服务时,Swift要求客户端必须访问Swift网关才能获得数据。而Ceph使用一个运行在每个存储节点上的OSD(对象存储设备)获取数据信息,没有一个单独的入口点,比Swift更灵活一些。
b、数据一致性方面,Swift的数据是最终一致,在海量数据的处理效率上要高一些,但是主要面向对数据一致性要求不高,但是对数据处理效率要求比较高的对象存储业务。而Ceph是始终跨集群强一致性。主要的应用场景,在OpenStack中,对象存储服务使用的就是Swift,而不是Ceph。
责任编辑人:CC
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 数据中心需求猛增.NAND Flash Q4营收季提升8.5%
数据中心需求猛增.NAND Flash Q4营收季提升8.5%









 APP下载
APP下载 登录
登录







