×


本文转载自http://blog.csdn.net/charmingsun/article/details/52295018
官方文档:
STM32F411 参考手册
STM32F411 数据手册
Cortex™-M4F 编程手册
STM32 微控制器系统存储器自举模式应用笔记
STM32™ 自举程序中使用的 USART 协议
ARM Cortex™-M Programming Guide to Memory Barrier Instructions
有关 Cortex-M4 处理器三级指令流水线知识的补充:
指令流水线以及相关名词的定义:
指令流水线是为提高处理器执行指令的效率,把一条指令的操作分成多个细小的步骤,每个步骤由专门的电路完成的方式。Cortex-M4 处理器采用三级流水线的哈佛结构,一条指令的执行分为取指阶段 (Fetch stage)、译码阶段 (Decode stage)、执行阶段 (Execute stage)三个阶段,所以称为三级流水线。把每个阶段所消耗的时间定义为一个机器周期(也有人把从内存读取一条指令字的最短时间定义为一个机器周期),把执行完一条指令需要花费的时间定义为一个指令周期。采用指令流水线的意义:
如果不采用三级流水线技术,则此时的指令周期为三个机器周期。如果采用三级流水线技术,那么当前一条指令执行完取指阶段进入译码阶段之后,执行取指阶段的电路就可以对下一条指令进行取指了。以此类推,在理想情况下,当一条指令正处于执行阶段时,此时 CPU 中还有一条执行处于译码阶段、一条指令处于取指阶段,这样 CPU 的指令周期就缩短为一个机器周期。非理想情况是指处理非顺序执行的代码(有分支)时,指令可能并不存在于当前使用的或预取的指令行中,此时 CPU 将重新取指,即流水线将被清空。直接修改程序计数器 PC 中的数值等特殊情况也会导致流水线被清空,也属于非理想情况。每个阶段的详细解释:
取指阶段之前 Cortex-M4 内核先通过AHB总线向存储器发送请求指令的地址,待存储器取出地址中的指令后,再进入取指阶段将对应地址中的指令发回给Cortex-M4 内核,其中存储器从收到地址到取出指令之间的这段时间称为等待周期。取指阶段是指将一条指令从存储器中取到指令寄存器的过程。程序计数器 PC 总是指向当前正在被取指的指令的地址,当一条指令取指完毕后 PC 中的数值将自动增加 4,在使用 32 位指令的情况下指向下一条被取指的指令,在使用 16 位指令的情况下指向下下一条被取指的指令(因为在使用 16 位指令的情况下一次取两条指令)。因为执行阶段处于第三阶段,所以当一条指令处于执行阶段时,PC 寄存器的值已经相比于这条指令处于取指阶段时的 PC 值增加了 8。
在译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。
执行阶段又分为三个子阶段:访存取数阶段 (Reg Read)、逻辑运算阶段 (Shift/ALU)、结果写回阶段 (Reg Write)。访存取数阶段的任务是根据指令需要,可能需要访问寄存器或者存储器、读取操作数。逻辑运算阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。结果写回阶段的任务是把逻辑运算阶段的运行结果数据“写回”到寄存器或者存储器。
Cortex-M4 使用的是 Thumb-2 指令集,其中大部分为 16 位指令,少部分为 32 位指令。由于 Cortex-M3 和 Cortex-M4 的指令缓冲区的存在,它的流水线操作不同于传统的精简指令集处理器:
● 一个机器周期内最多取两条指令,因为大部分指令都是 16 位的;
● 一条指令可以在译码和执行阶段之前的数个机器周期内被取出。
图示为 Cortex-M4 使用 16 位指令时的三级流水线:
专有的自适应实时 (ART) 存储器加速器面向 STM32 工业标准 ARM® Cortex™-M4F 处理器进行了优化。该加速器很好地体现了 ARM Cortex M4F 的固有性能优势,克服了通常条件下,高速的处理器在运行中需要经常等待 FLASH 读取的情况。
为了发挥处理器的全部性能,该加速器将实施指令预取队列和分支缓存,从而提高了 128 位 Flash 的程序执行速度。根据 CoreMark 基准测试,凭借 ART 加速器所获得的性能相当于 Flash 在 CPU 频率高达 100 MHz 时以 0 个等待周期执行程序。
指令预取
每个 Flash 读操作可读取 128 位,可以是 4 行 32 位指令,也可以是 8 行 16 位指令,具体取决于烧写在 Flash 中的程序。因此对于顺序执行的代码,至少需要 4 个 CPU 周期来执行前一次读取的 128 位指令行。在 CPU 请求当前指令行时,可使用 I-Code 总线的预取操作读取 Flash 中的下一个连续存放的 128 位指令行。可将 FLASH_ACR 寄存器中的 PRFTEN 位置 1,来使能预取功能。当访问 Flash 至少需要一个等待周期时,此功能非常有用。
下图所示为需要 3 WS(3 个等待周期)访问 Flash 时连续 32 位指令的执行过程,图中分别介绍了使用和不使用预取操作两种情况。
连续 32 位指令的执行过程(使用预取操作): 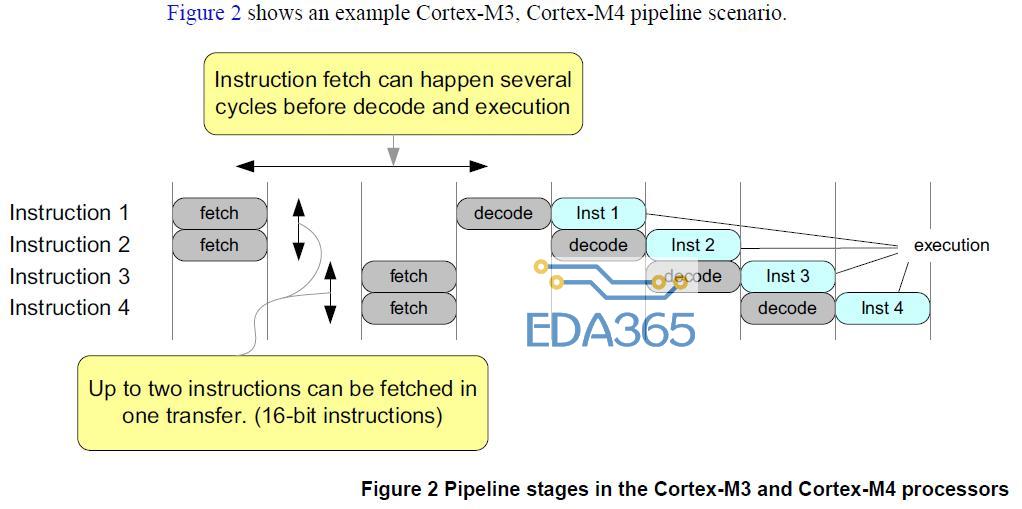
连续 32 位指令的执行过程(不使用预取操作): 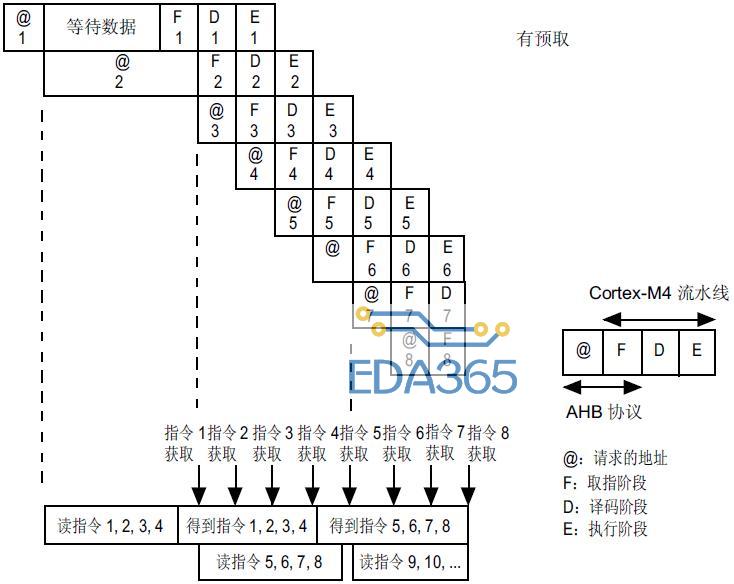
处理非顺序执行的代码(有分支)时,指令可能并不存在于当前使用的或预取的指令行中。这种情况下,CPU 等待时间至少等于等待周期数。
指令缓存存储器
为了减少因指令跳转而产生的时间损耗,可将 64 行 128 位的指令保存到指令缓存存储器中。可将 FLASH_ACR 寄存器中的指令缓存使能 (ICEN) 位置 1,来使能这一特性。每当出现指令缺失(即请求的指令未存在于当前使用的指令行、预取指令行或指令缓存存储器中)时,系统会将新读取的行复制到指令缓存存储器中。如果 CPU 请求的指令已存在于指令缓存区中,则无需任何延时即可立即获取。指令缓存存储器存满后,可采用 LRU(最近最少使用)策略确定指令缓存存储器中待替换的指令行。此特性非常适用于包含循环的代码。
数据管理
在 CPU 流水线执行阶段,将通过 D-Code 总线访问 Flash 中的数据缓冲池。因此,直到提供了请求的数据后,CPU 流水线才会继续执行。为了减少因此而产生的时间损耗,通过 AHB 数据总线 D-Code 进行的访问优先于通过 AHB 指令总线 I-Code 进行的访问。
如果频繁使用某些数据,可将 FLASH_ACR 寄存器中的数据缓存使能 (DCEN) 位置 1,来使能数据缓存存储器。此特性的工作原理与指令缓存存储器类似,但保留的数据大小限制在 8 行 128 位/行以内。
注意:用户配置扇区中的数据无法缓存。
单片机的存储器分为两种,一种是 ROM ( Read-Only Memory,相当于计算机中的硬盘),一种是 RAM (Random-Access Memory,相当于计算机中的内存)。ROM 主要指 NAND Flash、Nor Flash,RAM 主要指 SRAM、SDRAM、DDRAM、PSRAM。还有一种 XOM (Execute-Only Memory) 仅仅被 ARMv7-M 和 ARMv8-M 指令集架构所支持,这里不作介绍。
一个 C 语言程序被编译成 ELF 格式的可执行镜像文件可以分为四种不同属性的输出节:RO 节(只读)、RW 节(可读写)、XO 节(仅可执行)、ZI 节(未初始化)。它们在加载程序和执行程序时在存储器中的分布如下图:
1、不包含仅可执行 (XO) 节的镜像的加载视图和执行视图 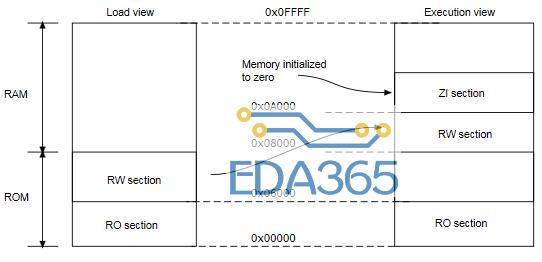
2、包含仅可执行 (XO) 节的镜像的加载视图和执行视图: 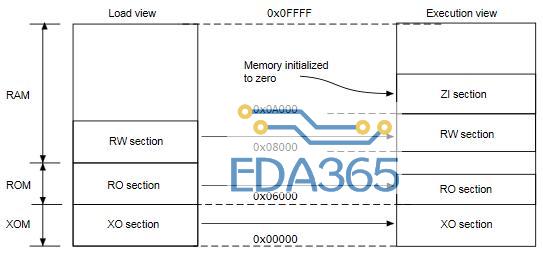
有关 ARM ELF 镜像结构的详细内容,请参考我的另一篇博客:ARM ELF 镜像结构
由于 STM32F411 采用的Cortex-M4架构属于具有三级流水线的哈佛结构,所以指令和数据使用不同的总线传输。
存储器采用固定的存储器映射,代码区域起始地址为 0x0000 0000(通过 ICode/DCode 总线访问),而数据区域起始地址为 0x2000 0000(通过系统总线访问)。Cortex™-M4F CPU 始终通过 ICode 总线获取复位向量,这意味着只有代码区域(通常为 Flash)可以提供自举空间。如果器件从 SRAM 自举,在应用程序初始化代码中,需要使用 NVIC 异常及中断向量表和偏移寄存器来重新分配 SRAM 中的向量表。
I 总线负责从代码区(0x0000 0000到0x1FFF FFFF的地址空间,共512MB)读取指令。Flash 储存器在此地址空间之内,而 SRAM 属于0x2000 0000到0x3FFF FFFF这段 512MB 的地址空间之内。所以如果需要运行 SRAM 中的程序,则需要将 SRAM 的地址物理映射到这一地址空间之内才能使用 I 总线从 SRAM 中读取指令。否则要运行SRAM中的程序只能通过 S 总线读取SRAM中的指令。不过SRAM一般用于保存数据而不是程序,因为SRAM不能掉电保存数据,相当于电脑的内存。
D 总线负责从代码区或者数据区(SRAM区,从0x2000 0000到0x3FFF FFFF这段 512MB 的地址空间)读取指令中位于指定地址的数据,从代码区中的Flash读取常量,从SRAM中读取变量。该总线在指令的执行阶段中的读寄存器操作时进行寄存器寻址。
S总线根据指令操作数据,写SRAM中的变量和堆栈,也可以用S总线执行SRAM中的指令、访问外设寄存器。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 STM32单片机的复用端口初始化的步骤及方法
STM32单片机的复用端口初始化的步骤及方法





 APP下载
APP下载 登录
登录








