×


本篇博文主要介绍虚拟化的基本思想以及在arm平台如何做虚拟化,arm提供的硬件feature等等。
虚拟化是一个概念,单从这个概念的角度来看,只要是用某一种物品去模拟另一种物品都可以称为虚拟化,甚至于有些饭店用豆腐做出肉的味道,我认为这也可以称为一种虚拟化。但是这里我们主要讨论的是计算机领域的虚拟化,我们这样定义虚拟化“虚拟化是将单一物理设备模拟为相互隔离的多个虚拟设备,同时保证这些虚拟设备的高效性”。这个概念的定义里还包含了对虚拟化的要求,也就是这里的隔离性(isolated)和有效性(efficient)。我们常说的hypervisor,有些书也把它称为VMM(virtual machine monitor)则是一个直接运行在物理硬件上的软件,它的功能就是管理物理硬件,以便在不同的虚拟机之间共享这些物理资源(cpu,内存,外设等等),既然hypervisor直接给物理外设打交道,那它当然需要运行在特权模式了,在过去没有virtualization extesion的情况下,guest os和guest application只能都运行在de-privileged模式,如下图所示。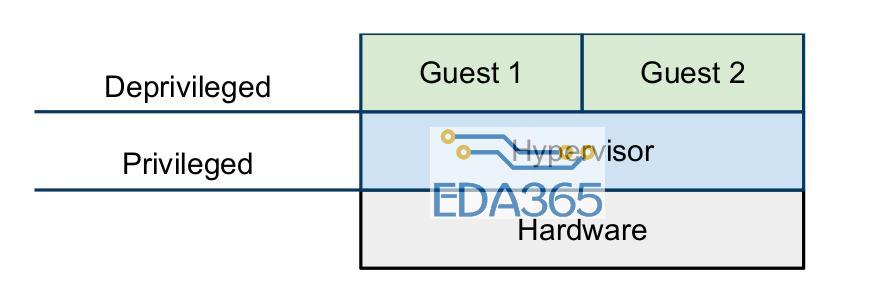
Popek和Goldberg有一篇虚拟化的经典论文,把需要在特权模式下执行的指令分成了两类:
sensitive instructions(敏感指令):这些指令试图去更改系统资源的配置信息,或者它的执行结果依赖于系统的状态。
privileged instructions(特权指令):这些指令在非特权模式下会trap(产生异常,陷入中断向量表),在特权模式下可以正常执行。
Popek和Goldberg提出构建hypervisor的要求:敏感指令是特权指令的子集。这种标准现在被称为classically virtualized(经典可虚拟化模型),虽然在不满足这个要求的情况下也可以做虚拟化(二进制翻译技术,后面会介绍),但是如果满足这个要求,实现起来会容易很多。下面介绍现有的虚拟化技术:
Pure virtualization(完全虚拟化):完全虚拟化要求硬件架构是可虚拟化的(符合经典可虚拟化模型),当trap进入hypervisor后,由hypervisor去模拟敏感指令的执行,这项技术也被称为trap-and-emulate。当一个guest os想要去访问特权资源(物理外设),就会产生一个trap唤醒hypervisor,hypervisor去模拟这个访问,然后返回到guest os的下一条指令去继续执行。如下图所示,红色箭头表示一个trap。可以看出,每一条特权指令都需要很多条指令去仿真,所以这种trap-and-emulate开销非常大,对系统性能有很大影响。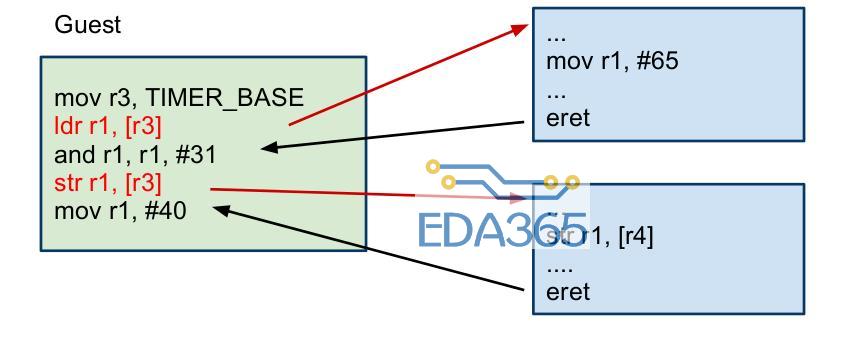
Binary rewriting(二进制重写):二进制重写就是当硬件架构不可虚拟化(不符合经典可虚拟化模型)采用的方法。它可以分为静态的和动态的,静态的二进制重写是通过扫描ELF文件,把所有的敏感指令替换成一个trap指令(系统调用指令),或者用一些非敏感指令去仿真执行这条敏感指令,动态的二进制重写对敏感指令的处理和静态的类似,只不过它是在运行时去逐条分析指令,其实这种方法更不好,因为不管是不是敏感指令,都需要逐条分析才能确定,非常耗时,静态方法在运行时的性能要好过动态方法,但是经常出现一些莫名其妙的错误,因为运行时状态非常复杂,静态修改很难预料到所有情况。上述过程如下图所示。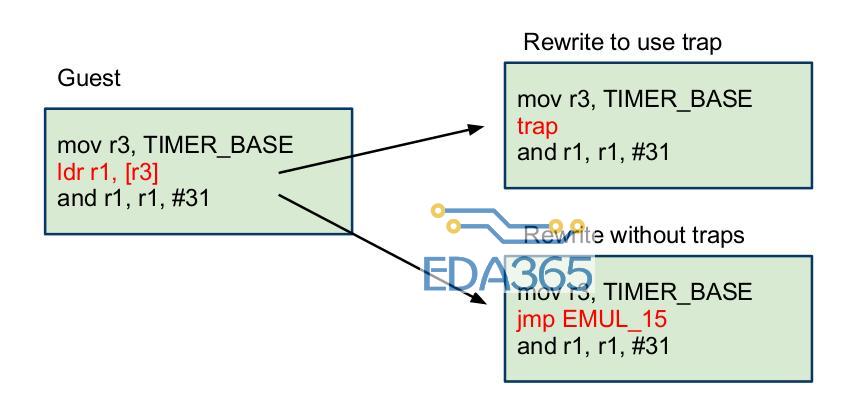
para-virtualization(类虚拟化):这种虚拟化方法,很多书都把它译为半虚拟化,其实这种译法是不准确的,半虚拟化(partial-virtualization)是一个早已存在的技术,它只虚拟化部分外设来满足某些专门的软件的执行环境,但是不能运行所有可能运行在物理机上的软件。如果读者对此有疑问,请参阅《系统虚拟化:原理与实现》,intel开源技术中心和复旦大学并行处理研究所著,书中1.3节对此有讨论。其实想解释清楚这部分内容是很难的,还要理解各种各样的虚拟化漏洞。简单来说,类虚拟化通过修改guest os的源码(API级),使得guest os避免这些难以虚拟化的指令(虚拟化漏洞)。操作系统通常会使用到处理器提供的全部功能,例如特权级别、地址空间和控制寄存器等。类虚拟化首先要解决的问题就是如何陷入VMM。典型的做法是修改guest os的相关代码,让os主动让出特权级别,而运行在次一级特权上。这样,当guest os试图去执行特权指令时,保护异常被触发,从而提供截获点供VMM来模拟(也可以采用hypercall的方式,下面介绍)。既然内核代码已经需要修改,类虚拟化还可以进一步优化I/O。也就是说,类虚拟化不是去模拟真实世界中的设备,因为太多的寄存器模拟会降低性能。相反,类虚拟化可以自定义出高度优化的I/O协议,这种I/O协议完全基于事物,可以达到近乎物理机的速度。
其实OKL4用的类虚拟化就是修改hypervisor提供给guest os的API(不同于底层硬件),同时修改guest os的源码,把那些敏感指令换成hypercall(calls into hypervisor)。下图展示的是,对于pure virtualization,硬件和hypervisor的API是相同的,但是对于para-virtualization是不同的。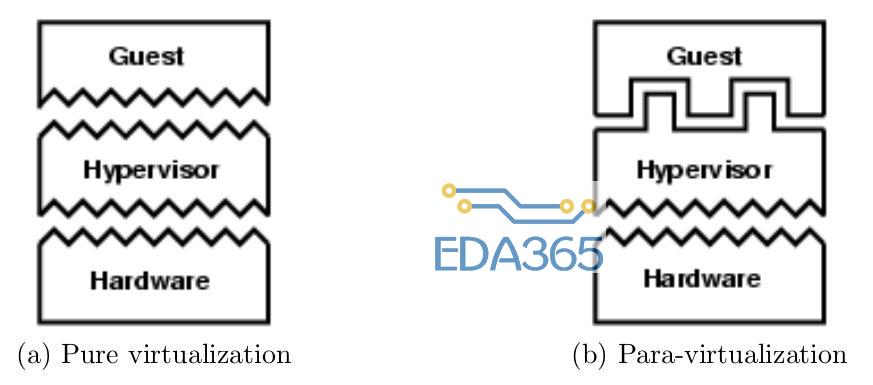
pure virtualization和binary rewriting都是不修改机器的API的,所以任何guest os都可以直接运行在虚拟化环境。但是,由于所有的特权指令都会导致trap,所以在虚拟环境下特权指令的执行开销要远远高于在native环境下。以前,x86和ARM都不符合classically virtualized时,VMWare采用binary rewriting在x86架构上实现虚拟化,经过优化后的性能开销小于10%,但是这项技术十分复杂。由于实现起来的复杂,就会增加运行在特权模式下的代码,这会增加attack surface和hypervisor出现bug的几率,所以会降低整个系统的安全性和隔离性。
Para-virtualization虽然是一个新词,在2002年中的Denali virtual machine monitor被提出来。但是这种设计理念早在1970的IBM的CMS系统就出现了,当时使用DIAG指令调用到hypervisor里去,并且一直到现在还有很多研究机构在使用这种理念,如Mach,Xen和L4。
Para-virtualization相比于pure virtualization可以提供更好的性能,因为它直接使用各种API而不是通过trap->decode->hardware emulation的过程来实现仿真。当然,它的缺点我也在之前的博客中提到过,那就是必须修改源码,让guest os使用新的API,这不仅是一项繁重的任务,同时对于一些非开源的操作系统,我们必须采用其他方法,除非这些非开源操作系统的厂商愿意与我们合作。
为什么要把内存管理部分单独拿出来讨论一下呢?因为这部分很复杂,其实之前我们讨论的内容主要都是cpu运行的问题,比如各种指令和各种模式之间的切换。关于内存,我们先讨论没有引入guest os时的虚拟内存管理,然后再讨论引入guest os之后的变化。
虚拟内存管理涉及的内容很多,这里不讨论各种内存分配算法,如何降低缺页率等等,只分析虚拟地址如何转换成物理地址。我们知道,ARM架构是通过MMU+TLB来完成从VA(virtual address,虚拟地址)到PA(physical address,物理地址)的转换,对于页表的访问实际上是由硬件自动完成的(如果不缺页的话)。但是加入了虚拟化之后,这个转换就复杂了,guest page table不完成从va到pa的转换,只是负责从guest va到guest pa的转换,而由hypervisor完成由guest pa到实际物理地址的转换,这个转换过程如下图所示。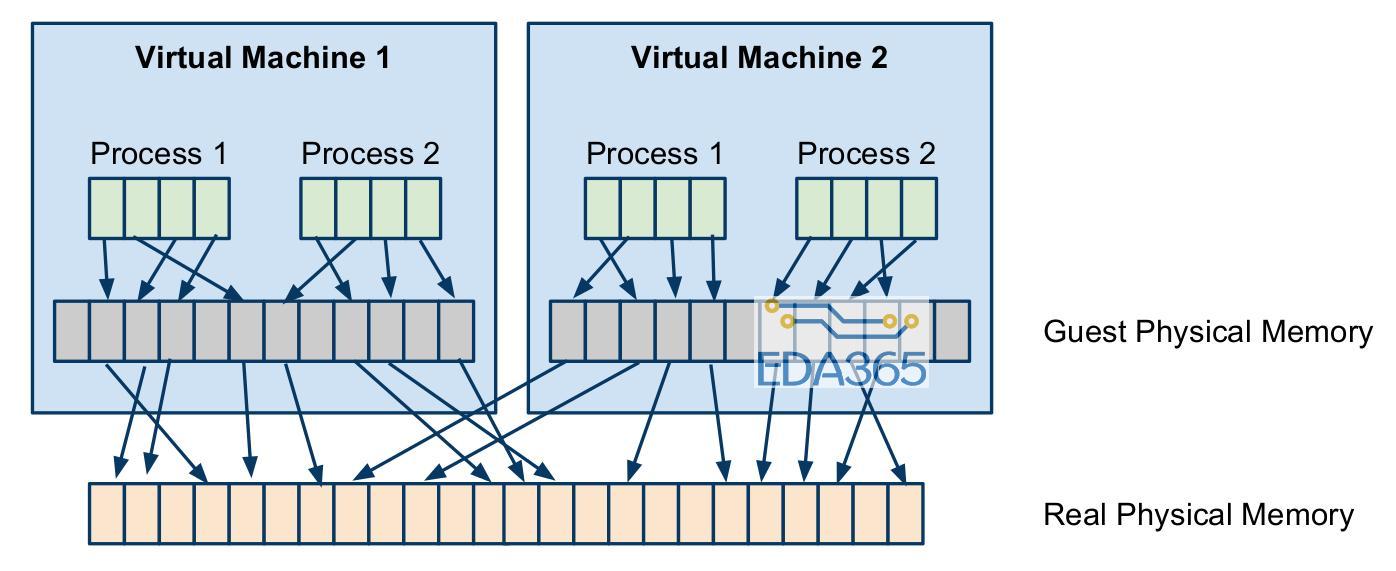
这个图表现的很清晰,但是想实现是非常难的,因为只有一个页表基址寄存器,所以硬件无法识别是从guest va到guest pa的转换还是va到pa的转换,在没有硬件支持的情况下,只能通过影子页表才能实现,影子页表的原理也是把两步转换(guest va->guest pa->pa)转换为一步,中间的同步用hash来做。影子页表在构建的时候,每次对guest page table的访问都需要trap,由hypervisor把guest pa转换成实际物理地址。如果读者想了解这一块内容,我建议深入学习一下KVM以前关于影子页表的实现(由于x86的硬件支持,目前KVM已经放弃影子页表),这里我们没办法深入探讨影子页表,但了解它大致是怎么一回事儿之后,我们可以分析以下它的性能。首先,它的性能一定非常不好,因为每次对guest page table的访问都需要trap,而且每次guest page table的修改还需要同步到影子页表上面,虽然用hash的方式能提速,但是相比于native环境性能差距比较大(NOVA做过一个实验,光访问页表的性能损失大约是23%),而且实现起来非常复杂。Intel和ARM对这一部分都提供了硬件支持,由硬件来完成这里提到的两级页表转换。其实根据程序运行时的局部性原理,如果每次访问都能TLB hit的话,这种二级页表转换和一级页表转换差别不大,但是当TLB miss的时候,需要访问two stage的页表访问的性能还是差别比较大的,尽管这部分由硬件来做。举个例子,比如KVM在Linux-64位的情况下,是4级页表转换,从va到pa需要访问5次页表,那么引入two stage之后,就需要5*5=25次访问页表,读者可以思考一下这里为什么是相乘的关系。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 51单片机中断源的扩展方法
51单片机中断源的扩展方法






 APP下载
APP下载 登录
登录







