×


边缘AI设备的生命周期可能长达数年甚至数十年,需要设备支持处理未来的机器学习(ML)算法。
尽管我们可能还不知道这些算法会是什么样子,但可以肯定的是,它们将比我们目前为边缘AI设备提供的工作负载更加复杂,要求更高。
如今,大多数边缘AI设备的每瓦功率约为4 TOPS至5 TOPS。这对于基本的ML例程已经足够了,但是与AI计算的数据中心产品相比无可比拟。
降低边缘AI的功率曲线
SiMa.ai的初衷是缩小这种性能鸿沟:重新定义当今与边缘AI相关的性能。然而,要在边缘AI设备中达到任何类似于云性能的性能,都需要显着降低功耗,或者说,是显着提高每瓦TOPS。
考虑到这一目标,我们开发了MLSoC(片上机器学习系统)平台,目标是每瓦10 TOPS的峰值。对于5瓦的嵌入式电源,我们的ML加速器最多可以达到50个TOPS。这足以支持传统上需要在被动冷却的边缘AI设备中实现云性能的AI工作负载。
我们将异构MLSoC设计为能够处理客户一段时间后创建的工作负载,但是还能够针对未来尚未确认的工作负载进行验证。与数据中心不同,数据中心可以随着新的组件迭代进入市场而进行升级,而内置在边缘AI设备中的硬件则是在将其放入芯片的那一天设置的。
我们针对这一挑战的解决方案将Arm的传统计算IP与我们自己的机器学习加速器和专用视觉加速器相结合。作为低功耗计算的市场领导者,Arm IP是构建MLSoC的安全平台的明显选择。在与客户紧密合作以定义其应用程序的计算要求之后,我们选择了Arm Cortex -A65 CPU:这是很大程度上取决于客户需求(从性能到软件工具链)的决策。
尽管SiMa.ai的MLSoC能够处理诸如自然语言处理(NLP)之类的各种ML工作负载,但最初已针对计算机视觉应用进行了优化。从终端摄像头到自拍,计算机视觉已经成为许多边缘AI用例的核心,并且我们相信,在高端监控,人群控制和热扫描等未来应用中,计算机视觉的应用只会增加。
计算机视觉为终端AI开启了未来的复杂用例
将视觉加速器与ML加速器结合使用还可以确保MLSoC能够处理复杂的工作负载,例如来自多个传感器的传感器融合,这使其能够在从工业自动驾驶到工业IoT环境中的自动驾驶系统中发挥作用,从消费者自动驾驶汽车到自动驾驶机器人。我们还预见了MLSoC在航空航天和国防领域中的作用。
当然,这些复杂的自主工作负载需要超过50个TOPS。这就是为什么我们将MLSoC设计为模块化的原因:通过专有互连将多个机器学习加速器镶嵌结合在一起,我们可以从5瓦的50 TOP扩展到40瓦的400 TOPS。
考虑到当今的5级自动驾驶汽车原型机耗电约4千瓦,这有可能将功耗降低100倍,并大大减少物理硬件的占地面积,同时减少对主动冷却的需求。
降低设备的功耗还有另一个很好的理由,这些设备很快将在成千上万的世界中占据一席之地。我们与之交谈的许多OEM和客户都非常清楚如何降低功耗,以便在2030年或更早之前实现碳中和。这就是我们想要设计低功耗的足够理由。
为开发人员提供所需的工具
我相信MLSoC将在边缘和边缘设备中实现低功耗AI方面发挥关键作用。但是我也知道,仅仅为以一定数量的TOPS为基准的解决方案提供Lisence是不够的。
当今市场上存在的许多解决方案都基于ResNet-50等基准来宣传其性能。但是,只有在实际条件下(即客户的工作量)可以达到的情况下,引用每秒帧数或每瓦TOPS才有意义。
我们的客户想要一件事:开发速度。他们可以多快上市。他们不想花费数月的开发周期来实现他们所承诺的性能,他们希望能够直接得到解决方案,然后使用简单而全面的工具添加自己的差异化特性。
我们计划在明年初发布MLSoC,以期在明年年底之前交付工程样品以及潜在的客户样品。但是,我们已经与客户紧密合作,以定义和构建他们的应用程序并将它们映射到我们的硬件,并且软件开发套件(SDK)将提前提供给客户。
这意味着他们将能够遍历整个流程,开发其应用程序并运行仿真,以便在芯片正式商用后,产品可以编译即用。
而且由于MLSoC以Arm技术为基础,因此我们的客户可以确保他们将拥有不仅需要构建下一代,而且还要构建许多后代的高性能,低功耗AI设备所需的软件,工具和持续支持。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

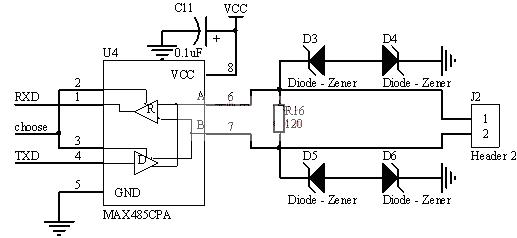
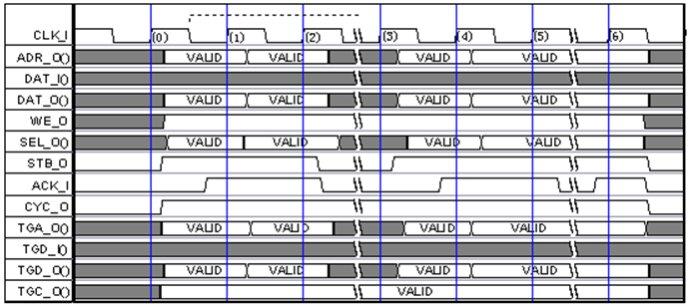
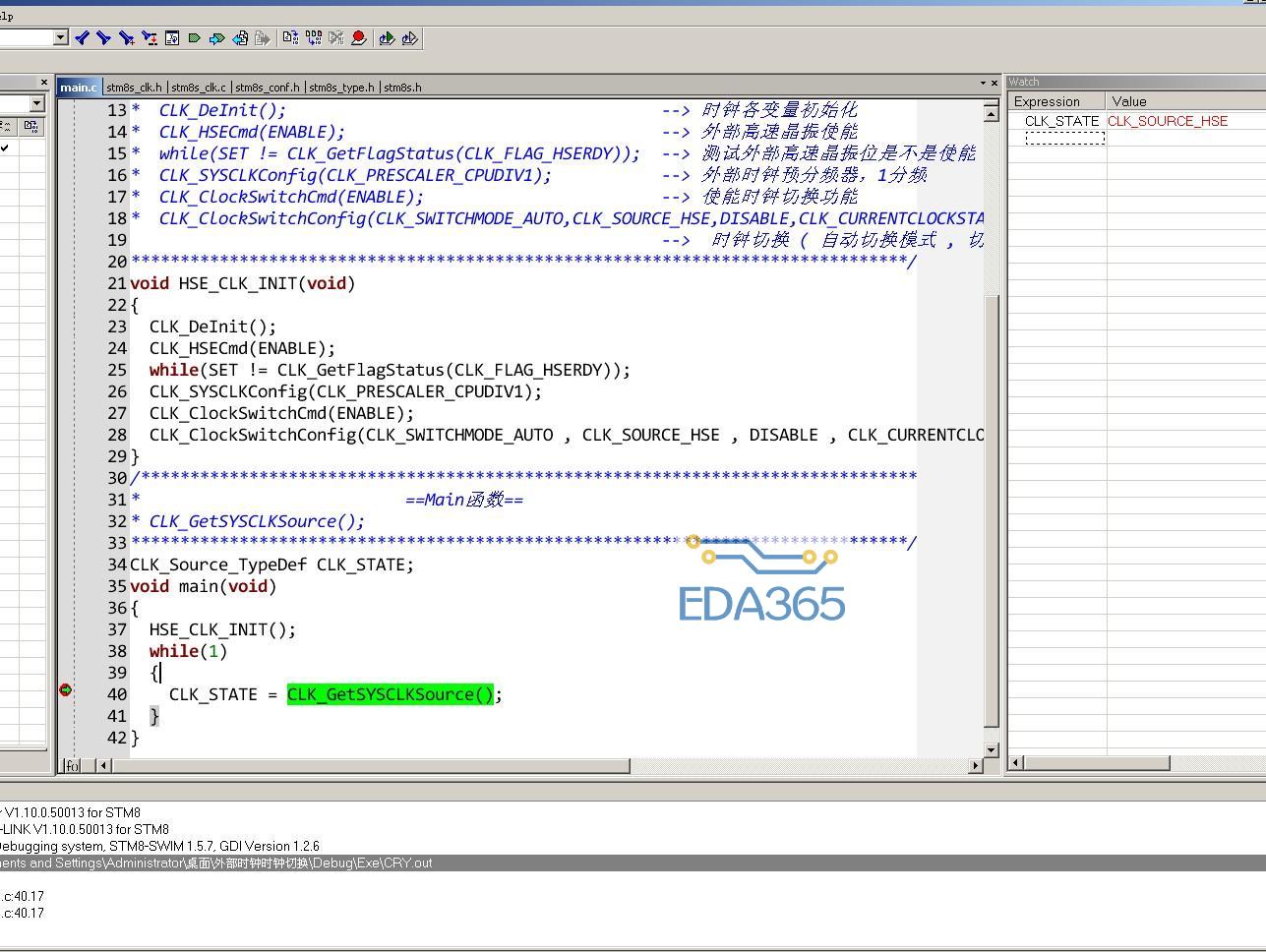
 CC-Link现场总线及应用实例
CC-Link现场总线及应用实例





 APP下载
APP下载 登录
登录







