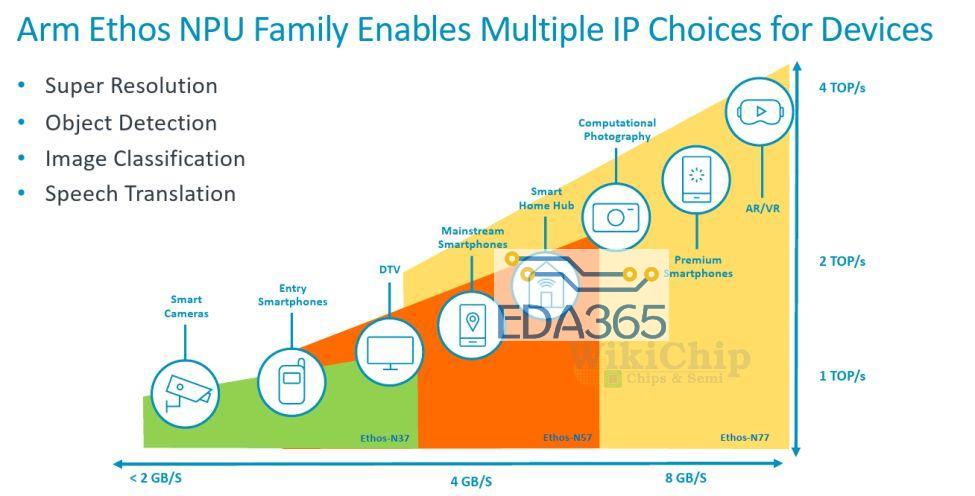
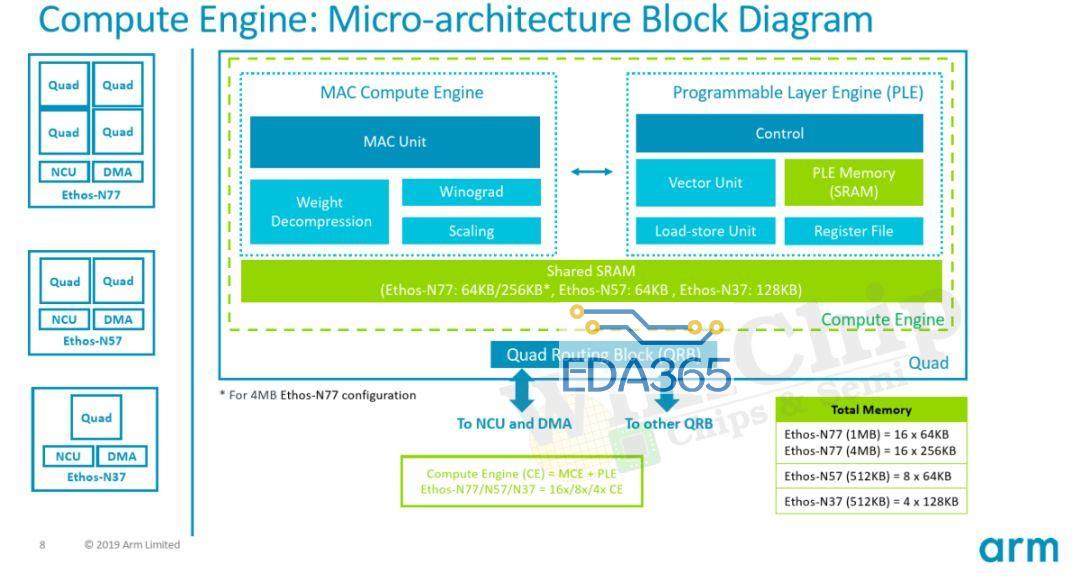
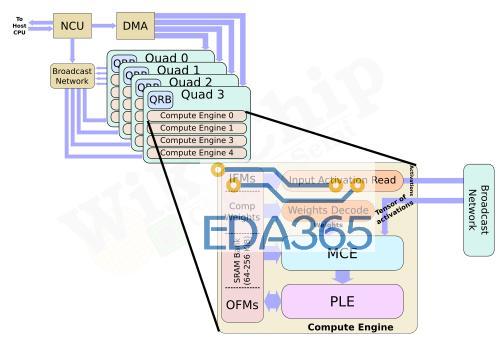
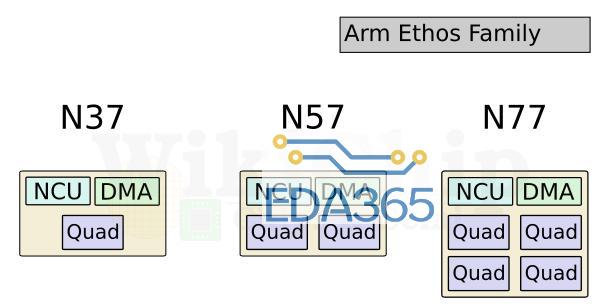
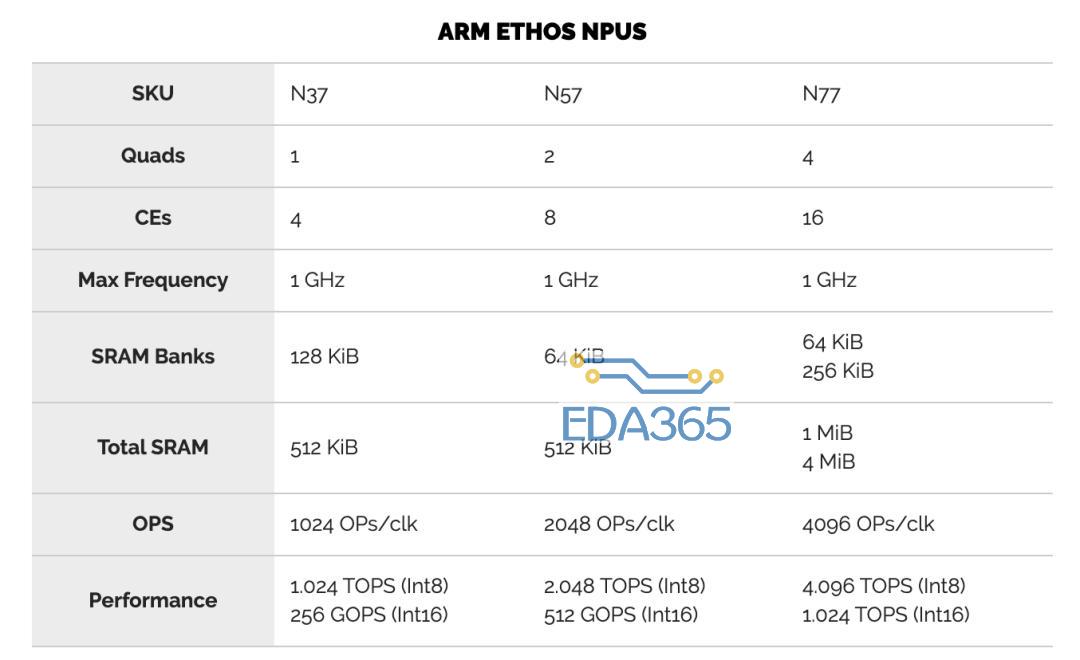
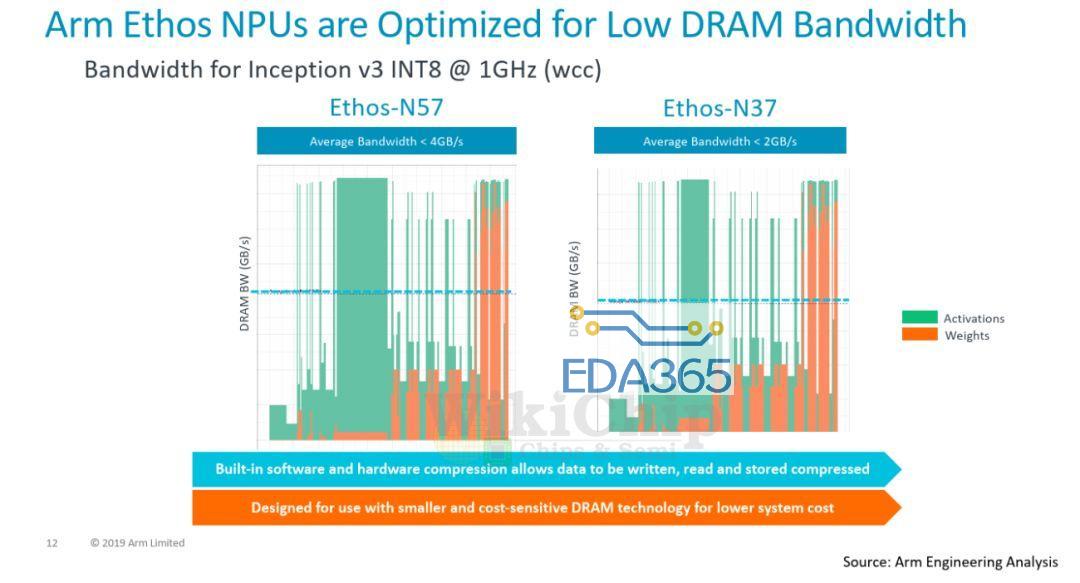
领先的移动SoC设计人员多年来一直在其SoC中集成专用NPU。去年底,Arm也带来了Ethos NPU系列。此举是Arm拓展AI市场的最新举措。该公司在新的Ethos NPU系列下推出了三个初始IPEthos-N37,Ethos-N57和Ethos-N77。这三个初始IP旨在覆盖相当多的设备。顾名思义,每个功能都比前一个功能越来越强大。三个NPU使用相同的微体系结构构建,但配置稍有不同,您将在稍后看到。下面的Arm可视化图描绘了NPU正在工作的各种市场和约束。在低端是Ethos-N37,其目标是工作负载最轻的设备,其峰值计算性能高达大约1 TOPS,而需要很少的DRAM带宽(约为3 GB / s或更低);Ethos-N57涵盖了更复杂的设备,例如大多数智能家居设备以及一些主流智能手机SoC。N57设计为具有更高的内存带宽,并可以提供大约2 TOPS的性能;最后是Ethos-N77。这是系列中最强的产品,目标是性能高达4 TOPS的市场,并且具有约5 TOPS / W的较高功率效率。N77专为高级和中端AR / VR设备而设计,尽管它具有性能增强功能,但您仍需要更强大的功能。为了获得更高的性能,需要更高的内存带宽(内存带宽需要高达8 GB / s甚至更高)。值得指出的是,这三个IP之间有很多重叠。N57可以覆盖N37范围的上部以及N77范围的下半部分。与N77相同。这为SoC设计人员提供了一些摆动空间,使其可以进行自己的设计。值得指出的是,这三个IP之间有很多重叠。N57可以覆盖N37范围的上部以及N77范围的下半部分。与N77相同。这为SoC设计人员提供了一些空间,使其可以进行自己的设计。Ethos系列的核心是Arm的ML处理器(MLP)。MLP是一种干净的(clean-sheet ),底层(ground-up)的微体系结构,用于加速机器学习,重点是CNN和RNN。MLP实际上使用了相当简单的设计,这正是我们期望将出售给设计人员的IP中所期望的。MLP的主要组件是控制单元,DMA,广播网络和计算引擎。您可能已经猜到了,主要动作发生在计算引擎中。四个计算引擎的每个群集都分组为一个“四元组”。控制单元协调整个计算引擎以及DMA引擎的整个神经网络执行,该DMA引擎了解神经网络映射并可以确保数据在需要时到达。我们可以以多种配置来实现MLP。两个主要控制是每个计算引擎中的SRAM库大小和计算引擎的数量。对于他们当前的设计,MLP可以具有从 从单个四核中的单个计算引擎到带有十六个计算引擎的四个四核等多个选择。在每个计算引擎中,您都有一块SRAM,用于存储输入和输出特征图以及权重。可以从64 KiB一直配置到256 KiB。无论配置如何,控制单元和DMA始终相同。Ethos-N77本质上是完整的MLP配置。它具有四个quads 和16个计算引擎,并具有两种可能的SRAM配置–:64 KiB或256 KiB。同样,Ethos-N53包含四个quads ,总共八个计算引擎。N53每个CE带有固定的64 KiB SRAM存储区。Ethos-N37是性能最低的SKU,只有一个quad,总共只能容纳四个具有固定的128 KiB容量SRAM库的计算引擎。计算引擎中的两个有趣的组件是MAC计算引擎(MCE)和可编程层引擎(PLE)。MCE包含高效的固定功能MAC单元,而PLE包含灵活的可编程矢量引擎。流程相对简单。输入activation tensor 和权重一起传递到MCE。计算之后,将结果传递到PLE进行后处理和可能需要的其他各种操作。没有复杂的控制,因为其中很多控制权交给了编译器,该编译器执行静态调度,对SRAM库进行预分区并压缩功能图和权重。在MCE内则是一组八个MAC单元。每个MAC单元为16位宽。换句话说,每个MAC单元每个周期可以执行16个8位点积运算(dot product operations )。总体而言,每个计算引擎有256个OP /峰值性能周期。顺便说一下,这里的操作都是8位宽的,累加了32b。MLP确实支持16位操作,但着将使您的吞吐量减少4倍(即,每个周期64个OP)。下表列出了每个Ethos SKU的最高理论性能。当然,实际的工作负载性能将取决于这些MAC的利用率。需要指出的是,所有三个SKU都可以达到相同的1 GHz最大频率。虽然N77的最高TOPS为4.1 TOPS,但实际的SoC并不需要达到该性能水平。相反,可以将MLP的多个实例集成到SoC中,以进一步提高性能。因此,例如,至少在理论上支持使用CCN-500互连最多扩展到八个MLP,而使用更新的CMN-600网格互连最多扩展到100个MLP。除了MCE,计算引擎内的其他主要组件是可编程层引擎(PLE)。PLE实际上比MCE更强大,并且因为它是可编程的而具有更大的灵活性,尽管它在处理数百万次重复的MAC操作时在原始的功率效率竞争中有所损失。PLE是成熟的Cortex-M处理器,在其中还包含了向量和NN扩展。那意味着Ethos-N77在内部合并了16种Cortex-M向量处理器。它采用专用的16通道矢量引擎协处理器模型进行设计。PLE主要设计用于MCE后处理,实现一些不太常见的功能。但是由于这本身就是一个功能强大的矢量引擎,因此在有或没有MCE的帮助下,它实际上都可以直接对SRAM数据进行操作。PLE的可编程性使Arm软件团队能够快速适应新的AI模型和功能。编译器工具链还提供了我们期望现代NPU能做的许多其他优化。由于编译器会提前对SRAM进行分区,因此它会执行激活和权重压缩,这有助于在整个设计中稍微减少带宽。此外,还有针对稀疏性的轻量优化。数据路径将选通为零,从而节省了一点功耗。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』











 热门文章
更多
热门文章
更多

 MSP430单片机硬件知识-复位
MSP430单片机硬件知识-复位







 APP下载
APP下载 登录
登录







