×


指纹识别是自动个人识别技术中使用的最常见、最可靠的技术。大体上,实现的技术将自动指纹识别(AFAS) 划分为在不同时间和不同条件下执行的两个阶段:登记和识别。
登记流程中,用户向系统提供指纹,系统随即执行一系列需要高强度计算的图像处理步骤,以提取所有具有相关性、永久性和独特性的信息,从而使系统明确识别指纹的真正主人。这一系列特性就构成了用户ID(身份识别号码),由系统存储在数据库中。这一过程一般在安全的环境中,在专业人员的指导下离线执行。
指纹识别是查看其是否与数据库中的经认可的用户一致。在登记过程中执行的各种处理工作将反复进行,以从当前指纹采样本中提取出独特的特征。系统随后将这些特征与数据库中存储作为为用户模版的信息进行对比,以确认当前指纹采样是否与登记的模版相符。根据数据库大小,识别分为两种模式:一对一或一对多匹配。识别一般是在安全度较低的环境中,且在实时约束的条件下完成的。
这里的每一步被细分为一系列彼此独立的任务,以从指纹图像中抽取出用户独特的信息。以此为目的,系统将进行一系列具体的运算,如图像处理(2D 卷积、形态学运算)、三角运算(正弦、余弦、反切、开方)[1] 或者统计(平均值、方差)。
因此,生物识别应用是由一系列按顺序流程执行的任务构成的。因为在这个链条上某个给定任务的输出数据是下一项任务的输入数据,一项任务的开始需要等待前一项任务的完成。另外,在登陆阶段和识别阶段,有许多任务是反复执行的。
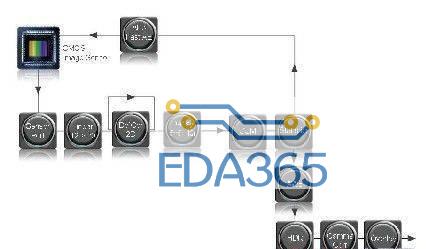
图1列举了目前算法中发生的任务。第一项是图像获取。根据传感器的尺寸,系统可以一次性地获得整个图像(全图像传感器),也可以分片获取(扫描传感器)。在第二种情况下,即我们正在使用的这种情况,需要额外经过一次图像重构阶段。完整的指纹图像是由连续且部分重叠的图像条所组成的[2]。
我们获得整个重构的图像之后,下一步是在背景中对前景(即指纹皮肤的凸凹形成的关注区域)分割。我们采用由 5x5 像素的 Sobel边缘检测滤波器逐像素完成图像卷积。完成后,我们以特定的均值和方差进行图像标准化。
下一步,我们通过各向同性滤波来增强标准化图像。该步骤使用 13x13 像素,从之前在采集阶段因噪声而导致图像丢失或者干扰的图像区域恢复相关信息[3]。图像强化步骤完成之后的下一步是计算指纹矢量图 (field orientation map),以确定图像前景中脊线和谷线的主要方向。生成的方向场 (eld orientation) 随后被提交给新的滤波步骤(5x5像素),以获得精细化的矢量图。
此时图像仍为 8 位灰度。在二值化处理中,由 7x7 像素的 Gabor 方向滤波器进行灰度图像卷积,以提升脊线和谷线的清晰度,并把每个灰度像素转化为 1 位二进制(黑或白)点。合成的脊线和谷线图像再次进行经过平滑处理和重绘。随后,通过细化或骨架化,将黑白图像的黑色走线变为一个像素宽。从这个图像上不难提取指纹的特性或者细节,即纹线端点和纹线分叉点。
最后,在获取到指纹细节和方向场数据后,就可以进行指纹模板和样本的对比。这里采用一种比较直接的算法,在考虑到转换和旋转动作以及采集阶段因皮肤弹性导致的图像变形引起的误差可接受的情况下,让两者实现最理想的重合[4]。下一步是进行样本和模板的匹配,获知两者之间的相似度,随后自动化系统可以根据相似度来确定两个图像是否属于同一人[5]。
在如图3所示的整个处理过程中,使用的指纹图像分辨率为 500dpi,灰度为 8 位,图像大小为 280x512 像素。图像获取采用的是Atmel公司的热敏指纹传感器 FingerChip 扫描技术,运算采用的是赛灵思 Virtex-4 XC4VLX25 FPGA 器件。
系统架构
Virtex-4 FPGA 器件是 AFAS 平台的计算单元,其中采用 Flash(闪存)作为系统数据库,存储FPGA配置数据,以及如用户指纹模板或生物识别算法配置设置等特定于应用的数据。此外,该系统还使用 DDR-SDM 存储器来暂时保存从每个处理阶段中获得的中间数据或图像。我们采用的是串行通信,在我们的案例中是连接至 UART 控制器的 RS-232 收发器 — 后者可在 FPGA 资源中进行综合 — 以用于调试目的。其目的是将每个阶段生成的结果图像传输到 PC 上,以便以图形化的方式察看每步的指纹图像或者结果。最后,使用扫描式指纹传感器来获取用户的生物识别特性,并作为识别算法的输入,如图 2 所示。
作为计算单元,FPGA 被划分为两个区域,一个是静态区,由完整的多处理器 CoreConnect 总线系统构成;另一个是可重配置区,用于根据需要放置定制的生物识别协处理器或IP(知识产权),以执行识别算法的各种顺序任务,并随处理的进展进行复用。多处理器 CoreConnect 总线系统主要由赛灵思 MicroBlaze 处理器及其它标准外设构成,同时还拥有一个链接至 ICAP (内部配置访问通道)端口的重配置控制器。
如图1所示,所有的处理任务都按照顺序执行的次序从 0(静态)到 B 进行枚举。定制的硬件协处理器负责在 PRR (部分重配置区域)中实现所有的任务,由 MicroBlaze 在软件中完成的指纹采集过程除外。
软硬件特定的划分是由于扫描传感器需要 5μs的积分时间来获得连续的图像条(SLICE)。这种速度下无需采用定制的硬件协处理器,采用MicroBlaze软件采集和重构图像不仅速度足够,而且更简单经济。
图像采集按每个 SLICE 5μs的速率采集 100 个SLICE,每个 SLICE 的大小为 280x8 像素。每两个连续的图像 SLICE 之间的像素重叠部分交由软件进行探测,从而完成图像的实时重构。
由于实时的要求,剩余的任务我们交由 FPGA 的 PRR 的定制硬件协处理器来实现。一旦每个特定的任务完成之后,位于器件静态区的重配置控制器在 MicroBlaze 处理器的控制下,载入下一个任务的工作模块。重配置控制器通过 ICAP 接口将新模块的配置数据从 DDR-SDM 中直接传输到内部的 FPGA 配置存储器中,从而完成此项任务。
值得一提的是,我们使用的是静态区和可重配置区之间基于 FIFO(先进先出)存储器和触发寄存器构成的标准界面。这样我们就可以在 PRR 中开发标准的生物识别协处理器或 IP,而无需理会系统使用的是哪种多处理器总线,无论其是 AMBA、CoreConnect、Wishbone 还是其它均如此,如图 2 所示。这一点具有根本性的意义,因为这样才能确保生物识别算法跨不同平台的标准化和便携性。
重配置控制器
设计高效的重配置控制器是部署面向单一环境 FPGA 的 PR (部分重配置)系统的成功关键。虽然在重配置 PRR 期间,FPGA 的非重配置区域仍然处于工作状态,但 PRR 资源此时并没有处于工作状态,故应尽量加快重配置过程,以便最大限度地降低开销。重配置的时间取决于三个因素:数据总线宽度、重配置频率以及比特流大小。前两个因素与接口特性有关,而最后一个与 PRR 的大小及其中的部分重配置模块 (PRM) 的设计复杂程度有关。
我们的工作实现了一个重配置控制器,其能在运行时将部分比特流以高带宽从外部存储器传输到 FPGA 的片上配置存储器中。在不限制部分比特流大小,同时将外部存储作为共享资源(各种处理器可通过系统总线同时访问)的条件下,仍然可以达到Virtex-4最高重配置带宽。
在系统初始化阶段,部分比特流将在运行中被下载到 FPGA 配置存储中,并从外部的Flash中传输到外部 DDR-SDRAM。该存储器与多端口存储控制器 (MPMC) 相连接,因而成为系统中任何主从处理器都可以访问的资源。可以使用 CoreConnect PLBv46 总线等不同类型的总线连接到 MPMC,这些总线可用作通用系统总线,而赛灵思 Cachelink (XCL) 总线则用于 CPU 的快速指令和数据缓存。系统 CPU (MicroBlaze) 实际上是与这两个总线相连接的。
不过我们的重配置解决方案是建立在新总线基础之上的,即专用于快速链接外部 DDR-SDRAM 存储库和 ICAP 接口之间的原始端口界面 (NPI)。作为我们重配置控制器的组成部分,我们设计了可用来处理 NPI 协议的主系统存储管理单元 (MMU)。外部 DDR-SDRAM(部分比特流)和 ICAP 原始之间的连接需要经过一个内部 FIFO 存储器。借助这种方法,我们可以实现两个不同的定制界面,它们各自拥有独立的数据总线大小和速度,一个与 NPI 协议耦合,另一个则与 ICAP 协议进行耦合。
FIFO 的写入端口与 NPI 相连接,并使用 64 位数据总线;而 FIFO 的读取端口则连接到 ICAP,使用 32 位数据宽度,这是 ICAP 在 Virtex-4 器件中的最高数据宽度。FIFO 的读取端口和写入端口(在 NPI 侧和 ICAP 侧)的运行频率为 100MHz。为使传输时延降至最低,主系统 MMU 负责以 64 字(32 位)突发传输向内部 FIFO 传输配置数据,从而完成模块的重配置。这是可接受的最大突发长度,因而所有的重配置数据传输都能够以最低突发时延完成。在另一侧,只要 FIFO 不为空,重配置控制器就能读取已存储的 FIFO 数据,并将其以 32 位格式传输给 ICAP 接口。重配置控制器(就是主 MMU)负责处理对大型 DDR-SDM 存储器进行直接存储器存取 (DMA)。为了实现,我们定制了一个从MMU,并在其中设置了多个控制寄存器,将这个MMU挂在PLBv46总线上并由CPU直接控制。
采用这种方式,CPU 仅需做两件事情:配置在 PRR 中下载的部分比特流的初始地址和大小;向主系统 MMU 发出执行指令,以启动重配置过程。而后,主系统 MMU 开始将比特流以 DMA(直接内存存储)的方式直接传输给内部的 FIFO,随后再从该 FIFO 传输给 ICAP 接口。一旦传输完毕,重配置控制器就会通知 CPU。
结果,即使在 CPU 通过 XCL 或 PLBv46 总线访问 DDR-SDRAM 的同时,我们也能实现部分比特流传输的最大吞吐量。其最终原因在于 CPU 在内部 BM(block-M)高速缓存中运行程序流,将对外部 DDS-SDRAM 的访问释放给了重配置控制器。值得重点指出的是,这个为部分比特流和软件应用分配的 DDR-SDRAM 存储器并非专用资源,而是共享资源。即使如此,该方案与其它现有的重配置控制器方案相比性能也有显著的改善,因为其能够实现 Virtex-4的最大重配置吞吐量(通过 32 位数据总线以 100MHz 的频率或 3.2 Gbps 的速率将部分比特流传输给 ICAP)。
实验结果
从本质上讲,文中所述的嵌入式自动指纹识别系统是一种高性能图像处理应用,因为它拥有大量的并行性,且需要实时认证响应。从人机工程角度上讲,此系统可使每位用户的认证时间不超过 2 s或3s。
该设计流程涉及多个开发环路。首先,我们在 PC 平台上的 MATLAB 的软件里开发算法。随后,我们将软件代码用 C 编程语言导入到嵌入式软件中,并且首先在同一 PC 上执行,以确认我们能够获得同样的结果,然后在 FPGA 器件内合成的 MicroBlaze 嵌入式微处理器上执行。
通过这种方式,Virtex-4 器件可在不使用任何定制硬件协处理器和不达到实时性能要求的情况下实施基于 MicroBlaze 的纯软件解决方案。为缩短运行时间,我们根据任务概要,下一步工作是引入 PRR,并在上面构建各种定制生物识别协处理器,使用硬件/软件协同设计解决方案。此刻,我们已经采用 C 编程语言和 VHDL 硬件描述语言完成了此系统的开发工作。
我们采用 268x460 像素的 8 位灰度指纹图像进行了一些识别测试。同时,我们在基于 Virtex-4 的 PR 系统上和运行速度为 1.83GHz 的 Intel Core 2 Duo T5600 处理器的个人电脑上也进行了相同的测试。然后,我们运行相同的算法,包括纯软件实施方式和软硬件混合实施方式,以比较登录和识别阶段的性能。
如果不考虑采集工作(由于扫描传感器的性能限制,需以 5ms 积分时间采集 100 片并在运行中重构图像,故采集时间固定为 500ms),PR 方法可以把运行其他处理任务所形成的延迟降低到 205ms。与在 PC 上运行纯软件方法的 3,274ms 的延迟相比,PR 方法可提高 16 倍速度。
因此,表 1 说明运用并行和流水线技术进行软硬件协同设计,同时配合低重配置延迟的 PR 技术,明显实现实时认证是可行的。另外,在动态重配置时,可以指定模块运行的频率,这个频率是由新模块的特性所决定。在我们的设计中,所有模块运行在50MHz或者100MHz的频率下。
此外,重配置流程一直以 100MHz 运行,在每个时钟周期里传输 32 位比特,从而保证 Virtex-4 上的最低重配置延迟。根据每个 PRR 硬件环境的比特流复杂性,每个重配置流程花费的时间在 0.8ms(例如标准化)和 1.1ms(例如二进制化)之间。与生物识别应用的总体运行时间相比,该重配置时间可忽略不计。
由于我们已经成功完成了概念验证工作,我们准备把原型导出到新一代赛灵思低端具有 PR 功能的 28 纳米FPGA 器件中(Artix-7 系列)。我们的目标是以最低的成本设计出一款能够在任何消费类电子产品中嵌入高性能且真正安全的生物识别系统。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 低成本FPGA集成收发器,市场应用大幅拓展
低成本FPGA集成收发器,市场应用大幅拓展







 APP下载
APP下载 登录
登录







