×


0 引言
与传统的 PCI、PCI-X 并行总线相比[1],PCIe总线采用高速差分串行的方式进行数据传输,这种端到端的数据传送方式使得信号线减少、系统功耗降低,同时还具有非常明显的带宽优势。
目前通过 FPGA 实现 PCIe 接口是一种比较常用的方式,具有硬件成本低、可靠性高、灵活性大、易于升级等优势。两大 FPGA 厂商 Xilinx 和 Altera均具有完善的接口 IP 和测试方法。基于此,笔者主要介绍了基于 Xilinx Virtex5 系列 FPGA 的 PCIe 接口的设计和 DMA 功能的实现方法,并在 x4 模式下进行带宽测试。
1 PCIe 总线简介
PCIe 系统中使用链路(Lane)进行 2 个 PCIe 设备间的物理连接,1 条链路相当于 1 条只挂连 1 个设备的总线,每条链路都分配有链路号。
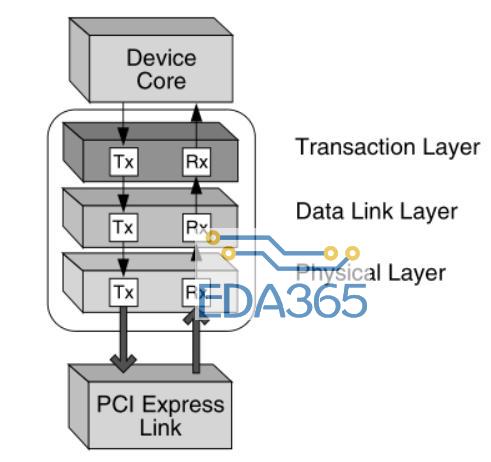
PCIe 体系结构采用分层设计,分别是:物理层(Physical layer)、数据链路层(Data link layer)和事务层(Transaction layer)。物理层是总线的最底层,负责物理接口连接,为数据传输提供可靠的物理环境;数据链路层保证来自发送端事务层的报文可以可靠、完整地发送到接 收端的数据链路层;事务层定义了 PCIe 总线使用的总线事务,这些事务可用于PCIe 系统内各设备间的通信[2]。
目前最新的 PCIe 规范是 V3.0,在这之前有V1.0、V1.1、V2.0、V2.1 等多个版本,不同的规范规定了不同的总线频率和编码方式,如表 1。笔者的设计符合 V1.1 规范。
2 IP 核介绍及参数设置
2.1 IP 核简介
Xilinx PCIe 的 IP 具有高性能、高灵活性、高可靠性等特点,支持 x1、x2、x4、x8 链路宽度。支持链路和极性的错序连接,完全符合 PCIe 的层级模型,包含事务层、数据链路层和物理层。图 1 是 IP核的功能框图及各个接口[3]。
图 1 IP 核功能框图及接口
用户逻辑接口(User logic):用户需要根据该接口编写本地总线逻辑,进而与 IP 核进行通信;
配置接口(Host interface):主机通过该接口对IP 核进行配置或读取状态;
物理层接口(PCI express fabric):通过高速差分信号与桥或根复合体直接进行连接;
系统接口(System):包括时钟和复位信号。
2.2 参数设置
需要设置的参数主要包括:参考时钟、链路宽度、设备 ID、基址寄存器、TLP 大小等。参考时钟一般选择 100 MHz,TLP 大小建议选择最大值
512Byte,链路宽度、设备 ID 可根据实际需求情况进行设置。基址寄存器(BAR)包含设备在总线域使用的地址范围,通常情况下使用 2 到 3 个 BAR 就足够了。其余设置可采用默认设置。图 2、图 3、图4 是部分参数的设置情况。
图 2 设置链路带宽和参考时钟
3 设置基址寄存器(BAR)设置情况
图4 设置最大载荷
3 DMA 功能设计
PCIe 总线的高带宽特性需要通过 DMA 功能来实现,有效且稳定的 DMA 功能是实现 PCIe 总线的关键。
针对 PCIe 接口 Xilinx 提供了多个参考设计。
表 2 PCIe 各参考设计比较情况
笔者介绍的 DMA 功能主要以 XAPP1052 为基础进行设计。图 5 是该参考设计的架构框图。
图 5 XAPP1052 设计架构
主要功能模块说明如下:
目标逻辑(Target logic),用于捕获上位机发出的单次存储器读写 TLP;如果是写 TLP 则根据地址和数据更新控制寄存器中的内容,如果是读 TLP 则根据地址返回控制和状态寄存器中的数据;
控制和状态寄存器(Control/Status register):主要是与 DMA 控制器相关的如 DMA 传输长度、启动 DMA 等寄存器;
初始化逻辑(Initiator logic):与 PCIe 硬核交互,产生存储器读写 TLP。
参考设计 XAPP1052 主要以测试性能为主,设计中并没有目标存储器,无法存储 DMA 测试数据,笔者在 XAPP1052 的基础上增加双口 RAM 存储器,并完成接口逻辑的设计,最后通过测试程序完成上位机与双口 RAM 间的 DMA 读写操作,形成一个完整的 DMA 功能验证模块。
图 6 是 ISE 工程界面的截图,其中双口 RAM的写逻辑在模块 BMD_RX_ENGINE 中产生,读逻辑在模块 BMD_TX_ENGINE 中产生。在 PCIe 总线中,由于 EP 发出的存储器读请求可以超越之前的存储器读请求,而且当存储器完成报文使用的Transaction ID 不同时,存储器读完成 TLP 也可能超越之前的存储器读完成 TLP,这将造成存储器读完成 TLP 的乱序到达 EP[6]。因此在处理 DMA 读时,要针对这种乱序情况做适当处理,需要检查存储器读完成 TLP 的 Requester ID、Status、Tag、Attr 等字段,最后将数据按正确的顺序写入双口 RAM 中,在笔者的设计中,模块 dma_read_reorder 完成的就是这一功能,有效解决了乱序到达的问题。
图 6 ISE 工程界面截图
DMA 读写的操作流程大致分以下几个步骤:
1) 对 DMA 控制器复位,进行初始化操作;
2) 填写 DMA 读(写)的目的地址寄存器;
3) 填写 TLP 大小及数量寄存器,确定传输数据量的大小;
4) 启动 DMA 读(写);
5) 等待并处理 DMA 读(写)完成中断;
6) 回到 1)。
图 7、图 8 分别是 DMA 读和 DMA 写测试情况。
图 7 DMA 读测试情况
8 DMA 写测试情况
由图 7 和图 8 可知,在 X4 模式下 DMA 读和DMA 写的带宽[7]分别达到 554 MB/S 和 881 MB/S。
4 结束语
笔者基于 XAPP1052 参考设计,并增加了用于测试 DMA 数据的存储器控制接口及存储器读完成TLP 检查模块,形成了完整的 DMA 测试功能模块,解决了 DMA 读时数据乱序到达等关键问题,在 X4模式下,DMA 读和 DMA 写的带宽分别达到了 554MB/S 和 881 MB/S,可满足大多数情况的带宽要求。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 USB设备控制器端点缓冲区的优化技术设计
USB设备控制器端点缓冲区的优化技术设计








 APP下载
APP下载 登录
登录







