
尽管以太坊的许多理念在早先的加密货币(如比特币)上已经运用并测试了5年之久,但从处理某些协议功能上来说,以太坊的处理方式与常见方式仍有许多不同。很多时候,以太坊会被用来建立全新的经济方法,因为它具有许多其他系统不具备的功能。本文会详细描述以太坊所有潜在的优点以及在构建以太坊协议过程中某些有争议的地。另外,也会指出我们的方案及替代方案潜在的风险。
原则
以太坊协议的设计遵循以下几点原则:
1.三明治复杂模型
我们认为以太坊的底层协议应尽可能的简单,接口设计应易于理解,那些不可避免的复杂部分应放入中间层。中间层不是核心共识的一部分,且对最终用户不可见,它包含:高级语言编译器、参数序列化和反序列化脚本、存储数据结构模型、leveldb存储接口以及线路协议等。当然,这样的设置也并非绝对。
2.自由
不应限制用户使用以太坊协议,也不应试图优先支持或不支持某些以太坊合约或交易。这一点与“网络中立”概念背后的指导原则相似。比特币交易协议就没有遵循这一原则。在比特币交易协议中,并不鼓励为了“去除标签”而使用区块链(如,数据存储,元协议)。某些情况下,对准协议进行明显修改会引起不法分子以未经授权方式使用区块链来攻击应用。因此,在以太坊,我们强烈建议设置交易费用,且用户使用区块链的步骤越多,交易费用也就越多(类似庇古税)。这样,既可以将交易费用作为合法矿工的奖励,又能让那些不法分子付出代价,一举两得。
3.泛化
以太坊协议的特性和操作码应最大限度地体现低层次的概念(就像基本粒子一样),以便它们可以随意组合。因此,通过剥离那些不需要的功能,使低层次的概念更加高效。遵循这一原则的例子是,我们选择LOG操作码作为向dapps提供信息的方式,而不是像之前那样记录下所有交易和消息信息。在早先,“消息(message)”的概念完完全全是多种概念的集合,它包含“函数调用(function call)”和“外在观察者感兴趣的事情(event interesting to outside watchers)”,而两者是完全可以分离开来的。
4.没有特点就是最大的特性点
为了遵循泛化原则,我们拒绝将那些高级用例内嵌为协议的一部分,哪怕是经常使用的用例,也绝不这么做。如果人们真的想实现这些用例,可以在合约内创建子协议(如,基于以太坊的子货币,比特币/莱特币/狗币的侧链等)。比如,在以太坊中就缺少类似比特币中的“时间锁定”功能。但是,通过以下协议可以模拟出这个功能:用户发送签名数据包到特定的合约中处理,如果数据包在特定合约中有效,则执行相应的函数。
5.没有风险规避机制
如果风险的增加带来了可观的好处,我们愿意承担更高的风险(例如,广义状态转换,区块时间提升50倍,共识效率)。
这些原则指导着以太坊的发展,但它们并不是绝对的;某些情况下,为了减少开发时间或者不希望一次作出过多改变,也会使我们推迟作出某些修改,把它留到将来的版本中去修改。
区块链层协议
本节对以太坊中区块链层协议的改变进行了描述,包括区块和交易是如何工作的、数据如何序列化及存储、账户背后的机制。
账户 ,而非UTXO①
比特币及其许多衍生品,都将用户的余额信息存储在UTXO结构中,系统的整个状态由一系列的“有效的输出”组成(可以将这些“有效的输出”想象成钱币)。每个UTXO都有拥有者和自身的价值属性。一笔交易在消费若干个UTXO同时也会生成若干个新的UTXO。“有效的输出”中有效需满足下面几点约束:
1.每个被引用的输入必须有效,且未被使用过;
2.交易的签名必须与每笔输入的所有者签名匹配;
3.输入的总值必须等于或大于输出的总值。
因此,比特币系统中,用户的“余额”是该用户的私钥能够有效签名的所有UTXO的总和。下图展示了比特币系统中交易输入输出过程:
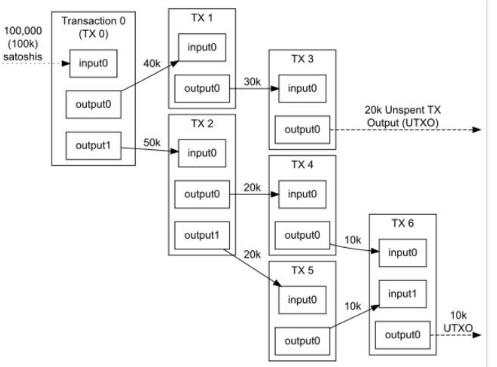
但是,以太坊抛弃了UTXO的方案,转而使用更简单的方法:采用状态(state)的概念存储一系列账户,每个账户都有自己的余额,以及以太坊特有的数据(代码或内部存储器)。如果交易发起方的账户余额足够支付交易费用,则交易有效,那么发起方账户会扣除相应金额,而接受账户则计入该金额。某些情况下,接受账户内有需要执行的代码,则交易会触发该代码的执行,那么账户的内部存储器可能就会发生变化,甚至可能会创建额外的信息发送给其他账户,从而导致新的交易发生。
尽管以太坊没有采用UTXO的概念,但UTXO也不乏有一些优点:
1.较高程度的隐私保护
如果用户每次交易都使用一个新的地址,那么账户之间的相互关联就很困难。这样做适用于对安全性要求高的货币系统,但对任何dapp应用来说就不合适了。因为dapp通常需要跟踪用户复杂的绑定状态,而dapp的状态并不能像货币系统中的状态那样简单地划分。
2.潜在地可扩展性
UTXO在理论上可扩展性更好。因为我们只能依靠那些金融货币拥有者来维护能够证明货币所有权的***树,即使所有的人(包括数据的拥有者)都遗忘了某一数据,真正受损也只有数据的拥有者,其他人不受影响。
在以太坊账户系统中,如果一个账户对应在***树中信息被所有人都丢失了,那么该账户将无法处理任何能够影响它的消息,包括发送给它的消息,它也无法处理。
不过,并非只有UTXO能够可扩展,也存在不依赖UTXO就能扩展的方式(此处没有扩展开来讲,译者注)。
账户的好处有以下几点:
1.节省大量空间
如果一个账户有5个UTXO,则从UTXO模式转成账户模式所需空间会从300字节降到30字节。具体计算如下:
300 = (20+32+8)* 5 (20是地址字节数,32是TX的id字节数,8是交易金额值字节数);
30 = 20 + 8 + 2 ( 20是地址字节数,8是交易金额值字节数,2是nonce②字节数)
但实际节约并没有这么大,因为账户需要被存储在帕特里夏树中。另外以太坊中交易也比比特币中的更小(以太坊中100字节,比特币中200-250字节),因为每次交易只需要生成一次引用,一次签名,以及一个输出。
2.可替代性更高
在UTXO结构中,“有效输出”的源码实现中没有区块链层的概念,所以不管是在技术还是法律上,通过建立一个红名单/黑名单,并依据的这些“有效输出”的来源区分它们并不是很实际。
3.简单
以太坊编码更简单、更易于理解,尤其是在涉及到复杂脚本时。尽管任何去中心化应用都可以用UTXO方式来实现,但这种方式实质上是通过赋予一个脚本限制给定的UTXO能够使用以及请求的UTXO的种类的方式来实现,包括脚本评估的应用更改根状态的***树证明。因此,UTXO实现方式比以太坊使用账户的方式要复杂的多。
4.轻客户端
轻客户端可以随时通过沿指定方向扫描状态树来访问与账户相关的所有数据。在UTXO方式中,引用随着每个交易的变化而变化,这对于长时间运行并使用了上文提到的UTXO根状态传播机制的dapp应用来说,无疑是繁重的。
我们认为,账户的好处大大超过了其他方式,尤其是对于我们正在处理的包含任意状态和代码的dapp应用而言。另外,本着“没有特点就是最大的特点”的指导原则,我们认为如果用户真的关心私密性,则可以通过合约中的签名数据包协议来建立一个加密“混合器”进行加密。
账户方式的一个弱点是:为了阻止重播攻击,每笔交易必须有nonce,这就使得账户需要跟踪nonce的使用情况,并且只有在nonce最后使用后且值为1时才接受交易。这就意味着,即使不再使用的账户,也不能从账户状态中移除。解决这个问题的一个简单方法是让交易包含一个区块号,使它们在几个时间段内不重复,并且每个时间段重置nonce。由于完全扫描账户的开销太大,所以为了删除未使用的账户,矿工或用户需要通过“Ping”操作来实现。在1.0上我们没有实现这个机制,1.1及以上版本可能会使用这个机制。
***帕特里夏树
***帕特里夏树(Merkle Patricia tree/trie),由Alan Reiner提出设想,并在瑞波协议中得到实现,是以太坊的主要数据结构,用于存储所有账户状态,以及每个区块中的交易和收据数据。MPT是***树和帕特里夏树的结合缩写,结合这两种树创建的结构具有以下属性:
1.每个唯一键值对唯一映射到根的hash值;在MPT中,不可能仅用一个键值对来欺骗成员(除非攻击者有~2^128 的算力);
2.增、删、改键值对的时间复杂度是对数级别。
MPT为我们提供了一个高效、易更新、且代表整个状态树的“指纹”。
关于MPT更详细描述:https://github.com/ethereum/wiki/wiki/Patricia-Tree
MPT的具体设计决策如下:
1.有两类节点
KV节点和离散节点。KV节点的存在提高了效率,因为如果在特定区域树是稀疏的,KV节点可作为一个“快捷方式”,代替深度为64的树。
2.离散节点是16进制,不是二进制
这样让查找更有效率,我们现在认识到这种选择并不理想,因为16进制树的查找效率在二进制中可以通过批次存储节点来模拟。MPT树的结构实现是非常容易出错的,最终至少会造成状态根不匹配。
3.空值(empty value)与非会员(non-membership)之间没有区别
这样做是为了简化逻辑,以太坊中未设置的值默认为0,空字符串也用0表示。然而,需要强调的是,这样做牺牲了一些通用性,因而也不是最优的。
4.终节点和非终节点的区别
技术上,标识一个节点“是否是终节点”是没必要的,因为以太坊中所有的树都被用于存储静态秘钥长度,但为了增加通用性,我们还是会添加这个标识,以期望以太坊的MPT的实现方式能够被其他加密货币原样采纳。
5.在安全树中采用SHA3(k)作为秘钥(在状态树和账户存储树中使用)
使用SHA3(k),通过设置离散节点的链的深度为64,以及反复调用SLOAD 和 SSTORE指令,使那些企图对树采取Dos攻击的行为变得非常困难。不过,这也让穷举树的节点变得困难,如果你希望你的客户端有穷举的能力,最简单的方法是维持一个数据库映射:sha3(k) -》 k
RLP
RLP(recursive length prefix):递归长度前缀。
RLP编码是以太坊中主要的序列化格式,它的使用无处不在:区块、交易、账户状态以及线路协议消息。详见RLP正式描述: https://github.com/ethereum/wiki/wiki/RLP
RLP旨在成为高度简化的序列化格式,它唯一的目的是存储嵌套的字节数组③。不同于protobuf、BSON等现有的解决方案,RLP并不定义任何指定的数据类型,如Boolean、floa、double或者integer。它仅仅是以嵌套数组的形式存储结构,并将其留给协议来确定数组的含义。RLP也没有明确支持map集合,半官方的建议是采用 [[k1, v1], [k2, v2], 。..] 的嵌套数组来表示键值对集合,k1,k2 。.. 按照字符串的标准排序。
与RLP具有相同功能的方案是protobuf或BSON,它们是一直被使用的算法。然而,以太坊中,我们更偏向于使用RLP,因为:
1.它易于实现;
2.绝对保证字节的一致性。
许多语言的Map集合没有明确的排序,并且浮点格式有很多特殊情况,这可能造成相同数据却导致不同编码和hash值。通过内部开发协议,我们能确保它是带着这些目标设计的(这是一般原则,也适用于代码的其他部分,如VM)。BitTorrent使用的编码方式bencode也许可以替代RLP。不过它采用的是十进制的编码方式,与采用二进制的RLP相比,稍微逊色了点。
压缩算法
线路协议和数据库都采用了一个自定义的压缩算法来存储数据。该算法可描述为:行程编码④值为0并同时保留其他值(除了一些特殊情况如sha3(‘ ’) ),举例如下:
》》》 compress(‘horse’)
‘horse’
》》》 compress(‘donkey dragon 1231231243’)
‘donkey dragon 1231231243’
》》》 compress(‘\xf8\xaf\xf8\xab\xa0\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xbe{b\xd5\xcd\x8d\x87\x97’)
‘\xf8\xaf\xf8\xab\xa0\xfe\x9e\xbe{b\xd5\xcd\x8d\x87\x97’
》》》 compress(“\xc5\xd2F\x01\x86\xf7#《\x92~}\xb2\xdc\xc7\x03\xc0\xe5\x00\xb6S\xca\x82‘;{\xfa\xd8\x04]\x85\xa4p”)
‘\xfe\x01’
压缩算法存在之前,以太坊协议的许多地方都有一些特殊情况,例如,sha3经常被覆盖,所以sha3(‘ ’)=‘ ’,这样不需要在账户中存储代码,可以节省64字节。然而,最近所有这些使得以太坊数据结构变得臃肿的特殊情况都被删除了,取而代之的是将数据保存函数添加到区块链协议之外的层,也就是将其放入线路协议以及将其插入用户数据库实现。这样增加了模块化能力,简化了共识层,使得压缩算法能持续更新以便相对容易部署。
树(trie)的使用
以太坊区块链中每个区块头都包含指向三个树的指针:状态树、交易树、收据树。
状态树代表访问区块后的整个状态;
交易树代表区块中所有交易,这些交易由index索引作为key;(例如,k0:第一个执行的交易,k1:第二个执行的交易)
收据树代表每笔交易相应的收据。交易的收据是一个RLP编码的数据结构:
[ medstate, gas_used, logbloom, logs ]
其中:
• medstate:交易处理后,树的根的状态;
• gas_used:交易处理后,gas的使用量;
• logs:是表格[address, [topic1, topic2.。.], data]元素的列表。表格由交易执行期间调用的操作码LOG0 。.. LOG4 生成(包含主调用和子调用);address 是生成日志的合约的地址topics是最多4个32字节的值;data 是任意字节大小的数组;
• logbloom:交易中所有logs的address和topic组成的布隆过滤器⑤。
区块头中也存在一个布隆过滤器,它是区块中交易的所有布隆过滤器的逻辑或组成。这样的构造使得以太坊协议轻客户端的使用尽可能的友好。
Uncle块(过时区块)的奖励
2013年10月,由乔森纳和特拉维夫首次提出的GHOST协议是一项不起的革新。它是加快生成区块时间的第一个认真尝试。因为区块在网络中传播需要一定时间,如果矿工A挖到一个区块并向全网广播,在广播的路上,B也挖出了区块,那么B的区块是过时的,且B的本次挖矿对网络的安全没有贡献。GHOST的目的正是要解决挖矿过时造成的安全性降低的问题。
此外,还有一个中心化问题:如果A是一个矿池,有30%的算力,B有10%的算力。A有70%的时间产生过时的区块(因为另外的30%时间会产生最新区块,所以它会立即挖到数据),而B有90%的时间产生过时区块。如果区块的产出时间间隔很短,那么过时率就会变高,则A凭借其更大的算力使挖矿效率也更高。所以,区块生成过快,容易导致网络算力大的矿池控制挖矿过程。
根据乔森纳和特拉维夫的描述,GHOST解决了在计算哪个链是最长的链的过程中,因产生过时区块而造成的网络安全性下降的问题。也就是说,不仅是父区块和更早的区块,同时Uncle区块⑥也被添加到计算哪个块具有最大的工作量证明中去。
为了解决第二个问题:中心化问题,我们采用不同的策略:对过时区块也提供区块奖励:挖到过时区块的奖励是该区块基础奖励的7/8;挖到包含过时区块的nephew区块将收到1/32的基础奖励作为赏金。但是,交易费并不奖励给Uncle区块或nephew区块。
在以太坊,过时分叉上7代内的亲属区块才能称作过时区块。之所以这样限制是因为,首先,GHOST协议若不限制过时区块数量,将会花费大量开销在计算过时区块的有效性上;其次,无限制的过时区块激励政策会让矿工失去在主链上挖矿的热情;最后,计算表明,过时区块奖励政策限制在7层内提供了大部分所需的效果,而且不会带来负面效应。
区块时间算法的设计决策包括:
• 区块时间12s:选择12s是因为这已经是最快的时间了,基本上比网络延迟更长。在2013年的一份关于测量比特币网络延迟的论文中,确定了12.6秒是新产生的区块传播到95%节点的时间;然而,该论文还指出传播时间与区块大小成比例,因此在更快的货币中,我们可以期待传播时间大大减少。传播间隔时间是恒定的,约为2秒。然而,为了安全起见,在我们的分析中,我们假定区块的传播需要12秒。
• 7个祖先块的限制:这样设计的目的是希望只保留少量区块,而将更早之前的区块清除。已经证明7个区块可以提供大部分所需的效果。
• 1个后裔区块的限制:如c(c(p(p(p(head))))) c=child, p = parent,就不合法,因为它有两个后裔区块。这样设计的目的是为了简单,上面的模拟结果显示它并没有构成大的中心化风险。
• **uncle块要求具有有效性: **uncle块必须是有效的header,而不是有效的区块。这样做也是为了简化,将区块链模型保持为线性数据结构。不过,要求uncle块是有效的区块也是合法的方法。
• 奖金分配:7/8的挖矿基础奖励分配给uncle块,1/32分给nephew块,它们交易费用都是0%。如果费用占多数,从中心化的角度看,这会使uncle块激励机制无效;然而,这也是为什么只要我们继续使用PoW,以太坊就会不断发行以太币的原因。
难度更新算法
目前以太坊通过以下规则进行难度更新:
diff(genesis) = 2^32
diff(block) = diff.block.parent + floor(diff.block.parent / 1024) *
1 if block.timestamp - block.parent.timestamp 《 9 else
-1 if block.timestamp - block.parent.timestamp 》= 9
难度更新规则的设计目标如下:
• 快速更新:区块间的时间应该随着hash算力的增减而快速调整;
• 低波动性:如果Hash算力恒定,那么难度不应剧烈波动;
• 简单:算法的实现应相对简单;
• 低内存:算法不应依赖于过多的历史区块,要尽可能少的使用”内存变量“。假设有最新的十个区块,将存储在这十个区块头部的内存变量相加,这些区块都可用于算法的计算;
• 非开发性:算法不应让矿工有过多篡改时间戳或者矿池、反复添加或删除算力的能力,以使他们的收益最大化。
我们当前的算法在低波动性和非开发性上并不理想,至少我们计划切换时间戳比较父区块和祖父区块,所以矿工只有在连续挖2个区块时,才有动力去修改时间戳。另一个更强大的模拟公式: https://github.com/ethereum/economic-modeling/blob/master/diffadjust/blkdiff.py
Gas和费用
比特币中所有交易大体相同,因此它们的网络成本可以建成一个模型。以太坊中的交易要更复杂,所以交易费用需要考虑到账户的许多方面,包括宽带费用,存储费用和计算费用。尤其重要的是,以太坊编程语言是图灵完备的,所以交易会使用任意数量的宽带、存储和计算成本。这就可能会导致在计算成本过程中,突遭停电而计算被迫中止。
以太坊交易费用的基本机制如下:
• 每笔交易必须指明一定数量的gas(即指定startgas的值),以及支付每单元gas所需费用(即gasprice),在交易执行开始时,startgas * gasprice 价值的以太币会从发送者账户中扣除;
• 交易执行期间的所有操作,包括读写数据库、发送消息以及每一步的计算都会消耗一定数量的gas;
• 如果交易执行完毕,消耗的gas值小于指定的限制值,则交易执行正常,并将剩余的gas值赋予变量gas_rem ; 在交易完成后,发送者会收到返回的gas_rem * gasprice 价值的以太币,而给矿工的奖励是(startgas - gas_rem)* gasprice价值的以太币;
• 如果交易执行中,gas消耗殆尽,则所有的执行恢复原样,但交易仍然有效,只是交易的唯一结果是将 startgas * gasprice 价值的以太币支付给矿工,其他不变;
• 当一个合约发送消息给另一个合约,可以对这个消息引起的子执行设置一个gas限制。如果子执行耗尽了gas,则子执行恢复原样,但gas仍然消耗。
上述提到的几点都是必须满足的,例如:
• 如果交易没有指定gas限制,那么恶意用户就会发送一个有数十亿步循环的交易。没有人能够处理这样的交易,因为处理这样的交易花的时间可能很长很长,从而无法预先告知网络上的矿工,这会导致拒绝服务的漏洞产生。
• 替代严格的gas计数、时间限制等机制的方案不起作用,因为它们太主观了
• startgas * gasprice 的整个值,在开始时就应该设置好,这样不至于在交易执行中因gas不够而造成交易终止。注意,仅仅检查账户余额是不够的,因为账户可以在其他地方发送余额。
• 如果在gas不够的情况下,交易执行没有恢复操作(回滚),合约必须采用强有力的安全措施来防止合约发生变化。
• 如果子限制不存在,则恶意账户会通过与其他账户达成协议来对它们采取拒绝服务攻击。在计算开始时插入一个大循环,那么发送消息给受害合约或者受害合约的任何补救尝试,都会使整个交易死锁。
• 要求交易发送者而不是合约来支付gas,这样大大增加了开发人员的可操作性。以太坊早期的版本是由合约来支付gas的,这导致了一个相当严重的问题:每个合约必须实现“守护”代码,确保每个传入的消息有足够的以太币供其消耗。
gas消耗计算有以下特点:
• 对于任何交易,都将收取21000gas的基本费用。这些费用可用于支付运行椭圆曲线算法所需的费用。该算法旨在从签名中恢复发送者的地址以及存储交易所花费的硬盘和带宽空间。
• 交易可以包括无限量的“数据”。虚拟机中的某些操作码,可以让合约允许交易对这些数据的访问。数据的固定消耗计算是:每个零字节4gas,非零字节68gas。这个公式的产生是因为合约中大部分的交易数据由一些列的32字节的参数组成,其中多数参数具有许多前导零字节。该结构看起来似乎效率不高,但由于压缩算法的存在,实际上还是很有效率的。我们希望此结构能够代替其他更复杂的机制:这些机制根据预期字节数严格包装参数,从而导致编译阶段复杂性大增。这是三明治复杂模型的一个例外,但由于成本效益比,这也是合理的模型。
• 用于设置账户存储器的操作码SSTORE的消耗是:1.将零值改为非零值时,消耗20000gas;2.将零值变成零值,或非零值变非零值,消耗5000gas;3.将非零值变成零值,消耗5000gas,加上交易执行成功后退回的20000gas。退款金额上限是交易消耗gas总额的50%。这样设置会激励人们清除存储器。我们注意到,正因为缺乏这样的激励,许多合约造成了存储空间没有被有效使用,从而导致了存储快速膨胀;为存储收取费用提供了很多好处,同时不会失去合约一旦确立就可以永久存在的保证。延迟退款机制是必要的,因为可以阻止拒绝服务攻击。攻击者发送一笔含有少量gas的交易,循环清除大量的存储,直到用光gas,这样消耗了大量的验证算力,但实际并没有真正清除存储或消耗大量gas。50%的上限的是为了确保获得了一定交易gas的旷工依然能够确定执行交易的计算时间的上限。
• 合约提供的消息的数据是没有成本的。因为在消息调用期间不需要实质复制任何数据,调用数据可以简单地视为指向父合约内存的指针,该指针在子进程执行时不会改变。
• 内存是一个可以无限扩展的数组,然而,每扩展32字节的内存就会消耗1gas的成本,不足32字节以32字节计。
• 某些操作码的计算时间极度依赖参数,gas开销计算是动态变化的。例如,EXP的的开销是指数级别的;复制操作码(如:CALLDATACOPY, CODECOPY, EXTCODECOPY)的开销是1+1(每复制32字节)。内存扩展的开销不包含在这里,因为它触发了二次攻击。
• 如果值不是零,操作码CALL会额外消耗9000gas。这是因为任何值传输都会引起归档节点的历史存储显著增大。请注意,实际消耗是6700,在此基础上,我们强制增加了一个自动给予接受者的gas值,这个值最小2300。这样做是为了让接受交易的钱包至少有足够的gas来记录交易。
gas机制的另一个重要部分是gas价格本身体现出的经济学原理。比特币中,默认的方法是采取纯粹自愿的收费方式,矿工扮演守门人的角色并且动态设置收费的最小值。以太坊中允许交易发送者设置任意数目的gas。这种方式在比特币社区非常受欢迎,因为它是“市场经济”的体现:允许矿工和交易者之间依据供需关系来决定价格。然而,这种方式的问题是,交易处理并不遵循市场原则。尽管可以将交易处理看作是矿工向发送者提供的服务(这听起来很直观),但实际上矿工所处理的每个交易都必须由网络中的每个节点处理,所以交易处理的大部分成本都由第三方机构承担,而不是决定是否处理它的矿工。
当前,因为缺乏矿工在实际中的行为的明确信息,所以我们将采取一个非常简单公平的方法:投票系统,来设定gas限定值。矿工有权将当前区块的gas限定值设定在最后区块的gas限定值的0.0975% (1/1024)内。所以最终的gas限定值应该是矿工们设置的中间值。我们希望将来能够采用软分叉的方法来使用更加精确的算法。
虚拟机
以太坊虚拟机是执行交易代码的引擎,也是以太坊与其他系统的核心区别。请注意,虚拟机应该同“合约与消息模型”分开考虑。例如,SIGNEXTEND操作码是虚拟机的一个功能,但实际上“某个合约调用其他合约并指定子调用的gas限定值”是“合约与消息模型”的一部分。 EVM的设计目标如下:
• 简单:操作码尽可能的少并且低级;数据类型尽可能少;虚拟机的结构尽可能少;
• 结果明确:在VM规范语句中,没有任何可能产生歧义的空间,结果应该是完全确定的。此外,计算步骤应该是精确的,以便可以测量gas的消耗量;
• 节约空间:EVM组件应尽可能紧凑;
• 预期应用应具备专业化能力:在VM上构建的应用应能处理20字节的地址,以及32位的自定义加密值,拥有用于自定义加密的模数运算、读取区块和交易数据与状态交互等能力;
• 简单安全:为了让VM不被利用,应该能够容易地让建立一套gas消耗成本模型的操作;
• 优化友好:应该易于优化,以便即时编译(JIT)和VM的加速版本能够构建出来。
同时EVM也有如下特殊设计:
• 临时/永久存储的区别:
我们先来看看什么是临时存储和永久存储。
临时存储:存在于VM的每个实例中,并在VM执行结束后消失;
永久存储:存在于区块链状态层。
假设执行下面的树(S代表永久存储,M代表临时存储):
1.A调用B;
2.B设置B.S[0]=5,B.M[0]=9 ;
3.B调用C;
4.C调用B。
此时,如果B试图读取B.S[0],它将得到B前面存入的数据,也就是5;但如果B试图读取B.M[0],它将得到0,因为B.M是临时存储,读取它的时候是虚拟机的一个新的实例。
在一个内部调用中,如果设置B.M[0] = 13和 B.S[0] = 17 ,然后内部调用和C的调用都终止,再执行B的外部调用,此时读取M,将会看到B.M[0] = 9(此值在上一次同一VM执行实例中设置的),B.S[0] = 17。如果B的外部调用结束,然后A再次调用B,将看到B.M[0] = 0,B.S[0] = 17。这个区别的目的是:1.每个执行实例都分配有内存空间,不会因为循环调用而减损,这让安全编程更加容易。2.提供一个能够快速操作的内存形式:因为需要修改树,所以存储更新必然很慢。
• 栈/内存模式
早期,计算状态有三种:栈(stack,一个32字节标准的LIFO),内存(memory,可无限扩展的临时字节数组),存储(storage,永久存储)。在临时存储端,栈和内存的替代方案是memory-only范式,或者是寄存器和内存的混合体(两者区别不大,寄存器本质上也是一种内存)。在这种情况下,每个指令都有三个参数,例如:ADD R1 R2 R3: M[R1] = M[R2] + M[R3] 。选择栈范式的原因很明显,它使代码缩小了4倍。
• 单词大小32字节
在大多数结构中,如比特币,单词大小是4或8字节。4或8字节对存储地址或加密计算来说局限性太大了。而太大的值又很难建立相应安全的gas模型。32字节是一个理想大小,因为它足够存储下许多加密算法的实现以及地址,又不会因为太大而导致效率低下。
• 我们有自己的虚拟机
我们的虚拟机使用java、Lisp或Lua等语言开发。我们认为开发一款专业的虚拟机是值得的,因为:
1. 我们的VM规范比其他许多虚拟机简单的多,因为其他虚拟机为复杂性付出的代价更小,也就是说它们更容易变得复杂;然而,在我们的方案中每额外增加一点复杂性,都会给集约化发展带来障碍,以及潜在的安全缺陷,比如造成共识失败,这就让我们的复杂性成本很高,因而不容易造成复杂;
2. 我们的VM更加专业化,如支持32字节;
3. 我们不会有复杂的外部依赖,复杂的外部依赖会导致我们安装失败;
4. 完善的审查机制,可以具体到特殊的安全需求;对外部VM而言,这一点无论如何都是必要的。
• 使用了可变、可扩展的内存大小
固定内存的大小是不必要的限制,太小或太大都不合适。如果内存大小是固定的,每次访问内存都需要检查访问是否超出边界,显然这样的效率并不高。
• 栈大小没有限制
没什么特别理由!许多情况下,该设计不是绝对必要的;因为,gas的开销和区块层gas的限制总是会充当每种资源消耗的上限。
• 1024调用深度限制
许多编程语言在栈的深度过大时触发中断比在内存过载时触发中断的策略要快的多。所以区块中gas限制所隐含的限制是不够的。
• 无类型
为了简单起见,可以使用DIV, SDIV, MOD, SMOD的有符号或无符号的操作码代替(事实证明,对于操作码ADD和MUL,有符号和无符号是对等的);转换成定点运算在所有情况下都很简单,例如,在32位深度下,a * b -》 (a * b) / 2^32, a / b -》 a * 2^32 / b ,+, - 和 * 在整数下不变。
VM中某些操作码的函数和作用很容易理解,但也有一些不太好理解,以下是一些特殊的原因:
*• ADDMOD, MULMOD *
大多数情况下,addmod(a, b, c) = a * b % c,但在椭圆曲线算法中,使用的是32字节模数运算,直接执行a * b % c 实际上是在执行((a * b) % 2^256) % c会得到完全不同的结果。计算公式a * b % c 使用32字节空间的32字节值是非常不常见且繁琐。
• SIGNEXTEND
SIGNEXTEND操作码的作用是为了方便从大的有符号整数到小的有符号整数的类型转换。小的有符号整数是很有用的,因为未来的即时编译虚拟机可能会检测长时间运行的代码块,小的有符号整数能加快处理。
• SHA3
在以太坊代码中SHA3作为安全的高强度的hash集合应用非常广泛,通常在使用存储器时需要使用Hash函数来确保安全,以防止恶意冲突,在验证***树和类似以太坊的数据结构时也需要使用到Hash函数。重要的是,与SHA3的相似的hash函数,如SHA256,ECRECVOR,RIPEM160不是以操作码的形式包含在里面,而是以伪合约的形式。这样做的目的是将它们放在一个单独的类别中,如果当我们以后提出适当的“本地扩展”系统时,可以添加更多这样的合约,而不需要扩展操作码。
• ORIGIN
ORIGIN操作码由交易的发送者提供,主要的作用是允许合约退回支付的gas。
• COINBASE
COINBASE的主要作用是:1.如果使用COINBASE操作码,则允许子货币对网络安全作出贡献;2.开放使用矿工作为一个去中心化的经济体,来设置基于子共识的应用,如Schellingcoin。
• PREVHASH
PREVHASH作为一个半安全的随机来源,允许合约评估上一个区块的***树状态证明,而不需要高度复杂的递归结构“以太坊轻客户端”。
• EXTCODESIZE, EXTCODECOPY
主要的作用是让合约依据模板检查其他合约的代码,甚至是在与其他合约交互前,模拟它们。
• JUMPDEST
当跳转(jump)目的地限制在几个索引时(尤其是,动态目的跳转的计算复杂度是O(log(有效挑战目的数量)),而静态跳转总是恒定的),JIT虚拟机实现起来更简单。于是,我们需要:1.对有效变量跳转目的地做限制;2.使用静态而不是动态跳转的激励方式。为了达到这两个目标,我们定下了以下规则:1.紧接着push后的跳转可以跳到任何地方,而不仅是另一个jump;2.其他的jump只能跳转到JUMPDEST。对跳转的限制是必须的,你可以通过查看代码中的先前操作来决定是静态还是动态的跳转。缺乏对静态跳转的需求是激励使用它们的原因。禁止跳转进入push数据也会加快JIT虚拟机的编译和执行。
*• LOG *
LOG是事件的日志。
• CALLCODE
该操作码允许合约使用自己的存储器,在单独的栈空间和内存中调用其他合约的“函数”。这样可以在区块链上灵活实现标准库代码。
• SELFDESTRUCT
允许合约删除它自己,前提是它已经不需要存在了。SELFDESTRUCT并非立即执行,而是在交易执行完之后执行。这是因为这样做可以恢复那些执行后大大增加了缓存复杂度的SELFDESTRUCT操作码。
• PC
尽管理论上不需要PC操作码,因为所有的PC操作码都可以根据将push操作的索引加入实际程序计数器来代替实现,但使用PC可以创建独立代码的位置(可复制粘贴到其他合约的编译函数,如果它们以不同索引结束,不要打断)。
注释:
① UTXO: unspent transaction outputs。字面理解是:有效的交易输出,它是比特币协议中用于存储交易信息的数据结构。
② Nonce,Number used once或Number once的缩写,在密码学中Nonce是一个只被使用一次的任意或非重复的随机数值,在加密技术中的初始向量和加密散列函数都发挥着重要作用,在各类验证协议的通信应用中确保验证信息不被重复使用以对抗重放攻击(Replay Attack)。
③ 嵌套数组:创建一个数组,并使用其他数组填充该数组。如数组pets:
var cats : String[] = [“Cat”,“Beansprout”, “Pumpkin”, “Max”];
var dogs : String[] = [“Dog”,“Oly”,“Sib”];
var pets : String[][] = [cats, dogs];
④ 行程编码(run-length-encoding):一种统计编码。主要技术是检测重复的比特或字符序列,并用它们的出现次数取而代之。(百度百科)
⑤ 布隆过滤器:由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。(百度百科)
⑥ uncle:A挖出区块后广播途中,B也挖出了区块(过时区块),此时区块链会出现分叉。过时分叉上的区块就叫uncle区块。它不是这个块的父区块,父区块的兄弟区块(平级关系)。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 如何正确的理解Plasma和Plasma Cash的基础概念
如何正确的理解Plasma和Plasma Cash的基础概念



 APP下载
APP下载 登录
登录







