×


尝试分析机器学习模型在什么时候、以什么方式、由于什么原因失效,我们把这称为「误差分析(error analysis)」。对科研人员来说,他们需要通过误差分析选择后续的改进方向;模型的实际使用者们也需要根据误差分析来确定模型部署的许多细节。由于误差分析对后续的行动方向有显著的影响,如果误差分析中出现了偏倚,或者误差分析不完整,很可能会带来我们不想看到的后果。
NLP 任务误差分析的现状
但是人们目前都是怎么做误差分析的呢?如果你翻翻自然语言处理顶级学术会议 ACL 的接收论文,你基本上会看到这样的叙述:
我们针对 100 个样本问题进行了误差分析……
我们随机选择了 50 个回答不正确的问题并把它们分为了 6 类……
我们找出了 100 个不正确的预测结果并尝试寻找共同的误差类别……
……
显然,这个领域内的研究人员们都不约而同地采用了这种做法:「我们随机选择了 50 到 100 个回答不正确的问题并把它们大致分为了 N 组」。(斯坦福大学 NLP 组负责人 Christopher Manning 的画外音:问答任务的论文里选 100 个样本做错误分析的惯例恐怕出自我这里 —— 最初我们想做 200 个的,但我一直没有做分给我的那一半)
选择一部分错误样本做分析,看起来好像还有那么点道理对不对?但其实这种做法有很大问题。比如,50 到 100 的样本数量太小了,一般来说只占到误差总量的 5%。这么小的采样数量很难代表真正的误差分布。如果拿来做误差分析的采样样本里刚好没有体现出某个关键的模型问题(比如聊天助理机器人会对某些特定的语句给出不当的回答),然后就这么把没有得到修复的模型实际部署了,结果肯定会非常可怕。
这还没完,样本数量小才仅仅是常见做法中出现的第一个问题而已。在 ACL 2019 论文《Errudite: Scalable, Reproducible, and Testable Error Analysis》中,作者们详细列举了 NLP 误差分析中的许多个关键挑战,也提出了三个原则,希望大家能够把误差分析做得更准确,也具备更的可重复、可拓展、可测试(论文:http://idl.cs.washington.edu/files/2019-Errudite-ACL.pdf)。作者们还设计了 Errudite,这是一个实践了这些原则的交互式工具,它也可以逐个应对发现的问题。
论文作者们也撰写了一篇介绍博客,根据通过一个具体的错误分析流程来说明当前基于一小批样本的手工、主观误差分析为什么容易得出模棱两可的、有偏倚的分析,并且可能弄错误差原因,以及如何借助 Errudite 避免这些错误。他们的论文中还有更多的例子。
从实际例子说起
我们要对机器阅读理解(Machine Comprehension)的一个知名基准模型 BiDAF (https://allenai.github.io/bi-att-flow/)做错误分析。在这项任务中,首先给定一个问题和一段文本,机器阅读理解模型需要找到能正确回答问题的文本片段。

在这个出自 SQuAD 数据集的例子中,加粗字体的 Murray Gold 创作了《Doctor Who(神秘博士)》的 2005 特别篇。
作为语言理解的最重要测试任务之一,机器阅读理解中的误差分析非常关键但也有不少困难:研究人员们都希望能够找到先进模型中的弱点并进行改进,但是由于模型的输入(问题、文本段落)和输出(答案)都是非结构化的文本,能够用来分析解读数据集的特征就很少。BiDAF 是研究机器阅读理解任务的学者们非常熟悉的一个模型了,下文中拿来举例的误差分析就都是出自研究人员们针对 BiDAF 的真实分析。
在刚才这个例子中,BiDAF 做了错误的预测,给出的答案是 John Debney (下划线)而不是 Murray Gold。我们希望能够从这个错误做一些推广,更全面地理解模型的表现。
在分析这个错误时,我们首先会问的问题就是:模型为什么会出现这种错误?一位专家给出了一个干扰词猜想:BiDAF 擅长把问题匹配到各种命名实体类别上,但是如果同时出现了同类型的其它实体的话,BiDAF 就很容易被干扰。以上面那个例子来说,我们问的问题是「谁」,BiDAF 就知道我们需要一个人名,也确实回答了一个人名,只不过不是正确的那个人名。
带着这个假说,我们下一个需要问的问题是,「这个模型经常会犯这种错误吗?」探究猜想的普适性需要研究更多类似的样本。然而,如我们上文说到的,如果想要探索整个数据集的话,这些非结构化文本中可供利用的特征太少了,所以研究人员们通常的做法是手工标注一些错误样本,并把它们分为不同的组。
这种做法的问题在于,不同分组的定义是主观的,不同的人会提出不同的分组方式。比如在另一个例子中,一个问「when」的问题的标准答案是「在他读大学期间」,而模型给出的回答是「1996」,是一个错误的年份。有人会认为这是一个符合干扰词猜想的问题,毕竟问题问的是时间,和模型给出的回答类型(同样也是时间)是匹配的。但是也有人会认为它应该属于别的错误类别,毕竟标准答案「在他读大学期间」不是一个可以被识别的命名实体。如果你只是翻看这个错误例子的名称和文本描述的话,很有可能你都意识不到会有这种差异。
实际上,论文作者们发现即便只是用简单的法则定义不同的错误分组,这种差异性/人与人之间的不一致性也会出现:作者们找来此前曾发表过的一份错误分析中的一个错误类型及其描述,然后让现在的专家们重复这个实验,结果他们分到这一组的错误数量大为不同,差异最小也有 13.8%,最大甚至有 45.2%;这更明显地体现出了人工标注的模糊性。
针对这种状况,论文作者们提出了第一条原则:必须用明确的描述精确定义错误猜想。
原则 1:准确
为了规避人为主观性、提高准确性,Errudite 使用了一种任务专用语言(Domain-Specific Language)来量化描述不同的实例。
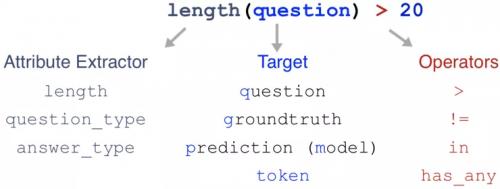
简单来说,这种任务专用语言使用了一系列强有力的属性提取器,在额外的辅助操作符的帮助下解析具体的错误(属性提取器、目标、操作符三部分)。比如可以解析一个问题的长度,并要求长度大于 20。这样,研究人员们就可以根据特定的模式,客观、系统地对大量错误例子分组,得出某种错误的准确的出现频率。比如下图就是用这种语言对「干扰词猜想」的准确描述,也就可以把「在他读大学期间」这个例子排除在这个分类之外。

原则 2:覆盖所有的数据
在 BiDAF 的所有错误中执行了这个过滤器之后,一共找到了 192 个例子是符合「干扰词猜想」的,也就是说标准答案和错误答案的命名实体类型相同,然后模型给出了错误的实体。值得注意的是,在达到了这种准确性的基础上,任务专用语言的运用也可以极大地拓展误差分析的规模:相比于常见做法里一共分析 50 到 100 个错误样本,现在单个错误类别的样本量都达到了 192。这也就减小了采样误差。
总数量方面,这 192 个错误样本占到了所有错误总数的 6%,这个干扰词猜想看来是可以被证实的。有具体数据以后,错误分析的说服力也变强了很多对吧。

不过,当我们执行了所有步骤中的过滤器、构建出了详尽的分组以后,我们其实会发现全新的图景:对于全部样本,BiDAF 能给在 68% 的样本中给出正确的实体;对于标准答案就是一个实体的样本,模型的准确率会提高到 80%;当文本中有同一个类型的其它实体的时候,BiDAF 的准确率仍然有 79%;让它预测一个类型正确的实体的时候,它的准确率高达 88%,要比全部样本的正确率高得多。这意味着,对于实体类型匹配、且有干扰词出现的情况,模型的表现还是比整体表现要好,这种情况并不是模型表现的短板。所以,如果你只是发现了有某种错误出现,然后就决定要先解决这种错误的话,你可能需要重新考虑一下,因为你很可能忽视了模型表现非常糟糕的情境。
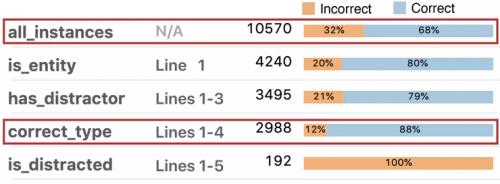
所以,这个领域专用语言可以帮助分析整个数据集,包括检验没有出错的样本。这样的误差分析更系统、可以支持更大的规模;相比于只看一小部分样本,你得到的结论也可能完全不同。
那么,第二条原则可以正式地表述为:错误出现频率的分析应该在整个数据集上进行,其中需要包括正例(true positive)。
原则 3:测试错误猜想,验证因果性
现在我们已经建立起关于干扰词的分组了。但是,出现错误的时候同时有一个干扰词并不一定代表干扰词是这个错误出现的根本原因。回到前面的例子,我们可以简单地认为出错的根本原因是因为有干扰词,但也可能是因为我们需要做多句推理,需要把「神秘博士」和「系列」联系起来,又或者还有别的原因。

这就引出了我们当前面对的现状中的另一个问题:我们很难有效地分离某个错误的根本原因。想要弄清的话,我们需要第三个原则
原则 3:错误猜想要经过显式的测试验证
借助 Errudite,论文作者们想要回答这个问题:这 192 个错误都是因为有干扰词才出错的
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 紫金桥监控组态软件在冶金自动化生产线上的应用
紫金桥监控组态软件在冶金自动化生产线上的应用








 APP下载
APP下载 登录
登录







