
(本文由新思科技供稿,电子发烧友平台发布)
过去十年间,几项技术的进步使人工智能 (AI)成为最令人振奋的技术之一。2012年,Geoffrey Everest Hinton在Imagenet挑战赛中展示了他的广义反向传播神经网络算法,该算法使计算机视觉领域发生了革命性变化。然而,机器学习理论早在2012年之前就有人提出,并且Nvidia GTX 580图形处理器单元等微处理器使这一理论得以实现。这些处理器具有相对较高的内存带宽能力且擅长矩阵乘法,可将该神经网络模型的AI训练时间缩短至大约一周。理论与算法的结合开启了新一代技术进步,带来了与AI相关的全新可能性。本文概述了人工智能设计新时代及其多样化处理、内存和连接需求。
人工智能剖析
我们将神经网络定义为深度学习,它是机器学习及人工智能的一个子集,如图1所示。这是一个重要的分类,深度学习该子集改变了芯片系统架构设计。
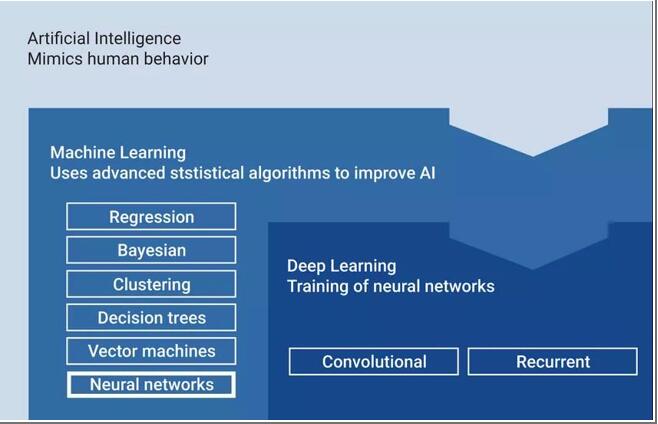
图1:人工智能采用深度学习算法模仿人类行为
深度学习不仅改变了芯片架构,而且催生了半导体市场的新一轮投资。深度学习算法模型是研发和商业投资的热点,例如卷积神经网络 (CNN)。CNN一直是机器视觉的主要焦点。递归神经网络等模型因其识别时间的能力而在自然语言理解中得以应用。
人工智能的应用
深度学习神经网络应用于许多不同的场景,为使用它们的人提供了强大的新工具。例如,它们可以支持高级安全威胁分析、预测和防止安全漏洞,并通过预测潜在买家的购物流程来帮助广告商识别和精简销售流程。
但AI设计并未局限于数据中心,诸如用于物件和人脸识别的视觉系统、用于改进人机接口的自然语言理解以及周围环境感知等许多新功能可基于传感器输入的组合而使机器理解正在发生的活动。这些深度学习能力已融入到不同场景所需的芯片设计中,包括智能汽车、数字家庭、数据中心和物联网 (IoT),如图2所示。

图2:AI处理能力已结合到大量应用中
手机利用神经网络实现上述多种AI功能。手机可运行人脸识别应用、物件识别应用、自然语言理解应用。此外,它在内部使用神经网络进行5G自组织,因为无线信号在其他介质、不同的光谱上会变得更密集,并且所传输的数据有不同的优先级。
人类大脑
最近,深度学习通过数学和半导体硬件的进步变得可行。业界已开展多项举措,在下一代数学模型和半导体架构中更好地复制人脑,这通常被称为神经形态计算。人类的大脑可以达到难以置信的高效率,但技术在复制人类大脑等方面才刚开始触及皮毛。人类大脑包含超过1 PB (Petabyte=1024TB)的存储空间,相当于大约540万亿个晶体管,且功率小于12瓦。从这点来说,复制大脑是一个长远的目标。然而,ImageNet挑战赛已从2012年的第一个反向传播CNN算法发展到2015年更高级的AI模型ResNet 152,市场正在快速发展,新的算法层出不穷。
AI设计挑战
融合深度学习能力的芯片架构促使了多项关键技术的进步,从而达到高度集成的解决方案和更通用的AI 芯片,包含专用处理需求、创新内存架构和实时数据连接。
专用处理需求
融合神经网络能力的芯片必须同时适应异构和大规模并行矩阵乘法运算。异构组件需要标量、矢量DSP和神经网络算法能力。例如,机器视觉需要独立的步骤,每一步都需要执行不同类型的处理,如图3所示。

图3:神经网络能力需要独特的处理
预处理需要更简单的数据级并行性。对所选区域的精确处理需要更复杂的数据级并行性,可以通过具有良好矩阵乘法运算能力的专用CNN加速器有效地处理。决策阶段通常可以通过标量处理的方式来处理。每个应用都是独一无二的,但很明显的是,包括神经网络算法加速的异构处理解决方案需要有效地处理AI模型。
创新内存架构
AI模型使用大量内存,这增加了芯片的成本。训练神经网络要求达到几GB甚至10GB的数据,这就需要使用DDR最新技术,以满足容量要求,例如,作为图像神经网络的VGG-16在训练时需要大约9GB的内存;更精确的模型VGG-512需要89GB的数据才能进行训练。为了提高AI模型的准确性,数据科学家使用了更大的数据集。同样,这会增加训练模型所需的时间或增加解决方案的内存需求。由于需要大规模并行矩阵乘法运算以及模型的大小和所需系数的数量,这就要求配备具有高带宽存取能力的外部存储器及新的半导体接口IP,如高带宽存储器 (HBM2)和衍生产品 (HBM2e)。先进的FinFET技术支持更大的芯片SRAM阵列和独特的配置,具有定制的存储器到处理器和存储器到存储器接口,这些技术正在开发中,为了更好地复制人脑并消除存储器的约束。
AI模型可以压缩,确保模型在位于手机、汽车和物联网应用边缘的芯片中受限的存储器架构上运行所必需的。压缩采用剪枝和量化技术进行且不能降低结果的准确性,这就要求传统芯片架构(具有LPDDR或在某些情况下没有外部存储器)支持神经网络。随着这些模型的压缩,不规则的存储器存取和计算强度增加,延长了系统的执行时间。因此,系统设计人员正在开发创新的异构存储器架构。
实时数据连接
一旦AI模型经过训练并可能被压缩,就可以通过许多不同的接口IP解决方案执行实时数据。例如,视觉应用由CMOS图像传感器支持,并通过MIPI摄像头串行接口 (CSI-2)和MIPI D-PHY IP连接。LiDAR和雷达可通过多种技术支持,包括PCI Express和MIPI。麦克风通过USB、脉冲密度调制 (PDM) 和I2S等连接传输语音数据。数字电视支持HDMI和DisplayPort连接,以传输视频内容,而这些内容可通过神经网络传输后得到改善,实现超高图像分辨率,从而以更少的数据生成更高质量的图像。目前,大多数电视制造商正在考虑部署这项技术。
混合AI系统是另一个预计会大量采用的概念。例如,心率算法通过健身带上的AI系统可以识别异常,通过将信息发送到云端,对异常进行更准确的深入AI神经网络分析,并加以提示。这类技术已经成功地应用于电网负载的平衡,特别是在电线中断或出现意外重负荷的情况下。为了支持快速、可靠的网络与云端连接,上述示例中的聚合器需要以太网连接。
消除瓶颈
尽管复制人类大脑还有很长的路要走,但人类大脑已被用作构建人工智能系统的有效模型,并继续由全球领先的研究机构来建模。最新的神经网络试图复制效率和计算能力,芯片架构也开始通过紧密耦合处理器和内存来复制人类大脑。ARC子系统包括AI及其APEX扩展和普遍存在的RISC架构所需的处理能力。子系统将外设和存储器紧密耦合到处理器,以消除关键的存储器瓶颈问题。
用于AI的DesignWare IP
AI是最令人振奋的技术之一,特别是深度学习神经网络,通过结合神经网络算法的创新以及高带宽、高性能半导体设计的创新而飞速发展。
新思科技正在与世界各地细分市场中领先的AI 芯片供应商合作,提供采用经过验证的可靠IP解决方案,帮助他们降低芯片设计风险,加快产品上市速度,并为AI设计人员带来关键的差异化优势。
专用处理需求、创新内存架构和实时数据连接构成了人工智能芯片的DNA,面对AI设计挑战,新思科技提供了许多专业处理解决方案来消除存储器瓶颈,包括存储器接口IP、带有TCAM和多端口存储器的芯片SRAM编译器等,同时提供了全面的实时数据连接选项。这些IP解决方案是下一代AI设计的关键组件。
关于新思
新思科技(Synopsys, Inc.,纳斯达克股票市场代码: SNPS)致力于创新改变世界,在芯片到软件的众多领域,新思科技始终引领技术趋势,与全球科技公司紧密合作,共同开发人们所依赖的电子产品和软件应用。新思科技是全球排名第一的芯片自动化设计解决方案提供商,全球排名第一的芯片接口IP供应商,同时也是信息安全和软件质量的全球领导者。作为半导体、人工智能、汽车电子及软件安全等产业的核心技术驱动者,新思科技的技术一直深刻影响着当前全球五大新兴科技创新应用:智能汽车、物联网、人工智能、云计算和信息安全。
新思科技成立于1986年,总部位于美国硅谷,目前拥有13000多名员工,分布在全球100多个分支机构。2018财年预计营业额31亿美元,拥有3000多项已批准专利,为美国标普500指数成分股龙头企业。
自1995年在中国成立新思科技以来,新思科技已在北京、上海、深圳、厦门、武汉、西安、南京、香港、澳门九大城市设立机构,员工人数超过1100人,建立了完善的技术研发和支持服务体系,秉持“加速创新、推动产业、成就客户”的理念,与产业共同发展,成为中国半导体产业快速发展的优秀伙伴和坚实支撑。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 关于机器学习你了解多少
关于机器学习你了解多少








 APP下载
APP下载 登录
登录







