
卷积神经网络和长期短期记忆网络的核心,深度学习的两个主要支柱,甚至在像谷歌的变形金刚这样的更现代的网络中,大多数计算都是线性代数计算,称为张量数学。最常见的是,将一些输入数据转换为矢量,然后将该矢量乘以神经网络权重矩阵的列,并将所有这些乘法的乘积相加。称为乘法相加,这些计算使用所谓的“乘法 - 累加”电路或“MAC”在计算机中呈现。因此,只需改进MAC并在芯片上创建更多的MAC来增加并行化,就可以立即改善机器学习。
主导AI培训的Nvidia和其CPU主导机器学习推理的英特尔都试图调整他们的产品以利用那些原子线性代数函数。Nvidia为其Tesla GPU添加了“张量核心”,以优化矩阵乘法。英特尔已花费300亿美元收购那些从事机器学习的公司,包括Mobileye,Movidius和Nervana Systems,其中最后一个应该在某个时候导致“Nervana神经网络处理器”,尽管有延迟。

到目前为止,这些举措并不能满足机器学习的需求,例如Facebook的LeCun。在2月与ZDNet聊天期间,LeCun认为,“我们需要的是竞争对手,现在,你知道,主导供应商[Nvidia]。” 这不是因为,他说,Nvidia没有做出好的筹码。这是“因为他们做出了假设,”他继续说道,“而且拥有一套不同的硬件可以用来做当前GPUS擅长的补充事物,这是不错的选择。”
他说,其中一个有缺陷的假设是假设训练神经网络将是一个可以操作的“整齐阵列”的问题。相反,未来的网络可能会使用大量的网络图,其中神经网络的计算图的元素作为指针流式传输到处理器。LeCun表示,芯片必须进行大量的乘法增加,但对于如何将这些乘法增加呈现给处理器的期望不同。
作为TPU芯片贡献者之一的谷歌软件工程师Cliff Young,去年10月在硅谷举行的芯片活动上发表了主题演讲时更直言不讳。“很长一段时间,我们都拒绝了,并说英特尔和Nvidia非常擅长构建高性能系统,”Young说。“五年前我们超越了这个门槛。”在这个漏洞中,新的芯片来自谷歌等人工智能巨头,还有一大批风险投资支持的创业公司。
除了谷歌的TPU,现在已经进行了第三次迭代,微软还有一个可编程处理器,一个名为Project Brainwave的“FPGA”,客户可以通过其Azure云服务租用它。亚马逊表示,它将在今年晚些时候推出自己的定制芯片,名为“Inferentia”。当LeCun在2月份与ZDNet谈话时,他提到Facebook有自己的筹码。
“当然,像谷歌和Facebook这样拥有大量产品的公司,对你自己的引擎工作是有道理的,”LeCun说。“这方面有内部活动。”创业公司包括Graphcore,一家位于布里斯托尔的五年创业公司,一个位于伦敦西南一个半小时的港口城市; Cornami,Effinix和Flex Logix,所有这些都是由ZDNet描述的; 和硅谷的洛斯阿尔托斯的Cerebras系统公司仍然处于秘密模式。
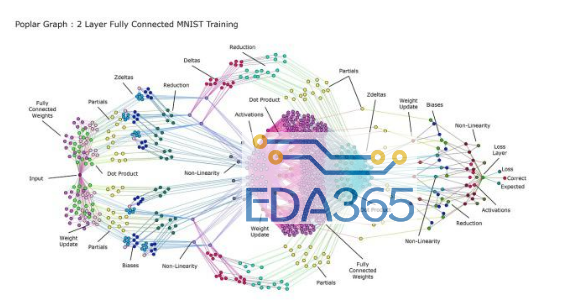
许多这些初创公司都有一个共同点,那就是大大增加用于矩阵乘法的计算机芯片区域的数量,即MAC单元,以便在每个时钟周期内挤出最多的并行化。Graphcore是所有初创公司中最远的,是第一个真正向客户发送生产芯片的公司。关于它的第一个芯片最引人注目的事情之一是大量的内存。为了纪念世界上第一台数字计算机,Colossus 被称为芯片,面积巨大,面积为806平方毫米。首席技术官Simon Knowles称其为“迄今为止最复杂的处理器芯片”。
Colossus由1,024个被称为“智能处理单元”的独立核心组成,每个核心都可以独立处理矩阵数学。众所周知,每个IPU都有自己的专用内存,256千字节的快速SRAM内存。总共有304兆字节的内存是芯片中最常用的内存。没有人知道芯片上存在如此多的内存会如何改变构建的神经网络的种类。可能是通过访问越来越多的内存,访问速度非常低,更多的神经网络将专注于以新的和有趣的方式重用存储在内存中的值。
对于所有这些芯片的努力,问题当然是由于该公司的“CUDA”编程技术,他们没有为Nvidia建立多年的软件。Graphcore和其他人的答案将是双重的。一个是用于机器学习的各种编程框架,例如TensorFlow和Pytorch,提供了一种避免芯片本身细节并专注于程序结构的方法。所有进入市场的芯片都支持这些框架,他们的创造者认为这些框架与Nvidia的竞争环境。
第二点是Graphcore和其他人正在构建自己的编程技术。他们可以证明他们的专有软件既可以转换框架,也可以智能地将并行计算分配给芯片上的众多MAC单元和向量单元。这就是Graphcore为其“Poplar”软件所做的论证。Poplar将神经网络的计算图分解为“codelets”,并将每个codelet分配到Colossus的不同核心,以优化并行处理。
在过去的二十年中,大数据和快速并行计算成为常态,推动了机器学习,带来了深度学习。下一波计算机硬件和软件可能涉及大量内存和神经网络,这些内存和神经网络受到动态限制,以利用高度并行的芯片架构。未来看起来很有趣。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 关于机器学习你了解多少
关于机器学习你了解多少







 APP下载
APP下载 登录
登录







