
首先我们来谈一下什么是卷积神经网络,相信在深度学习中这是最重要的概念,首先你可以把卷积想象成一种混合信息的手段。想象一下装满信息的两个桶,我们把它们倒入一个桶中并且通过某种规则搅拌搅拌。也就是说卷积是一种混合两种信息的流程。
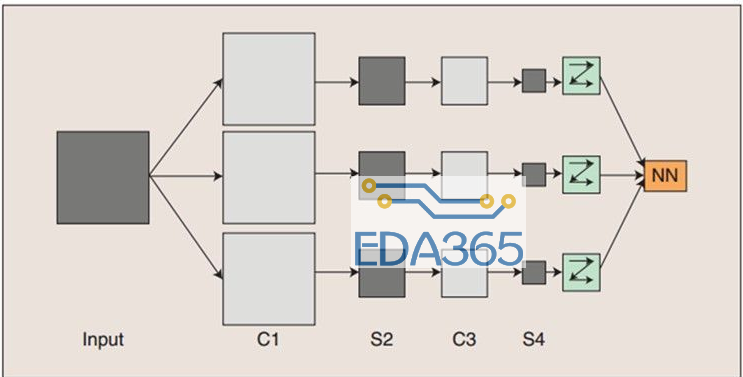
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。如下图所示,当我们在图像上应用卷积时,我们在两个维度上执行卷积——水平和竖直方向。我们混合两桶信息:第一桶是输入的图像,由三个矩阵构成—— RGB 三通道,其中每个元素都是 0 到 255 之间的一个整数。第二个桶是卷积核(kernel),单个浮点数矩阵。可以将卷积核的大小和模式想象成一个搅拌图像的方法。卷积核的输出是一幅修改后的图像,在深度学习中经常被称作 feature map。对每个颜色通道都有一个 feature map。
谈到这里,就不得不说一下卷积定理,它将时域和空域上的复杂卷积对应到了频域中的元素间简单的乘积。这个定理可以说是及其强悍,在包括图像处理等许多科学领域中得到了广泛应用。
什么,你说上面的公式你看不懂,那么小编在此解释以下,第一个等式是一维连续域上两个连续函数的卷积;第二个等式是二维离散域(图像)上的卷积。这里的“离散”指的是数据由有限个变量构成(像素);一维指的是数据是一维的(时间),图像则是二维的,视频则是三维的。当然在实际工作中,我们根部不需要理解上面的公式是什么意思,毕竟没有什么问题是调包解决不了的,如果有那就再调一次包(手动滑稽)。
在图像识别问题中,输入层的每一个神经元可能代表一个像素的灰度值。但这种神经网络用于图像识别有几个问题,一是没有考虑图像的空间结构,识别性能会受到限制;二是每相邻两层的神经元都是全相连,参数太多,训练速度受到限制。而卷积神经网络就可以解决这些问题。卷积神经网络使用了针对图像识别的特殊结构,可以快速训练。因为速度快,使得采用多层神经网络变得容易,而多层结构在识别准确率上又很大优势。
还有一个问题等待我们解决,就是卷积神经网络(CNN)如何提高图片的识别精度呢?问题的关键在要在以上的基础上再加上池化层和卷积层。和一个额外全连接层的结构,其实我们可以这么理解,卷积层和池化层学习输入图像中的局部空间结构,而后面的全连接层的作用是在一个更加抽象的层次上学习,包含了整个图像中的更多的全局的信息。
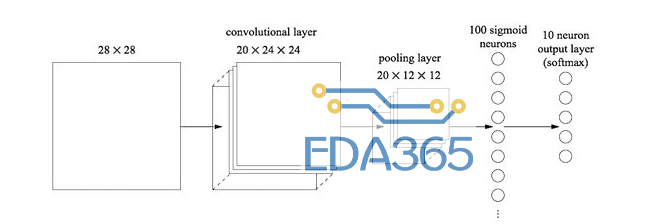
以上,基本就是卷积神经网络在图像处理中的应用,我们可以看到在用 CNN 处理图片中,涉及很多知识点和工具。图像处理这个领域学习成本相对较高,如果一个新人没人人引领入门往往不得其门而入,这样会浪费大量的时间,为此,AICon 全球人工智能与机器学习技术大会特意邀请到了旷世 face++ 科技的高级研究员熊鹏飞老师,为大家深入浅出的讲解深度学习在图像处理中的应用。感兴趣的小伙伴们扫描下面图片中的二维码了解详细情况。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 2020年的信息安全:人工智能对各种信息安全系统的重要性
2020年的信息安全:人工智能对各种信息安全系统的重要性






 APP下载
APP下载 登录
登录







