
作者:Mitesh Moonat 和 Sanket Nayak | ADI 应用工程师
摘要
有限脉冲响应(FIR)和无限脉冲响应(IIR)滤波器都是常用的数字信号处理算法---尤其适用于音频处理应用。因此,在典型的音频系统中,处理器内核的很大一部分时间用于FIR和IIR滤波。数字信号处理器上的片内FIR和IIR硬件加速器也分别称为FIRA和IIRA,我们可以利用这些硬件加速器来分担FIR和IIR处理任务,让内核去执行其他处理任务。在本文中,我们将借助不同的使用模型以及实时测试示例来探讨如何在实践中利用这些加速器。
简介
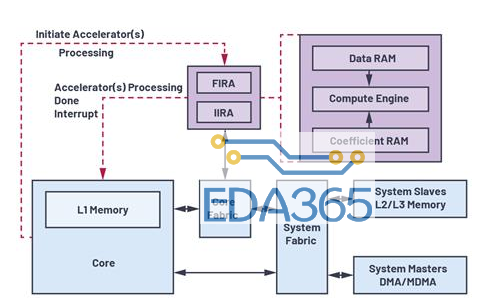
图1.FIRA和IIRA系统方框图
图1显示了FIRA和IIRA的简化方框图,以及它们与其余处理器系统和资源的交互方式。
在本文中,我们将讨论针对不同应用场景充分利用这些加速器的各种模型。
实时使用FIRA和IIRA
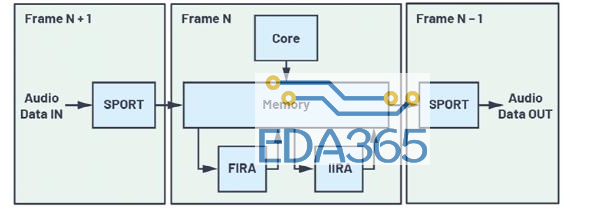
图2.典型实时音频数据流
图2显示了典型实时PCM音频数据流图。一帧数字化PCM音频数据通过同步串行端口(SPORT)接收,并通过直接存储器访问(DMA)发送至存储器。在继续接收帧N+1时,帧N由内核和/或加速器处理,之前处理的帧(N-1)的输出通过SPORT发送至DAC进行数模转换。
加速器使用模型
如前所述,根据应用的不同,可能需要以不同的方式使用加速器,以最大限度分担FIR和/或IIR处理任务,并尽可能节省内核周期以用于其他操作。从高层次角度来看,加速器使用模型可分为三类:直接替代、拆分任务和数据流水线。
直接替代
·内核FIR和/或IIR处理直接被加速器替代,内核只需等待加速器完成此任务。
·此模型仅在加速器的处理速度比内核快时才有效;即,使用FIRA模块。
拆分任务
·FIR和/或IIR处理任务在内核和加速器之间分配。
·当多个通道可并行处理时,此模型特别有用。
·根据粗略的时序估算,在内核和加速器之间分配通道总数,使二者大致能够同时完成任务。
·如图3所示,与直接替代模型相比,此使用模型可节省更多的内核周期。
数据流水线
图3说明了音频数据帧如何在不同加速器使用模型的三个阶段之间传输---DMA IN、内核/加速器处理和DMA OUT。它还显示了通过采用不同的加速器使用模型将FIR/IIR全部或部分处理转移到加速器上,与仅使用内核模型相比,内核空闲周期如何增加。

图3.加速器使用模型比较
SHARC处理器上的FIRA和IIRA
以下ADI SHARC®处理器系列支持片内FIRA和IIRA(从旧到新)。
·ADSP-214xx (例如, ADSP-21489)
·ADSP-SC58x
·ADSP-SC57x/ADSP-2157x
·ADSP-2156x
这些处理器系列:
·计算速度不同
·基本编程模型保持不变,ADSP-2156x处理器上的自动配置模式(ACM)除外。
·FIRA有四个MAC单元,而IIRA只有一个MAC单元。
ADSP-2156x处理器上的FIRA/IIRA改进
ADSP-2156x是SHARC处理器系列中的最新的产品。它是第一款单核1 GHz SHARC处理器,其FIRA和IIRA也可在1 GHz下运行。ADSP-2156x处理器上的FIRA和IIRA与其前代ADSP-SC58x/ADSP-SC57x处理器相比,具有多项改进。
性能改进
·计算速度提高了8倍(从SCLK-125 MHz至CCLK-1 GHz)。
·由于内核和加速器借助专用内核结构实现了更紧密的集成,因此减少了内核和加速器之间的数据和MMR访问延迟。
功能改进
添加了ACM支持,以尽量减少进行加速器处理所需的内核干预。此模式主要具有以下新特性:
·允许加速器暂停以进行动态任务排队。
·无通道数限制。
·支持触发生成(主器件)和触发等待(从器件)。
·为每个通道生成选择性中断。
实验结果
在本节中,我们将讨论在ADSP-2156x评估板上,借助不同的加速器使用模型实施两个实时多通道FIR/IIR用例的结果
用例1
图4显示用例1的方框图。采样率为48 kHz,模块大小为256个采样点,拆分任务模型中使用的内核与加速器通道比为5:7。
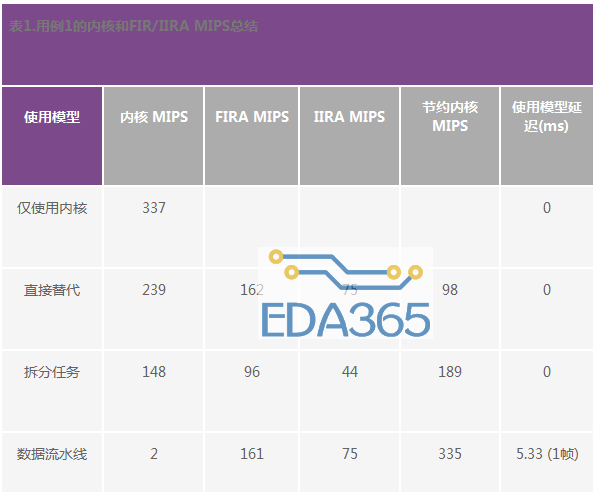
表1显示测得的内核和FIRA MIPS数量,以及与仅使用内核模型相比获得的节约内核MIPS结果。表中还显示了相应使用模型增加的额外输出延迟。正如我们所看到的,使用加速器配合数据流水线使用模型,可节约高达335内核MIPS,但导致1块(5.33 ms)的输出延迟。直接替代和拆分任务使用模型也分别可节约98 MIPS和189 MIPS,而且未导致任何额外的输出延迟。
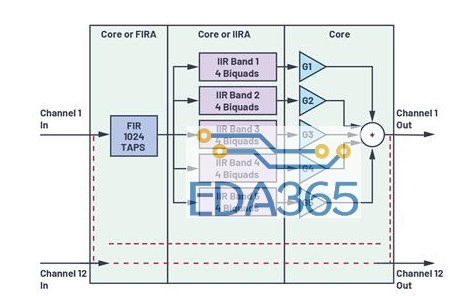
图4.用例1方框图
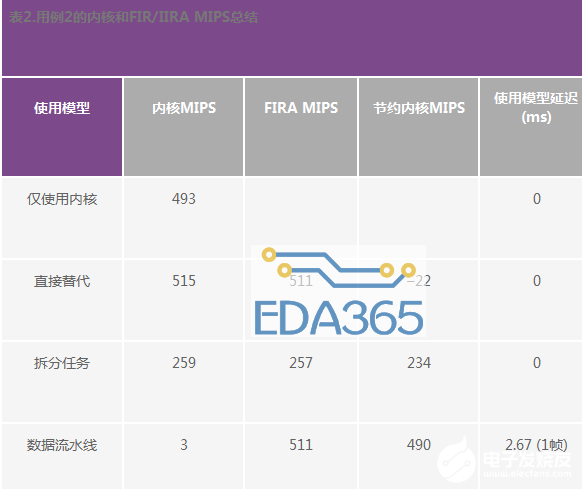
用例2
图5显示用例2的方框图。采样率为48 kHz,模块大小为128个采样点,拆分任务模型中使用的内核与加速器通道比为1:1。
与表1一样,表2也显示了此用例的结果。正如我们所看到的,使用加速器配合数据流水线使用模型,可节约高达490内核MIPS,但导致1模块(2.67 ms)的输出延迟。拆分任务使用模型可节约234内核MIPS,而没有导致任何额外输出延迟。请注意,与用例1中不同,在用例2中内核使用频域(快速卷积)处理,而非时域处理。这就是为何处理一个通道所需的内核MIPS比FIRA MIPS少的原因,这可导致直接替代使用模型实现负的内核MIPS节约。
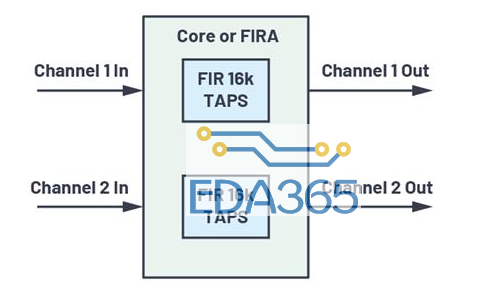
图5.用例2方框图
结论
在本文中,我们看到如何利用不同的加速器使用模型实现所需的MIPS和处理目标,从而将大量内核MIPS转移到ADSP-2156x处理器上的FIRA和IIRA加速器。
进一步阅读
“ADSP-2156x FIR/IIR加速器性能和实时使用情况图形演示。” ADI公司
Nayak, Sanket和Mitesh Moonat。 “工程师对话笔记EE-408:使用ADSP-2156x高性能FIR/IIR加速器。”ADI公司,2019年8月。
作者

Mitesh Moonat
Mitesh Moonat目前在印度班加罗尔(ADBL)处理器应用团队担任应用工程师。他从事前/后晶片验证、外设驱动器开发和SHARC处理器支持工作。在ADI就职期间,他还从事Blackfin和21xx处理器工作。他的工作领域包括处理器架构、数字信号处理算法优化、模块以及嵌入式系统的系统级调试。Mitesh于2006年加入ADI公司。他毕业于印度瓦朗加尔国家技术学院,获得电子和通信工程学士学位。

Sanket Nayak
Sanket Nayak是印度班加罗尔(ADBL)处理器应用团队的产品应用工程师。他于2016年加入ADI公司,一直从事汽车DSP的前/后晶片验证、驱动器/FuSa ROM设计、开发和测试工作。他获得班加罗尔PES技术学院电子和通信工程学士学位。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 国产毫米波雷达厂商的桎梏与突破
国产毫米波雷达厂商的桎梏与突破







 APP下载
APP下载 登录
登录







