
为了兼具可扩展性和数据处理速度,对于各种应用,如图像数据侦错、视频数据压缩、音频数据增益、马达控制等,可编程数据处理模块(Programmable Data Processing Module)是时势所需。
在处理的数据量越来越大的情况下,所需的内存容量随之增大,以往的先进先出队列(First-In-First-Out, FIFO)无法满足其高速度与大容量的需求,许多硬件工程师开始考虑使用 DRAM 的可能性。
DRAM 具备可快速存取、可依照设计者规划使用空间、大容量等优点,但是内存数组需要重新充电,而双倍数据速率同步动态随机存取内存( DDR SDRAM)有数据相位同步等不易控制的问题,不如 FIFO 使用方便。因此,在使用 FPGA 进行设计时,搭配其供货商所提供的 RAM 控制 IP,再加上硬件工程师所开发的控制逻辑,是当前数据控制存取的发展趋势。
本文的构想是在此 DRAM 控制 IP 上增加一层包装(Wrapper),使之拥有 FIFO 接口,具有多端口内存存取控制(MPMA: Multi-Port Memory Access)功能。既可以保持大容量、存取速度快等优点,也可增添 FIFO 接口容易的优点。在设计过程中,DRAM 空间可随设计师的定义而拥有更高的弹性。如图 1 所示,此 DRAM 拥有两个写入端口和两个读出端口。对于每个写入端口,其数据可以从起始地址连续写入,直到结束地址之后,再从起始地址继续写入,形成循环式(Circular)写入方式。对于每个读出端口,其数据的读出可使用类似于循环写入的方式,而且只要写入到内存的数据数量比读出的数据数量多,即是合理的类 FIFO 存取方式。
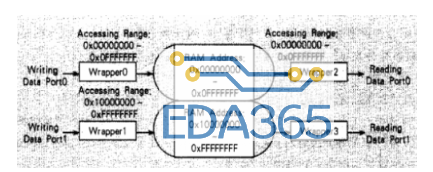
图 1 有两个写端口和两个读端口的 DRAM 控制槽
MPMA 如何应用于数据处理模块
在许多需要对大量信息进行运算处理的应用中,需要极大的缓存,与一个 4KB FIFO 的价格相比,买一个 32Mb 的 DRAM 更合适些。不过,其复杂的存取控制是一大问题。所以在编写 FPGA 的 HDL 算法时,可利用 FPGA 供货商所提供的 IP 构成解决方案。
对于所需处理的数据量重复性较高的应用,例如图 2 所示的图像原始数据用图像侦错处理算法来侦测 P4 点是否错误,需要将它周围的 8 个点当作参考数据来对比,若使用 FIFO,可能无法同时存取到此三条线(Line)的数据,所以使用 DRAM 存取大量的数据。
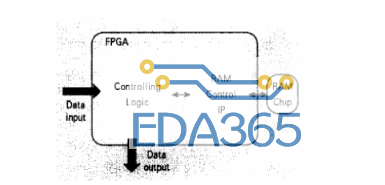
图 2 图像原始数据点数组
由于 DRAM 的控制方式比较复杂,每存取一次就要重新计算其欲存取的数据地址,根据其数据地址的连续性,可在图像原始数据写入后,分为三个端口以连续地址的方式读出。如图 2 所示,第一端口连续读出 P0、P1、P2,第二端口连续读出 P4、P5、P6,第三端口连续读出 P8、P9、P10,则可以完成 P5 点侦错的计算;而在计算 P6 点是否出错时,第一端口只要再读出 P3,第二端口读出 P7,第三端口读出 P11,就可以完成计算前数据的完备,大大提高了数据的使用率,采用连续读取的机制,不用在每次计算前计算数据地址,只要每一端口均先连续读取数据即可完成,也降低了 DRAM 控制的复杂度。
MPMA 的实现
下面以 Altera MegaCore IP Generator 产生的 DDR DRAM 控制器为例,再加上自创的 Wrapper 逻辑,构建一进(32 位进)一出(8 位出)的 MPMA 存取端口,图 3 为其方块架构图。

图 3 一进一出的 MPMA 存取端口
在此架构中,Altera DDR DRAM 控制与写 / 读 wrapper 间的数据带宽为 64 位,而通过 wrapper 逻辑,更可自由地编写输入与输出带宽。在写 / 读 wrapper 中,数据的地址计算采用累进式累加方式,其存取接口类似于 FIFO 的存取,因而更容易实现大容量数据的存取。
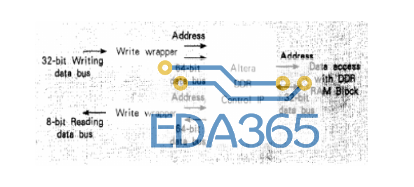
每个 wrapper 中有一个小容量的 FIFO、封装(packing)/ 反封装(un-packing)机制以及地址累进计数器。FIFO 用于调节使用者接口与 DRAM 频域的差异;封装 / 反封装机制用于将输入 / 输出接口数据总线宽度调整至与 DRAM 控制 IP 接口相同的水平,以利于提高写入 / 读出 DRAM 数据的效率。地址累进计数器是每个 wrapper 的 DRAM 地址产生器,只要写入 wrapper 里的计数器数字大于读出 wrapper 里的计数器,则所读出的必为先前已经写入 DRAM 里的合法数据,不会存取到错误地址的数据。
MPMA 提高效率
以图 2 的点 P5 为例,若不使用 wrapper,则此点数据会被写入 1 次,而在运算的时候被读出 1(当作主要运算点)+8(当作参考数据点)次。当一幅有 n 点数据的图像需要做侦错处理时,则需要 n*(1+1+8)次的数据存取,还不包括地址计算所造成的延迟。
当使用一进三出的 MPMA wrapper 时,P5 点只需要被写入 1 次,而在运算的时候被读出 3(3 个读 wrapper 各需要读取 1 次)次,则同样的 n 点数据作完侦错处理只需要 n*(1+3)次的数据存取,并且采用累进式的 DRAM 地址计算,不需要花费额外的延迟时间。由此可知,MPMA 设计可提高 2 倍以上的数据存取效率。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 数据中心需求猛增.NAND Flash Q4营收季提升8.5%
数据中心需求猛增.NAND Flash Q4营收季提升8.5%









 APP下载
APP下载 登录
登录







