
简介
在工程架构领域里,存储是一个非常重要的方向,这个方向从底至上,我分成了如下几个层次来介绍:
硬件层:讲解磁盘,SSD,SAS, NAS, RAID等硬件层的基本原理,以及其为操作系统提供的存储界面;
操作系统层:即文件系统,操作系统如何将各个硬件管理并对上提供更高层次接口;
单机引擎层:常见存储系统对应单机引擎原理大概介绍,利用文件系统接口提供更高级别的存储系统接口;
分布式层:如何将多个单机引擎组合成一个分布式存储系统;
查询层:用户典型的查询语义表达以及解析;
主板结构
在进入对硬件层的分析前,让我们来看看电脑主板上各个原件之间的关系。
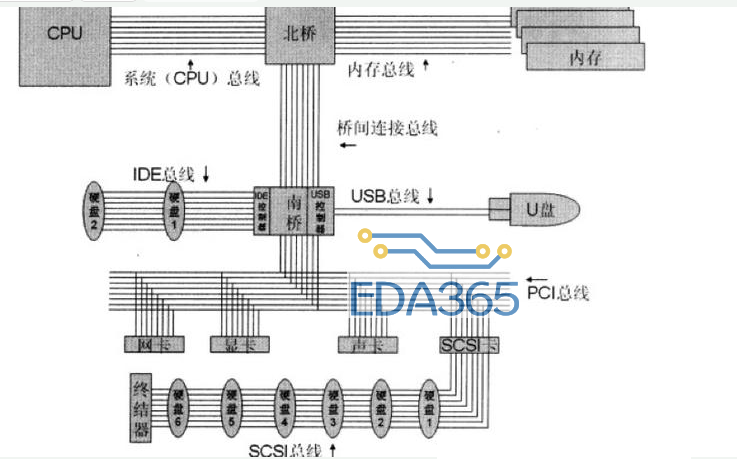
上图展示了主板上主要元件的结构图,以及他们之间的总线连接情况。核心连接点是北桥和南桥两块芯片。
其中北桥比较吊,连接的都是些高速设备。一般来说只连接CPU,内存和显卡几种设备。不过近些年也出现了PCIE2.0的高速接口接入北桥,使得一些符合标准的设备就可以接入北桥。
而南桥就相对搓了,他负责接入所有低速设备。什么USB,鼠标,磁盘,声卡等等都是接在南桥上的。而不同的设备用途和协议都有很大不同,所以设计了不同的交互协议。由于历史原因,不同设备传输介质可能都不一样,导致总线上布线十分复杂。所以到目前为止,主流设备都已经统一成为了PCI总线,大家一起用这条总线。
读写过程
我们来模拟一下CPU要从磁盘读入一份数据的过程:
CPU发出一条指令说哥要准备读数据了
这条指令依次通过系统总线,桥间总线,PCI总线传递到了磁盘控制器。控制器收到指令了之后知道这是一次读请求,且读完了是否要发中断的信息。做好一些准备工作,等待读取数据。
CPU再发出一条指令说要读取的逻辑地址
这条指令还是通过系列总线发给磁盘控制器之后。磁盘控制器就忙活了,查找逻辑快对应的物理块地址,查找,寻道等工作,就开始读取数据了。
CPU再发出一条指令说读入内存的地址
当收到这条指令之后,CPU就不管了,他告诉一个叫DMA的总管,说接下来就靠你了。DMA设备会接管总线,负责将磁盘数据通过PCI总线,桥间总线,内存总线同步到内存指定位置。
写操作的过程是类似的,就不累述了。
上面我们只是讲解了在主板上数据流转的过程,但是还有一个黑盒,就是磁盘控制器。这哥们到底是怎么管理的各个磁盘呢?在下一节我们将为你描述。
存储介质原理
上面讲了计算机读取数据的过程。这一章我们来大概说一下常见的存储介质的存储原理。
磁带
磁带就跟小时候听歌的时候的磁带类似。一条黑色带子上面有很多小的磁性粒子,根据粒子的南北级来判定0/1。
软盘
软盘比磁带要先进一点,记录数据的原理是一样的,只是可以随机读取,而磁带只能顺序读取。
硬盘
硬件原理
如果说前两个都是古老的东西,技术含量一般的话。硬盘就是一个很有技术含量的存储设备了,主要包含三大设备:
电机
电机的目的是控制磁臂精准定位到磁道,一个磁道可能很小,要精准定位到哪个地方是高科技。
盘面
盘面主要有两点。一点是基板要足够光滑平整,不能有任何瑕疵;一点是要将磁粉均匀的镀到基板上。这里有两个高科技,一个是磁粉的制造,一个是如何均匀的镀到基板上。
磁头
磁头的主要难点是要控制好跟盘面的距离,跟软盘类似,硬盘也是通过修改磁粉的南北极来记录数据的。如果隔得太远,就感知不到磁性数据了,隔得太近呢,又可能把盘面刮到。当然0/1的表示并不是只有一个磁粉,而是一片区域的磁粉。
现在磁盘都是利用空气动力学,将磁头漂浮在盘面上面一点距离来控制磁头和盘面的距离。但是当硬盘停止工作不转的时候,磁头就肯定掉在盘面上了,所以一般盘面靠近圆心的地方一般都有一块没有磁粉的地方,用于安全停靠磁头。当硬盘要开始工作的时候,磁头在同心圆里面起飞,飞起来了之后再移动到其他地区。
不过我一直在想,是否可以有这样的技术,能在磁臂上装多个磁头,每个磁道对应一个,停止工作的时候就把磁臂固定在某个高度让他不挨着盘面,这样是不是能大大提高硬盘的读写效率,因为这样减少了寻道的时间。
基本概念
硬盘组成原理图如下:

如上图, 硬盘主要有如下几个概念(概念比较简单,就不解释了):
扇区
磁道
柱面
读写过程
读写过程得分成两头来说,一头说将数据从各个盘面中读取出来;一头说如何将数据送给计算机。
从盘面中读取数据
我们知道再磁盘中,顺序读取会比随机读取快很多,那么有这么多盘面,磁道,这个顺序到底是什么顺序呢?
假设我们现在是再顺序遍历磁盘上的数据,那么读取顺序是这样的。首先读完最上面一块盘面的最外面一个磁道,等盘面旋转完一圈之后,即这个磁道被读取完毕,然后立即切换到第二块盘面,读第二块盘面的最外面一个磁道,以此类推,直到读完最底下一块盘面。然后磁臂在向内移动一个磁道,重复刚才的过程,直到读到最里面一个磁道。
其实再读取过程中还会更复杂一点,因为盘面是一直匀速高速旋转的,可能在一个扇区过度到下一个扇区的时候,就那么一点时间,可能存在误差,导致下一个扇区的数据没读到。为了解决这个问题,一般数据是在磁道上是间隔存储的。假设一个数据有10个扇区,分别为,d1,d2,。..,d10;为了说明这个思想,我们假设一个磁道正好也有10个扇区,分别为,s1,s2,。..s10。如果是紧挨着存放的话,那么扇区和数据的对应关系为:[(s1,d1), (s2, d2), 。.. , (s10, d10)]。这样就存在刚才说的有误差。那么间隔存储的话,映射关系为:[(s1,d1), (s3,d2), (s5,d3), 。.., (s2, d10)]。
而且在切换盘面的时候,虽然是电子切换,但是速度还是会有一定延迟,下一个盘面和上一个盘面的起始点位置不能一一对应,也是会有一定错开的。
在古老的磁盘里面,这些值可能还需要用户来设置,不过现在都是厂商给咱们设置好,用户不需要关心了。
由于磁臂的移动要比盘面的切换要慢很多(一个是机械切换,一个是电子切换),所以为了减少磁臂的移动,所以如上的顺序读取会是先读一个柱面,再读取下一个磁道,而不是先读完一个盘面,在读下一个盘面。
那么既然磁臂的移动如此的慢,刚才讲了顺序读取的时候的磁臂移动逻辑。那么在真实情况下,有大量随机访问的情况下,磁臂是如何移动的呢?这里就需要考虑常见的磁臂调度算法了:
RSS:随机调度。这个就是扯蛋,只是拿来给别人做绿叶对比性能用的。
FIFO:先进先出。这个对于随机读取来说,性能很不友好。
PRI:交给用户来管理。这个跟FIFO类似,只不过优先级是由用户来指定的,不仅增加了用户使用磁盘的成本,效率也不见得高。
SSTF:最短时间调度。这个是指磁头总是处理离自己这次请求最近的一次请求处理。这样最大的问题就是会存在饿死的情况。
SCAN:电梯算法。在磁盘上往复。这个是比较常见的算法,跟电梯类似,磁臂就一个磁道一个磁道的动,移动最外面或者最里面的磁道就转向。这个算法不会饿死。
C-SCAN:类似电梯算法,只是单向读取数据。磁臂总是再内圈到外圈的时候读取数据,当到达外圈过后迅速返回内圈,返回过程中不读取数据,在重复之前的过程。
LOOK:类似SCAN,只是会快速返回,如果前面没有读写请求就立即返回。
C-LOOK:类似C-SCAN和SCAN之间的关系。
一般来说,再IO比较少的情况下,SSTF性能会比较好,在IO压力比较大的情况下,SCAN/LOOK算法会更优秀。
大家可以到这里来看看硬盘读取数据的视频:/zixunimg/elecfansimg/v.ku6.com/show/2gl1CHY7iNa_CVLum3NQHg.html
将数据送给计算机
刚才我们从磁盘中读到了数据,接下来我们讲解磁盘通过什么样的接口跟计算机做交互。这个接口也叫磁盘管理协议。
磁盘管理协议的定义又分成两部分:软件和硬件。其中软件是指指令级,目前指令级就两个:ATA和SCSI;硬件代表数据传输方式,一般都是主板上的导线传输原理,但并不限制,数据甚至可以通过TCP/IP传输。定义一个协议需要同时定义了指令级以及硬件传输方式。
ATA
全称是Advanced Technology Attachment,现在看起来不咋地,不过从名字看来,当时这个东西还是很高级的。
这个指令是上个世纪80年代提出的。按照硬件接口的不同,又分成了两类,一类是并行ATA(PATA,一类是串行ATA(SATA)。一开始流行起来的是PATA,也叫IDE。不过由于并行线抗干扰能力太差,排线占空间,不利电脑散热。而更高级的SATA协议自从2000年被提出之后,很快PATA/IDE接口的磁盘就被历史淘汰,目前的ATA接口的磁盘只有SATA磁盘了。
SCSI
全称是Small Computer System Interface。也是上个世纪80年代提出来的,当时设计他的目的就是为了小型服务器设计的磁盘交互接口。用该接口可以达到更大的转速,更快的传输效率。但是价格也相对较高。
所以目前基本上在服务器领域SCSI磁盘会比较多,在PC机领域SATA硬盘会比较多。不过随着SATA盘的进化以及其得天独厚的价格优势,在服务器领域SATA也在逐步侵蚀SCSI的市场。
不过SCSI也不会坐以待毙,他按照PATA进化成SATA的思路,自己也搞串行化,进化出来了SAS(Serial Attach SCSI)接口。这个接口目前很对市场胃口,不仅价格低廉,而且性能也还不错。所以估计SATA淘汰PATA的一幕在不久的将来也会在SCSI领域里上演。
SCSI指令还可以通过Internet传输(iSCSI),通过FC网络传输(FC-SCSI),这些我们会再后文提及。
ssd
硬件原理
ssd是近些年才火起来的存储介质。ssd一般有两种,一种利用flash闪存为芯片,另一种直接用内存(DRAM)作为存储介质,只是在里面加了个电池,在断电以后还能继续用电池来维持数据。
我们本文中讲的ssd全部是都指代前者,即用flash闪存做存储介质。先来看一下ssd的存储原理。
在磁盘中0/1的表示是用的磁粉的南北极的信息,在闪存中则用的是电子信号。他利用的是一种叫浮动门场效应晶体管作为基本存储介质。在该晶体管里面,主要是由两个门电路构成:控制门和浮动门。在两个门之间有一堆电子。当控制门加上一个电势的时候,电子就往浮动门那边跑,然后控制门断开电势,电子会储存在浮动门那边(靠中间的二氧化硅绝缘层),则代表二进制中的0;控制门加一个反向电势的时候,电子跑回到控制门这边,浮动门那边没电子,代表二进制中的1。这样就通过检测浮动门那边的电势就能得到0或者1。而且现在有的ssd制造商,根据不同的电势,将一个晶体管表示的值从0/1拓展到0/1/2/3。这样就使得存储容量翻倍。这种类型的晶体管叫MLC(Multi Level Cell),相对,只表示0/1的叫SLC(Single Level Cell)。不过一般而言,MLC的出错率也高很多,所以目前市面上主流产品还是SLC的。
了解了ssd的基本原理之后,我们来看看ssd是怎么组织这些晶体管的。看如下几个概念:
Page。一般一个Page为4K。则该Page包含4K*8个晶体管,Page是ssd读写的最小单元;
Block。一般128个Page组成一个Block,Block的概念非常重要,读写数据的控制都是针对Block的,待会我们再重点讲一下Block的概念;
Plane。一般2048个Block组成一个Plane;
一块芯片再包含多个Plane,多个Plane之间可以并行操作。
Block的组织,见下图:
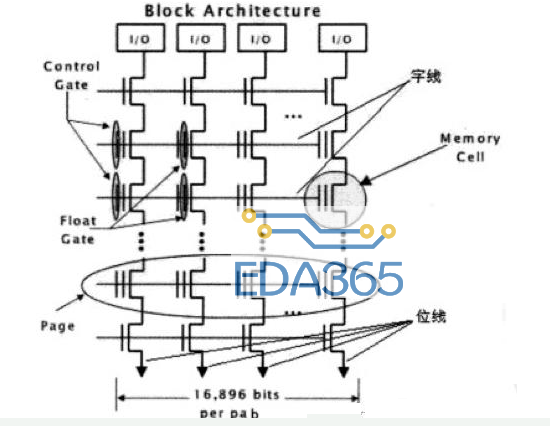
如图,可以看到block中的晶体管是按照井字型组织的。一横排就代表一个Page,所以一个Block一般就有128行,4K*8列。当然,由于还需要针对每个Page加一些纠错数据,所以一般还会多一些列。
横排是控制线,负责给电压,来做充电放电的作用;竖排是读取线,负责读浮动门里的电势之用。
读写过程
读取的过程是这样的:
假设要读取第三行数据,那么会给第三行控制线的电势置位0,其他127行控制线都会给一个电势,这样就能保证再竖排的读取线上只读到第三行的数据,而读不到其他数据。可以看到ssd再读取数据的时候不再需要寻道这些复杂的事情,速度会比传统的磁盘块很多。
而ssd写入就比较麻烦了,因为ssd无法再一个block内对部分cell充电,对部分cell放电,这样信号会相互干扰从而造成不可预期的情况发生。那ssd怎么处理这个问题呢,那就暴力了,把一个block的数据全部读到ssd自带的内存当中,并做好修改,接下来把整个block全部放电,即擦除所有数据,最后再将内存中整个block写回。可以看到,即使是只修改一个bit的数据,也需要大动干戈,倒腾4K*128这么多数据,所以ssd写数据的代价是很大的。但是瘦死的骆驼比马大,比起机械硬盘,还是要快好几个数量级的。
而且,ssd还有一个很头疼的问题,就是随着充放电次数的增加,中间的二氧化硅绝缘层绝缘效果会逐步降低,当降低到一定程度之后浮动门保存不住电子了的话,这个晶体管就算废了。所以单个晶体管还有擦写次数寿命,目前主流的晶体管这个上限大概是10万的数量级。而MLC的更差,只有1万次左右。
那么针对如上两个问题,ssd目前一般都有哪些解决方案来应对呢?
为了优化写的时候的性能,一般ssd并不在写的时候做擦除。而是在写数据的时候,选择另外一块干净的block写数据。对于老的block数据,会做一个标记,回头定期做擦除工作;
对于坏掉的晶体管,可以通过额外的纠错位来实现。根据不同的纠错算法,可以容忍同一个Page中坏掉的位的个数也是不一样的。如果超过上限,只能报告说不可恢复的错误。
常见存储介质性能数字
最后我们来对比一下目前主流的硬盘和ssd的参数,这是笔者在工作中测试得到的数据,测试数据为各种存储介质在4K大小下的随机/顺序 读/写数据,数字做了模糊化处理,保留了数量级信息,大家看个大概,心里有数即可:
测试项\磁盘类型 | SATA | SAS | SSD |
顺序读(MB/s) | 400 | 350 | 500 |
顺序写(MB/s) | 200 | 300 | 400 |
随机读(IOPS) | 700 | 1300 | 7w |
随机写(IOPS) | 400 | 800 | 3w |
硬盘组合
上面一节中,我们了解了单个磁盘的存储原理和读写过程。在实际生产环境中,单个磁盘能提供的容量和性能还是有限,我们就需要利用一些组合技术将多个磁盘组合起来提供更好的服务。
这一节,我们主要介绍各种磁盘组合技术。首先,我们会看一下最基本的组合技术RAID系列技术;然后,我们在看一下更大规模的集成技术SAN和NAS。
RAID
RAID技术是上个世纪80年代提出来的。
RAID0:条带化。读写效率都很高。但是容错很差。
RAID1:镜像存储。读效率可达2倍,写的时候差不多。容错牛B。
RAID2 & RAID3:多加一块校验盘。在RAID0的基础之上多了容错性。RAID2和RAID3的区别是使用了不同的校验算法。而且这两个的校验是针对bit的,所以读写效率很高。
RAID4 & RAID5 & RAID6:这几个都是针对block的,所以效率比RAID2&RAID3要更差一些。RAID4是没有交错,有一块盘就是校验盘;RAID5是有交错,每块盘都有数据和校验信息;RAID6是双保险,存了两个校验值。
目前用得比较多的就是Raid5和Raid1。
Raid的实现方式一般有两种:软Raid和硬Raid。软Raid是指操作系统通过软件的方式,对下封装SCSI/SATA接口的硬盘操作,对上提供虚拟硬盘的接口,中间实现Raid对应逻辑;硬Raid就是一个再普通的SCSI/SATA卡上加了一块芯片,里面执行可以执行Raid对应的逻辑。
现在一般的Raid实现方案都是硬Raid,因为软Raid有如下两个确定:
占用额外的内存和CPU资源;
Raid依赖操作系统,所以操作系统本身无法使用Raid,如果操作系统对应的那块硬盘坏了,那么整个Raid就无法用了;
现在Raid卡一般都比较高级,可以针对插在上面的多块磁盘做多重Raid。比如这三块磁盘做Raid5,另外两块做Raid1。然后对操作系统提供两块『逻辑盘』。这里的逻辑盘对操作系统而言就是一块磁盘,但实际底层可能是多块磁盘。
逻辑盘不一定要占据整块独立的磁盘,同样RAID的几块盘也可以做成多块逻辑盘。假设有三块磁盘做成了Raid5,假设一共有200G空间,也可以从中在划分成两块,每块100G,相当于用户就看到了两块100G的磁盘。不过一般逻辑盘不会跨Raid实现。倒不是不能做,而是没需求,而且对上层造成不一致的印象:这磁盘怎么忽快忽慢的呀。
这个逻辑盘还有一个英语名字:LUN(Logic Unit Number),现在存储系统一般把硬件虚拟出来的盘叫『LUN』,软件虚拟出来的盘叫『卷』。LUN这个名词原本是SCSI协议专属的,SCSI协议规定一条总线最多只能接16个设备(主机或者磁盘),在大型存储系统中,可能有成千上万个设备,肯定是不够的,所以发明了一个新的地址标注方法,叫LUN,通过SCSI_ID+LUN_ID来寻址磁盘。后来这个概念逐步发展成为所有硬件虚拟磁盘了。
操作系统看到逻辑盘之后,一般还要再做一次封装。逻辑盘始终都还是硬件层在做的事情,硬件层实现的特点就是效率高,但是不灵活,比如逻辑盘定好了100G就是100G,空间用光了想要调整为150G就只有干瞪眼了,实现成本很高。为了达到灵活性的目的,所以操作系统还要再做一层封装『卷管理』。这层卷管理就是把逻辑盘在软件层再拆分合并一下,组成新的操作系统真正看到的“磁盘”。
最后操作系统再在这些卷上面去做一些分区,并在分区上安装操作系统等工作。
磁盘独立闹革命
上面都是讲的单台机器内部的磁盘组织方式,而单台机器所提供的存储空间是有限的,毕竟机器大小空间是有限的,只能放得下那么几块盘。在一般的2U的机器里面能放得下20块盘就算是很不错的了。在实际工业需求中,对于一些大型应用来说,肯定是远远不够的。而工业界采用的方案就是:堆磁盘,单台机器装不下这么多磁盘就单独拿一个大箱子来装磁盘,再通过专线接到电脑接口上。
当然,在近些年又发展起来了一块新的技术领域大数据存储的市场——分布式存储。分布式存储价格便宜,但是性能较低,占据了不少不需要太高性能和查询语义不复杂的市场。分布式存储我们后面再谈,现在先看看堆磁盘这条路。
当磁盘多了之后,人们发现,磁盘容量是上去了,但是传输速度还是上不去。默认SCSI的导线传输机制有如下几个限制:
规定最多只能接16个设备,也就是说一个存储设备最多只能有15台机器来访问;
SCSI导线最长不能超过25米,这对机房布线来说造成了很大的挑战;
于是SCSI在一些企业级应用市场开始遭到嫌弃,于是人们就寻求别的硬件解决方案,人们找到了:FC网络。
FC网络是上个世纪80年代研究网络的一帮人搞出来的网络交互方式,跟以太网是同类产品,有自己完整的一套OSI协议体系(从物理链路层到传输层以及应用层)。他就是以太网的高富帅版本,价格更贵,性能更高。而当时FC网络也主要是为了高速骨干网设计的,人家都没想到这东西还在存储系统领域里面大放异彩。
这里提一下,FC中的F是Fibre,而不是Fiber。前者是网络的意思,而不是光线。虽然一般FC网络都采用光纤作为传输介质,但是其主要定义并不只是光纤,而是一整套网络协议。
但是不管怎么样,FC网络的引入,完美解决了SCSI导线的问题:
FC网络就跟以太网类似,有自己的交换机,网络连接方式和路由算法,可以随便连接多少个设备;
光纤传输最大甚至可以有上百公里,也就是说主机在北京,存储可以在青岛;
传输带宽更大;
并且只是替换了硬件层的东西,指令集仍然是SCSI,所以对于上层来说迁移成本很低,所以在企业级应用里得到了广泛使用。
就目前主流的存储协议:短距离(机内为主)使用SAS,长距离使用FC。
经过如上的系列技术发展,大规模存储系统的技术方案也就逐渐成熟了,于是市面上就逐步出现了商业化的产品,其实就是一个带得有一堆磁盘的盒子,这个盒子我们把它叫做SAN(Storage Area Network)。
说到SAN,就必须要提另外一个概念:NAS(Network Attach Storage)。因为字母都一样只是换了个顺序,所以比较容易混淆。NAS其实就是SAN+文件系统。SAN提供的还是磁盘管理协议级的接口(ATA/SCSI);NAS直接提供一个文件系统接口(ext/NTFS)。但是一般来说,SAN都是以FC网络(光纤高速网状网络)提供给主机的,所以性能高;而NAS一般都是通过以太网接入存储系统的,所以性能低。
另外,经常跟SAN和NAS一起的还有另外一个概念,DAS(Direct Attached Storage)。这个跟SAN类似,只是DAS只能被一台机器使用,而SAN提供了多个接口可以供多个用户使用。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

") 存储器知识大科普(一)
存储器知识大科普(一)









 APP下载
APP下载 登录
登录







