×


今年 5 月,已经得到微软 Azure 算力加持的OpenAI放出了 GPT-3 这个巨型 NLP 模型怪兽,包含 1750 亿参数,比 2 月份微软刚推出的全球最大深度学习模型 Turing NLG 大上十倍,是其前身 GPT-2 参数的 100 倍。
我们可以用一张图表来直观感受下 GPT-3 所处在位置,是不是有点高处不胜寒的感觉?
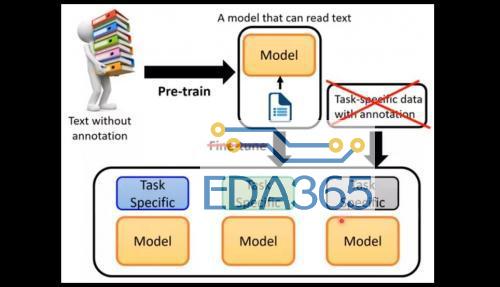
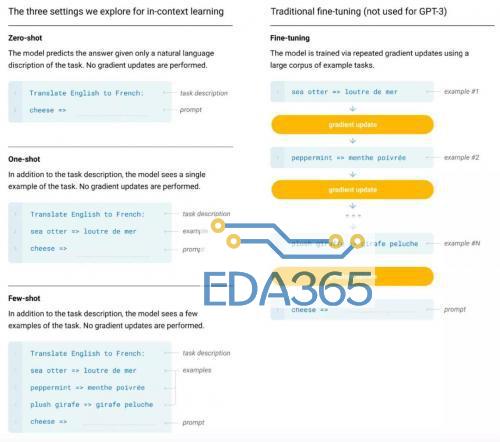
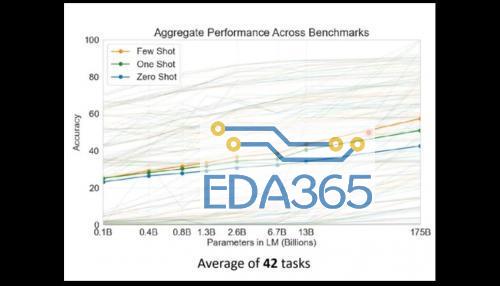
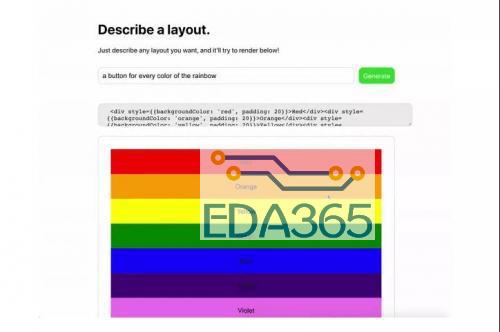
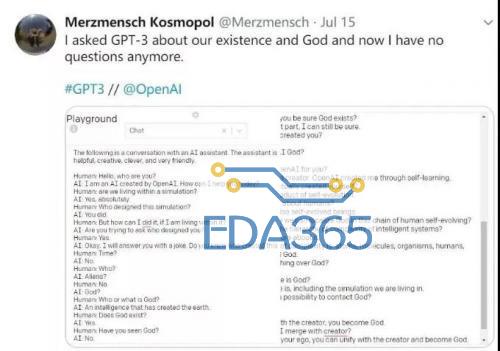
同时,GPT-3 使用的训练数据集也十分庞大,基于包含近 1 万亿单词量的 CommonCrawl 数据集、网络文本、数据、维基百科等数据,数据量达到了 45TB。其训练费用也达到惊人的 1200 万美元,这已经是个人开发者和小型 AI 开发团队无法轻易染指的训练规模和成本了。 在最近大量有关 GPT-3 的介绍文章里,很多人都注意到的是这个模型惊人的体量和各种各样脑洞大开的文本生成能力,不仅是写文章、编故事、搞翻译,还包括多轮对话、写代码、做数学运算、表情包配文、做表格、生成图标等等,几乎是在文本方面为所欲为了。 有人惊呼“真正的 AI 已经到来”、“GPT-3 可以改变世界了”,也有人说“GPT-3 是一种形象工程”、“一种赤裸裸的炫富”。 无论评价如何,人们其实都并未过多注意到 OpenAI 现在发布 GPT-3 的 API 接口的一大原因是推动这一技术的商业化。现在,GPT-3 模型已经广泛应用的领域当中,有哪些领域更好地进行商业化尝试,又有哪些领域仍然差强人意,这些也许是更值得我们去探讨的地方。 GPT-3 到底有多厉害? 相较于之前的 GPT-2,这次 GPT-3 有哪些明显的进步呢? 从训练方式来说,与之前版本并没有什么不同,GPT-3 依旧延续之前的单向语言模型训练方式,只不过就是训练数据和参数有了几个数量级的提升。但从实际的效果来看,GPT-3 的尝试至少验证了一点,就是将一个深度神经网络不断增大,它确实可以变得更加的聪明。 相较于当前的 BERT 模型,GPT-3 主要能够解决两个问题,一个是避免对各领域内的标注数据的过分依赖,一个是避免对各领域数据分布的过度拟合,从而调教出一个更通用、更泛化的 NLP 模型。GPT-3 的主要目标是用更少的领域数据,还有去掉微调步骤去解决问题。 (图源:李宏毅《深度学习人类语言处理》) 直观来理解就是如图所示,GPT-3 就是要拿掉 Fine-tune(微调)这个环节,也拿到 Task-Specific 的示例资料,来直接对特殊的领域问题进行回答。 基于此,研究者们使用 GPT-3 在不同形式下进行了推理效果的测试,包括 Zero-shot、One-shot、Few-shot 三种,但是这三种形式都是不需要经过 Fine-tuning 的。因为 GPT-3 选择的是单向 transformer,所以它在预测新的 token 时,会对之前的 examples 进行编码。 那么,测试结果如何呢? 从各领域的 42 项基准测试中的平均表现来看,随着参数量的不断加大,其正确率在不断提升(当然有人会质疑,模型提升了 10 倍参数量,正确率才提升不到 1 倍),其中 Few Shot 的表现是最好的。 而在封闭式的 Trivia QA 问答中,GPT-3 的 Few-Shot 的表现已经可以好过经过 Fine-tuned SOTA 的成绩。此外在 SuperGLUE 测试上面也能达到超过当前 SOTA 的表现,以及生成非常逼真的文章,甚至能达到人类难以分辨是机器还是人类协作的程度。 那么,在当前人们调用 OpenAI 开放的 API 接口之后,我们已经可以看到 GPT-3 的一系列的有趣案例了。 GPT-3 现在能够出色地完成翻译、问答和完形填空任务,能够很好执行两位、三位的数学加减运算。还可以基于文本的描述生成代码、网站。 (GPT-3 将自然语言生成了代码和图形按钮) 可以为文本转换不同文体样式,比如把口语化变为书面语,把日常语言变为法律文书。或者把繁荣的法律语言变成日常语言,比如那些长长的“用户协议”。 (GPT-3 将日常语言转换为法律文书) 当然,GPT-3 的主业更在于生成文本内容,比如段子、新闻、小说,甚至给出主题和关键词,都可以有模有样地编出一篇完整的论文。 (仅给出标题和开头,GPT-3 就完成了论文) 在和人类的多轮对话中,GPT-3 表现也相当出色。比如下面这个名为 Kosmopol 的程序员和 GPT-3 展开了一段关于人类、AI 与神的存在关系的“神秘”讨论。 (聊到最后程序员表示,“我现在已经没有任何疑问”) 从现在网络上所发布出来的 GPT-3 的各项表现来看,GPT-3 似乎在任何文本生成相关的领域都能发挥作用了。 那么 GPT-3 在商业化方面的前途如何呢? GPT-3 有哪些商业化前景? 我们记得,在 GPT-2 发布时,OpenAI 还不愿意一下子把 GPT2 的模型完整地放出来,而是选择挤牙膏似的一点点公布完整版本,当时的理由是认为 GPT-2 太过危险,会被人用来制造假新闻,用来做邮件诈骗等坏事。当然,可怕的后果并没有发生,也许是坏人的技术能力不够,更主要可能是应用的成本门槛太高。 这一次,OpenAI 选择了发布 API 接口邀请测试,而非直接开源模型的方式,同样也有这方面的考虑。如果模型开源,一旦有人在此基础上开发带有危险性的应用程序,官方将很难制止。通过 API 方式就可以很好应对人们对技术的滥用。 与此同时,由于 GPT-3 如此庞大体量的基础模型,除了少数大公司之外,很少有机构和个人能够对其进行开发和部署,运行费用也将极其昂贵。 其实更重要一点则是,OpenAI 希望通过 API 方式来推动 GPT-3 的技术商业化,未来在安全可靠、政策合规的基础上进行相关 AI 产品的开发,并实现商业化的盈利。 据目前 OpenAI 透露,在提供 API 之前,就已经与十几家公司展开了初步的商用测试。具体开放功能话,GPT-3 可以在语义搜索、聊天机器人、生产力工具、文本生成、内容理解、机器翻译等方面进行商业化应用。 比如,一家初创搜索公司 Algolia 正在使用 GPT-3 来进行自然语言的复杂搜索,具体表现在能够将预测时间缩短到 100 毫秒左右,并以比 BERT 快 4 倍的速度准确地回答复杂的自然语言问题。 在生产力工具方面,GPT-3 的 API 可以提供更多元化的功能,比如将文本分解为图表、表格、电子邮件汇总,可以从项目要点进行内容扩展。对于编程工作来说,程序员可以通过自然语言来与计算机进行对话,不必记住各种复杂命令,也能获得自己想要的基础代码。 此外,像在文档写作中的拼写建议、语法纠错,以及像法律机构、律所相关工作中的判例索引,法律研究,模式化的诉讼申请撰写,教育教学机构的教学材料辅助查找和示例,在线客服的聊天机器人等方面,都可以实现商业化应用。 这样一看,好像 GPT-3 的横空出世,不仅是让媒体编辑(不久前微软就开掉了一批人工编辑)直接遭遇职业危机,甚至看来很多机构的基础文员、在线客服,甚至程序员也有下岗再就业的危险了? 不过,从目前 GPT-3 所公开展示的示例来看,这种担忧还是有些大可不必。直接来讲,GPT-3 作为企业的生产力工具,更多会起到辅助性提升效率工具的作用。在任何需要进行文本的生成、资料检索和需要启发性的内容生产方面,都可以使用 GPT-3 来作为辅助工具。 比如,作家可以使用关键词来获得 GPT-3 提供的创意思路,来获取灵感。公司职员和机构的文员可以用会议纪要来生成相应专业性的报告、邮件和专业文书。 在这一过程中,我们不可能说完全去掉人类的审查和订正就直接使用和发布。显然,无论哪个机构或个人都不会让 AI 模型来承担其发布内容的责任。当然,当一些人能够更好地与 GPT-3 这样的人工智能工具进行高效协作,提升企业组织的生产效率,随之而来的是企业对基础职位人数需求的减少。从这个意义上,GPT-3 作为职位大杀器的作用会间接显现。 不过,现在的 GPT-3 已经能堪当大任吗?从一些开发者测试后的反馈和一些专家的评论来看,GPT-3 距离真正的商业化还有一定的距离,其中一些问题必须要解决。 GPT-3 的商业化难题 当外界对于 GPT-3 的能力表现发出更多赞誉的时候,OpenAI 联合创始人 Sam Altman 则在 Twitter 站出来表示,“GPT-3 被吹捧得太过了”。 实际上,这一表态确实很实事求是。目前 GPT-3 在常识问答、事实性的文本生产问题上表现尚佳,但是一旦处在反事实的或者矛盾问题的问答上面,GPT-3 就会表现出一种“不懂装懂”的幼稚化倾向。 比如,在上面这些反事实提问或者无意义的语言重复下,GPT-3 就开启了“尬聊”模式。用纽约大学副教授 Julian Togelius 的话来说就是,“GPT-3 常常表现的像一个没有完成阅读的聪明学生,在考试中胡言乱语试图蒙混过关。一些众所周知的事实,一些半真半假的事,还有一些直接的谎言,串在一起乍一看像是流畅的叙事。” GPT-3 在一些输出上也会犯一些带有偏向性的低级错误。比如有人在通过 GPT-3 与虚拟的乔布斯谈话中,在问到乔帮主现在身处何处,






『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 无人机新突破:或将利用手机发射塔追踪无人机
无人机新突破:或将利用手机发射塔追踪无人机






 APP下载
APP下载 登录
登录







