×


MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(规约)”,和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。MapReduce极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(规约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
第一步:清楚问题是什么,确定解决问题的算法思路。
第二步:设计和实现mapreduce程序中的Mapper接口,Reducer接口。它们是MapReduce作业的核心。 (0.20.2以后的API使用Mapper和Reducer抽象类,这样便于扩展)
Mapper Mapper 将输入一个的key/value映射到0个或者多个中间格式的key/value形式。 用户需要实现map(WritableComparble,Writalbe,OutputCollector,Reporter)方法完成输入到输出的处理。同时可以选择重写JobConfigurable.configure(JobConf)方法完成Mapper的初始化工作;重写Closeable.close( )方法执行Mapper的清理工作。因为MapReduceBase实现了JobConfigurable和Closeable接口,因此程序只要继承MapReduceBase就可以。 程序通过调用OutputCollector.collect(WritableComparable,Writable)
方法收集输出的键值对(Mapper输出键值对不需要与输入键值对的类型一致),通Reporter报告进度,更新Counters表明自己正常运行。 至此Mapper过程结束,下面进入Sort&Shuffle过程。
Sort&Shuffle
得到mapper输出的中间结果后,传递给Reducer执行前会经历一个分组-》合并-》分配的过程。
1. 框架会按照key值,把所有中间结果的进行分成组。用户可以通过 JobConf.setOutputKeyComparatorClass(Class)来指
定具体负
责分组的Comparator。
2. 用户可以通过JobConf.setCombinerClass(Class)指定一个combiner,它负责对 中间过程的输出进行本地的聚集,这会有助于降低从Mapper到Reducer数
据传输量。(如WordCount会把key值相同的次数累加)
3. 用户可以指定或者自定义实现Partitioner来控制具体的key被分配到那个Reducer。Partitioner通常使用的是Hash函数。HashPartitioner是默认的Partitioner。Partitioner分块的总数目和一个作业的reduce任务的数目是一样的。
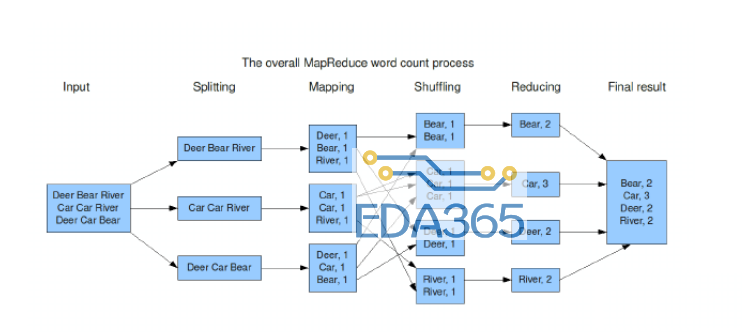
Sort&Shuffle的过程至此结束,Reducer过程开始。
Reducer Reducer会把Mapper的输出作为输入,因此Reducer的输入类型需要与Mapper的输出类型一致,Reducer任务会将输入的key/value归并为一个更小的结果集。用户需要实现 reduce(WritableComparable, Iterator, OutputCollector, Reporter)方法来对输入的key/value进行处理,同Mapper过程一样,用户可以选择重写JobConfigurable.configure(JobConf)方法完成Mapper的初始化工作,重写Closeable.close()
方法执行Mapper的清理工作。 用户可以通过JobConf.setNumReduceTasks(int)来设定一个作业中reduce任务的数 目。 Reduce任务调用OutputCollector.collect(WritableComparable, Writable)将处理结果写入HDFS。任务通过Reporter报告进度,至此MapReduce任务结束。
OutputCollector
OutputCollector是一个MapReduce框架提供的用于收集Mapper或Reducer输出数据的通用机制 (包括中间输出结果和作业的输出结果)。同时hadoop类库提供了丰富的outputFormat以供选择,支持文本输出,二进制输出,序列化输出,数据库输出等等。
Writable
Hadoop中,节点之间的进程通信通过RPC(remote procedures call)来实现。RPC中将消息序列化为二进制流,此后,将二进制流反序列化为消息,是进程间通信的灵魂所在,因此可用的RPC具有,紧凑,快速,可扩展,互操作等特点。 Hadoop实现了自己的序列化机制,相比于java自带的序列化java object serialization,Hadoop的序列化更加紧凑,快速。同时Hadoop封装了java中的基本类型,便于进程间的通信,用户也可以自定义Writable类,只要实现Writable接口即可。
JobConf
JobConf代表一个MapReduce作业的配置。框架会按照指定的配置信息去完成MapReduce任务,其中的配置信息比较多,有兴趣的可以去官网了解http://hadoop.apache.org/。通常,JobConf会指明Mapper、Combiner、Partitioner、Reducer、InputFormat和OutputFormat的具体实现,一组输入文件,以及输出文件的目录。
mapreduce程序与很多编程有所不同,它是一种函数型编程,完全地展现了“分而治之”的哲学思想,是分布式系统下一种强有力的处理工具。
因而,用户编写mapreduce程序时,一方面要具备mapreduce程序思想;另一方面要符合mapreduce程序开发流程。同时,通过多写mapreduce程序,掌握并熟悉这种编程模型。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 PIC18FXX8单片机通用同步异步收发器的接口电路和C源代码
PIC18FXX8单片机通用同步异步收发器的接口电路和C源代码





 APP下载
APP下载 登录
登录







