×


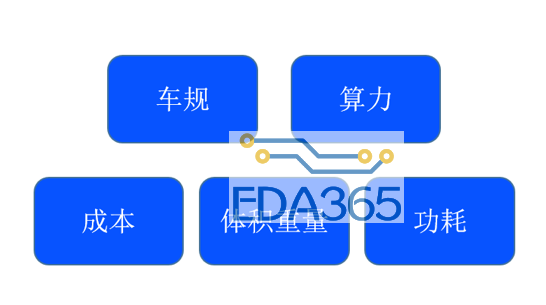
人工智能技术是自动驾驶的基础,算法、算力和数据是其三大要素。本文探讨的就是其中的“算力”。算力的高低,不仅直接影响了行驶速度的高低,还决定了有多大的信息冗余用来保障驾驶的安全。算力最直观地体现在硬件上,而汽车对自动驾驶的控制器有特殊的要求。
除了对一般硬件的成本、体积重量、功耗的要求外,还要求:提供足够的算力,保证行驶速度和信息冗余。满足严苛的车规标准,比如超宽的温度范围,-40℃ – 85℃。综合来看 FPGA 是适合自动驾驶高速计算的技术。
实践中遇到的挑战是,多种多样的加速需求和有限的硬件资源的矛盾。需求的来源既包括深度学习前向推测、也包括基于规则的算法。硬件资源受限包括了:FPGA 资源受限和内存带宽受限。
FPGA 资源的有限性体现:峰值算力受限:有限的 FPGA 资源限制了计算并行度的提高,这约束了峰值算力。支持的算子种类受限:有限的 FPGA 资源只能容纳有限个算子。内存带宽受限体现在:内存数据传输在计算总时间中占据了不可忽略的时间。极端情况下,对某些算子提高并行度后,计算时间不减。为应对这些挑战,我们在实践中提取了一些有益的经验,总结出来与大家共享。
算法工程师采用浮点数 float32 对模型进行训练,产出的模型参数也是浮点型的。然而在我们使用的 FPGA 中,没有专用的浮点计算单元,要实现浮点数计算,代价很大,不可行。使用 int8 计算来逼近浮点数计算,也即实现量化计算,这是需要解决的第一个问题。
<>符号表示四舍五入,两个<>把矩阵A和B的元素线性映射到区间[-127, 127],在此区间完成乘法和加法。最后一个乘法把整型结果还原成 float32。在量化前,需要完成1000000次 float32 的乘法。量化成 int8 后,需要完成1000000次 int8 的乘法,和30000次量化、反量化乘法。

由于量化和反量化占的比重很低,量化的收益就等于 int8 取代 float32 乘法的收益,这是非常显著的。
这种方法的好处是,每次计算既能充分利用 int8 数据的表征能力(127总能被使用到),不存在数据饱和的情况(所有元素都被线性映射),保证单次计算的精度最高。可以直接接受浮点训练的模型,维持准召率。Resnet50 测50000张图片,Top1 和 Top5 准确率下降1%。在 Valet Parking 产品用到的多个网络中,没有观察到准召率下降。缺点是,FPGA 计算有截断误差,经过多次累计,数值计算误差最大平均可以达到10%。对于一些训练不完全成功的模型(只在有限评测集上效果比较好),准召率下降明显,结果不可控。
已知量化尺度:静态量化,如果上面的式子变成经过线下统计,量化尺度被固化为 scaleA 和 scaleB,表示四舍五入,并且限制在[-127, 127]之内。这种方法的好处是节约了 FPGA 资源。可以很方便地采用跟量化推测一致的训练方法,推测和训练计算数值误差很小,准召率可控。缺点是,要求模型训练采用一致的量化方法。否则,计算误差很大,不可接受。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 详细剖析视频显示系统
详细剖析视频显示系统






 APP下载
APP下载 登录
登录







