×


2019年VLSI研讨会在日本结束后,台积电举行了小型新闻发布会,并在SEMICON West期间发表了有关封装的演讲,本文将对上述事件中台积电提到的技术进行总结。
7nm节点(N7)
台积电认为他们的7nm节点(N7)是目前最先进的逻辑技术。在最近的VLSI研讨会上,台积电撰写了一篇有关于他们7nm节点的论文,除了少数主要客户外,大多数客户直接从16nm节点跳到7nm节点,而10nm节点被认为是一个短暂的节点,主要是为了测试良率。从16nm到7nm,7nm节点提供了3.3倍的晶体管密度,以及大约35-40%的速度提升和65%的功耗降低。

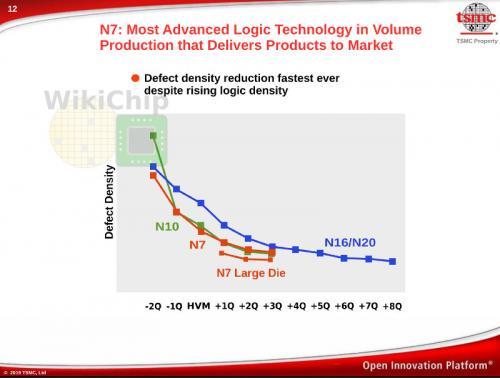
7nm工艺的一个关键亮点是缺陷密度。台积电表示,从其10nm节点吸取教训,7nm节点的缺陷密度曲线下降趋势是有史以来最快的(见下图)。随着公司进军高性能计算(HPC)领域,他们分别开始为移动客户和HPC客户报告晶圆尺寸为250平方毫米及以上的缺陷密度。
过去半年,台积电对7nm节点的需求环比下降约1%。收入绝大部分仍来自于他们非常成熟的16nm节点。不过,虽然台积电第二季度晶圆出货量符合预期的增长,但是与长期趋势相比,这实际上是三年来第二季度的最低销量。尽管如此,他们相信7nm将在全年实现25%的收入。
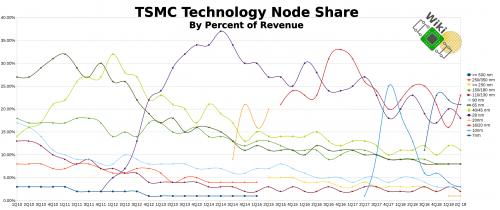
按收入份额划分的技术节点
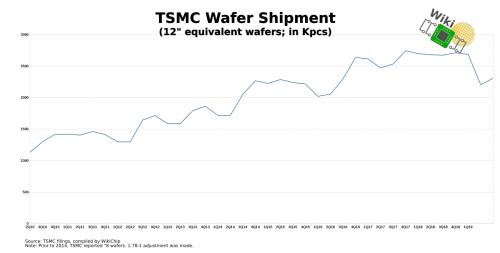
台积电晶圆出货量
7nm 2代(N7P)
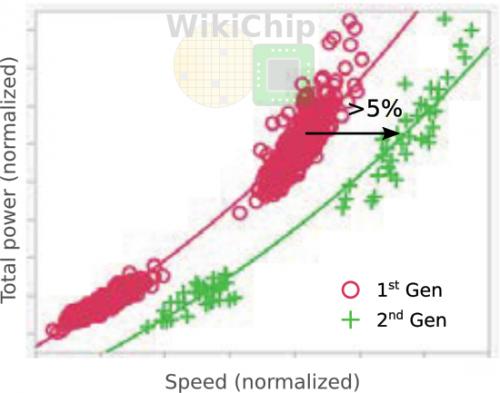
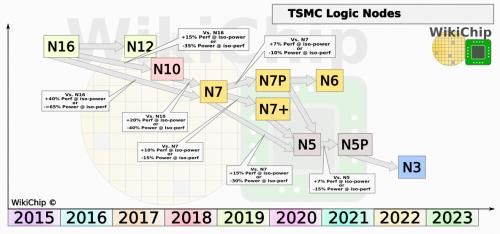
台积电已经开始推出7nm制程的优化版本,称为7nm性能增强版(N7P),它还有诸如“第二代7nm”等别称。这个制程不能与N7+混为一谈,N7P是一个基于DUV的优化流程,它与N7使用相同的设计规则,并且IP完全兼容。N7P引入了FEOL和MOL优化,可以在等功率下提高7%的性能,或者在等速时降低10%的功耗。
7nm+工艺(N7+)
N7+是台积电第一个在几个关键层采用EUV的工艺技术,其在第二季度进入量产阶段,产量与N7相似。同N7工艺相比,N7+的密度提高了1.2倍左右。据称,N7+在等功率时性能提高10%,在等性能下可降低15%的功耗。从表面上看,N7+似乎比N7P稍好一些。不过,这些改进只能通过新的物理重新实现和新的EUV掩模来获得。
6nm工艺(N6)
N6是与N7相当的EUV,计划使用比N7+更多的EUV层。它既是设计规则,也是与N7兼容的IP,是大多数客户的主要迁移路径。N7的设计可以在N6上再次利用EUV掩模和保真度改进,或者重新实施,以利用聚超扩散边缘(PODE)和连续扩散(CNOD)标准单元基台规则,台积电表示N6可提供额外的18%密度改进。值得强调的是,N6实际上将在明年初进入风险生产阶段,并在2020年年底前达到峰值。这意味着它将在N5之后崛起。因此,台积电表示,N6建立在N7+和N5 EUV经验的基础上。
5nm工艺(N5)
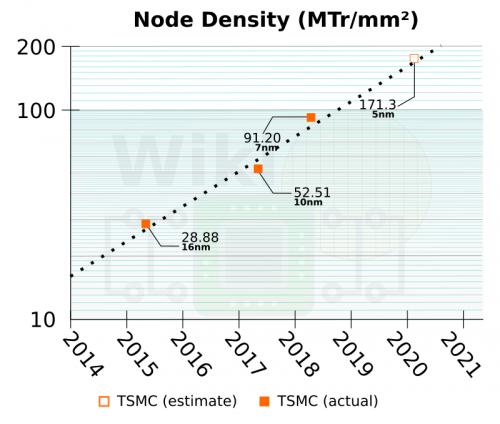
N5是N7之后的下一个“全节点”。N5在今年第一季度进入了风险生产阶段,他们预计该替代过程将在2020年上半年逐步扩大。台积电曾表示,一些减产工作已在进行中。N5在“多层”上广泛使用EUV,已显示出非常高的产量,并表示就D0而言,它们与N7工艺的发展轨迹相似。N5计划作为一个长期存在的节点,预计在收入方面的增长速度将超过N7。
与N7相比,N5可提供1.8倍的逻辑密度。在性能方面,N5在等功率时的性能将提高15%,在等性能下可提供高达30%的低功耗。与N7一样,N5也有两种风格——移动用户和HPC。与N7相比,HPC性能将提供高达25%改进的额外选项。

据我们估计,明年初,台积电将比英特尔和三星领先一个“完整节点”。
5纳米增强版(N5P)
与7纳米工艺一样,台积电提供的N5工艺优化版本,称为N5性能增强版(N5P)。此过程使用相同的设计规则,并且与N5完全IP兼容。通过FEOL和MOL优化,N5P在等功率时性能比N5提高7%,在等性能下功耗比N5低15%。他们对于N5P的发布时间有点模糊,但有一些暗示在2020年底或2021年初。
3nm工艺(N3)
台积电表示,他们的3纳米工艺进展非常顺利,预计将在2022年左右推出。尽管此前曾表示,GAA可能成为FinFET的接班人,但台积电和英特尔都在努力证明,目前更容易制造的FinFET可以在性能上得到足够的扩展。目前我们认为,台积电可能会继续使用FinFET实现其N3,但将在后续节点中转移到GAA。
新一代的包装
随着前沿节点的复杂性和成本的增加,对基于芯片的解决方案需求不断增长。将模具拆分为更小的芯片,以实现产量和分片目的,用旧的、成熟的、用于模拟的节点和SoC的其他部分节点,通过诸如HBM等组件实现更高的系统集成,这些节点能得到很好地扩展。
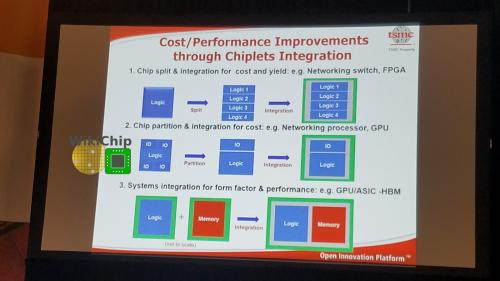
台积电提供了许多技术,作为其晶圆级系统集成(WLSI)平台的一部分,该平台旨在涵盖从低空闲移动应用程序到HPC的所有领域。他们的芯片-晶片-基板封装的目标领域是人工智能、网络和HPC应用,而其集成Info的目标领域是网络和移动应用。

TSMC InFO封装是他们的通用基板晶圆级封装(FOWLP)解决方案,根据应用有许多不同的风格。InFO使用密集的RDL和精细间距通过封装过孔(台积电也通过InFO过孔或TIV调用)。它们集成在基板(InFO_oS)上,带有基板存储器的InFO(InFO_MS)和InFO超高密度(InFO_UHD)适用于从高性能移动设备到网络和HPC应用的任何设备。

特别是对于5G移动平台,台积电为移动AP应用程序提供了InFO POP,其中的InFO_aip用于射频前端模块(fem)应用程序,多堆栈用于基带调制解调器。

用于更高带宽的3D MIM
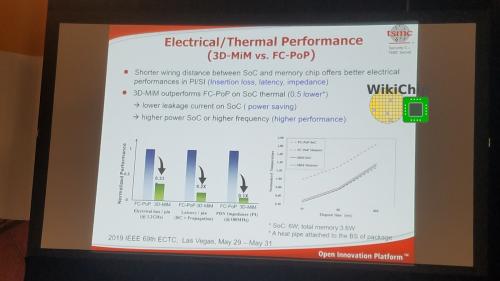
InFO_POP最早的例子之一是2016年发布的苹果A10(以前的处理器以传统POP为特色)。然而,即使InFO_POP也存在由于控制器和TIV音调而导致内存带宽受限的缺点。这个问题在即将到来的5G和AI边缘计算、移动应用程序中将进一步恶化,这些应用程序本质上限制了更多的内存带宽。为了克服这一问题,台积电发布了3D-MUST-in-MUST封装技术(MUST代表多堆叠)。3D-MiM采用高密度的RDL和细间距TIV,通过基板(InFO) WLS集成多个垂直堆叠的存储芯片。可以想见,I/O必须暴露在独立连接到SoC的芯片的一侧,成一个广泛的I/O接口。

台积电在一个集成了16块内存芯片的SoC上演示了该技术。芯片的尺寸为15毫米×15毫米, 高度仅为0.55毫米。与倒装芯片POP封装相比,该芯片的内存带宽是其两倍。
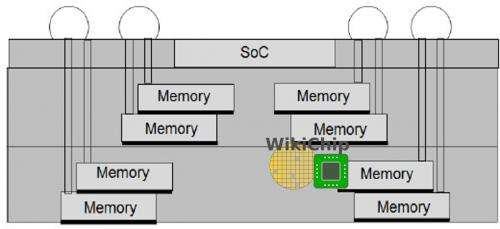
由于没有基板和凸起,从存储器I/O到SoC的距离要短得多,从而产生更好的电气性能特性。此外,更薄的外形可提供更好的散热性能。
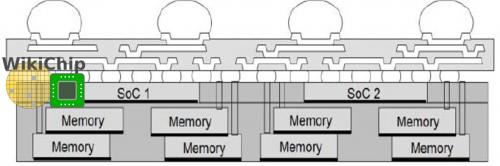
顺便说一下,3D MIM并不局限于单个SOC。实际上,台积电谈到了使用多个SoC和大量的内存芯片来创建高带宽、低功耗的HPC应用,作为当前2.5D的替代技术。这里的一个关键区别是,每个InFO存储器芯片分别直接连接到SOC,而不需要基本逻辑模块。
InFO天线封装(InFO_AiP)
以5G毫米波系统集成为目标,台积电开发了InFO天线封装。该封装试图解决的是实际芯片和天线之间的链路或互连,这可能会造成严重的传输损耗。台积电通过在RDL中的槽耦合补丁以及成型化合物中的嵌入式射频芯片来实现,该芯片直接与RDL互连。
由于天线和芯片之间互连的性能是表面粗糙度、芯片和封装之间过渡的函数,InFO材料和RDL均匀性允许更低的传输损耗。与倒装芯片AiP相比,台积电声称它可以提供高达15%的性能提升,热阻降低15%,同时具有30%的低剖面。

网络和HPC
对于高性能计算和网络应用,台积电在基板和内存上提供CoWoS和信息。
CoWoS可以扩展到2个具有0.4μm/0.4μm侵略性线/空间的标线。这是一项非常成熟的技术,已经批量生产超过五年。CoWoS已广泛用于GPU,但也可以在各种网络应用程序中找到。台积电表示,到目前为止,他们已经进行了15次以上的测试。
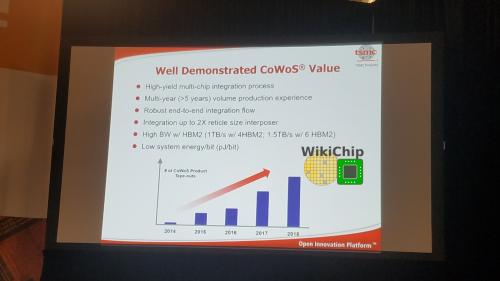
目前,CoWoS支持高达1.5 TB/s和6个HBM2模块。台积电报告正在研究更高带宽的解决方案,及超过3个网格的更大硅片。

对于网络应用,它在基板上提供InFO,可以达到最多1个网格的集成Si区域,但具有1.5μm/1.5μm的略微更宽松的L / S间距。当前的技术特点是最小I/O间距为40μm,最小C4凸起间距为130μm。InFO_oS的产量在2018年第二季度大幅上升。台积电目前正致力于集成两个以上的芯片,以及1.5x网格大小的硅区域。


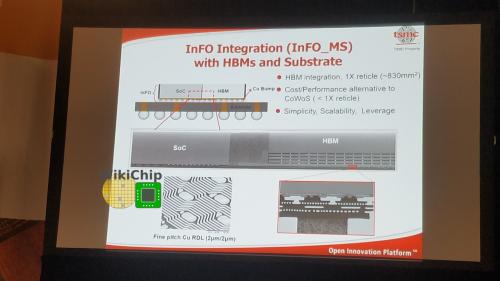
对于AI应用程序和类似的工作负载,台积电在基片上设计了与HBM集成的InFO。这项技术目前的特点是RDL L/S为2μm/2μm,仅限于一个单独的网线。在许多方面,台积电向InFO_MS收费是对CoWoS的性能成本敏感的替代方案。
InFO超高密度(InFO_UHD)
驱动性能和功率的两个关键参数是写入密度和凸点间距。这是InFO超高密度封装背后的目标。据报道,台积电已经公布了500线/ mm的0.8 /0.8μmL/ S,最高可达10000键/mm²。

集成系统芯片(SoIC)
上面描述的一切都是为了SoIC。SoIC是他们下一代的“真正的”3D封装技术,是一种芯片对晶圆的堆叠方法,它允许将许多不同的KGDs堆叠在一起进行混合和匹配集成,在大小和流程节点上都有所不同。它既是面对面的,也是面对背的技术。 因为从外部看,它与任何其他标准芯片一样,实际上可以将SOIC与现有技术结合在同一个封装中。与InFO_UHD一样,它目前具有10000个/mm²的,他们认为随着“SoIC +”的推出,最终可以达到100万/mm²。
『本文转载自网络,版权归原作者所有,如有侵权请联系删除』








 热门文章
更多
热门文章
更多

 未来.世界可能就是人工智能说了算了
未来.世界可能就是人工智能说了算了









 APP下载
APP下载 登录
登录







